Yesterday, Alex pointed me to this tweet from Julien Chaumond, CTO of Huggingface:
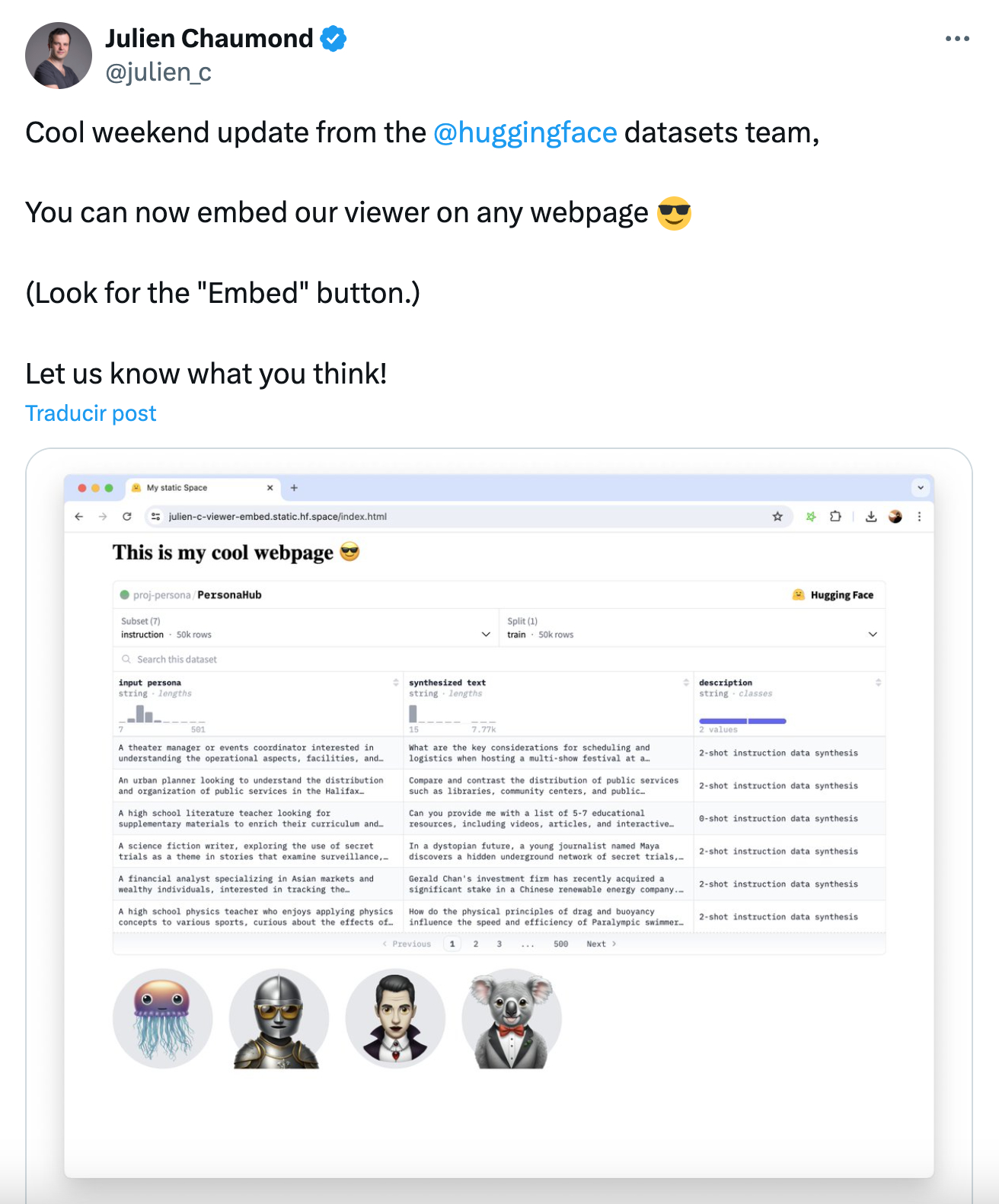
We instantly thought it would be a good idea to embed the visualization in the ZenML dashboard. As the 🤗 Huggingface team already exposed this embedding functionality as a simple iframe, we could easily do this:
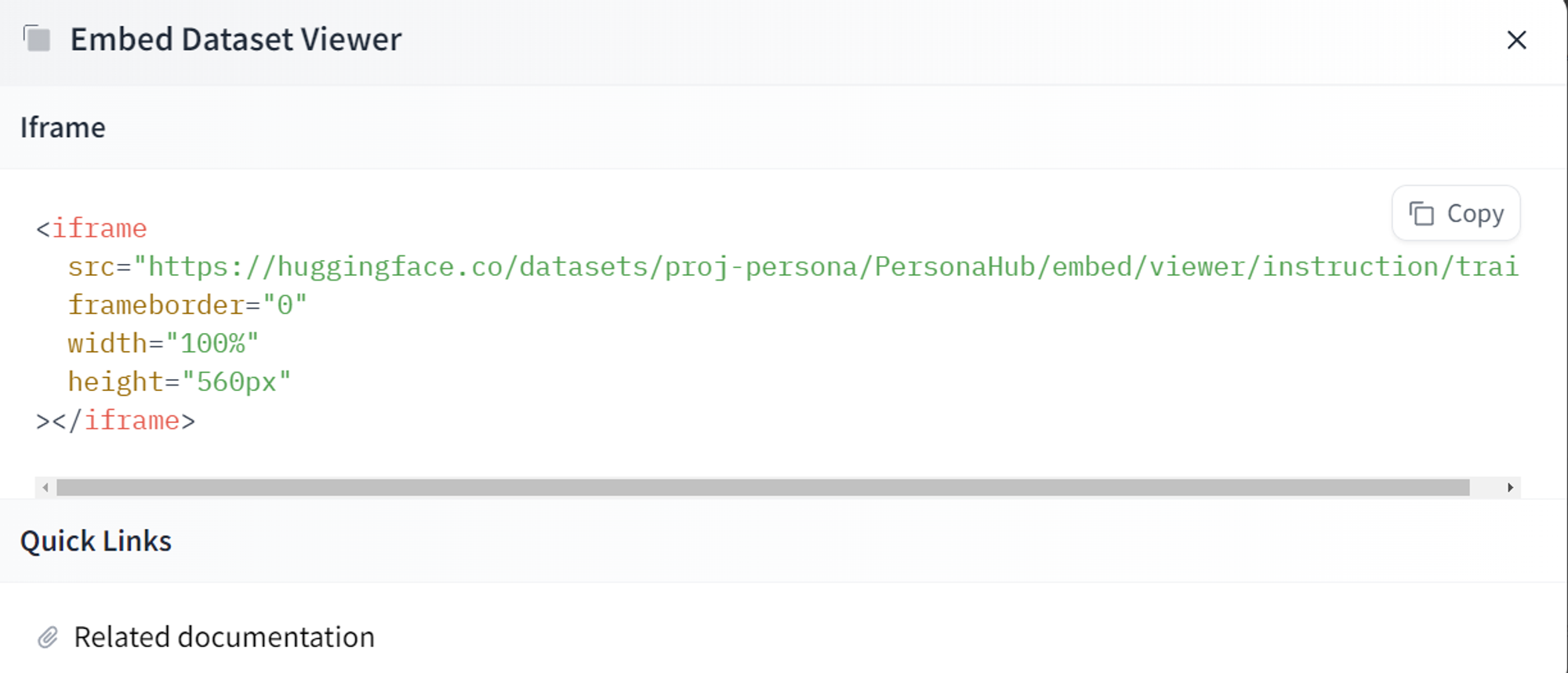
See an example on any 🤗 Huggingface dataset
Within a few hours, we had it reviewed and merged:
🏃 Custom visualizations in ZenML
In ZenML, there is a concept known as a materializer, that takes care of persisting objects to and from artifact storage. The interface is quite simple, and optionally includes a function where users can attach custom visualizations:
class BaseMaterializer(metaclass=BaseMaterializerMeta):
"""Extend this class and associate your object type."""
# Tuple of types that trigger this materializer
ASSOCIATED_TYPES = ()
def load(self, data_type: Type[Any]) -> Any:
"""Write logic here to load the data of an artifact."""
...
def save(self, data: Any) -> None:
"""Write logic here to save the data of an artifact."""
def save_visualizations(self, data: Any) -> Dict[str, VisualizationType]:
"""Save visualizations of the given data."""
"""The materializer interface is extensible, and it’s easy to make custom ones by adding a class to your codebase. For 🤗 Huggingface datasets, there is already a standard materializer that takes care of reading and writing a dataset to and from storage. All that needed to be done was to implement the save_visualizations function.
📢 Note, there are other ways to create custom visualizations in ZenML, but this was the simplest in this case
The save_visualizations function expects us to return a dictionary of key-value pairs, where the key is where the visualization file is stored, and the value is the type of file that we persist. ZenML already supports HTML file types, so the logic was fairly simple. Here is the implementation:
def save_visualizations(
self, ds: Union[Dataset, DatasetDict]
) -> Dict[str, VisualizationType]:
"""Save visualizations for a Huggingface dataset."""
visualizations = {}
if isinstance(ds, Dataset):
datasets = {"default": ds}
elif isinstance(ds, DatasetDict):
datasets = ds
else:
raise ValueError(f"Unsupported type {type(ds)}")
for name, dataset in datasets.items():
# Generate a unique identifier for the dataset
if dataset.info.download_checksums:
dataset_id = extract_repo_name(
[x for x in dataset.info.download_checksums.keys()][0]
)
if dataset_id:
# Create the iframe HTML
html = f"""
<iframe
src="https://huggingface.co/datasets/{dataset_id}/embed/viewer"
frameBorder="0"
width="100%"
height="560px"
></iframe>
"""
# Save the HTML to a file
visualization_path = os.path.join(
self.uri, f"{name}_viewer.html"
)
with fileio.open(visualization_path, "w") as f:
f.write(html)
visualizations[visualization_path] = VisualizationType.HTML
return visualizationsYou can see the full implementation materializer implementation here.
And that’s that! Now by returning any 🤗 Huggingface dataset from a ZenML step in a pipeline, the materializer would also embed the viewer within the ZenML dashboard viewer.
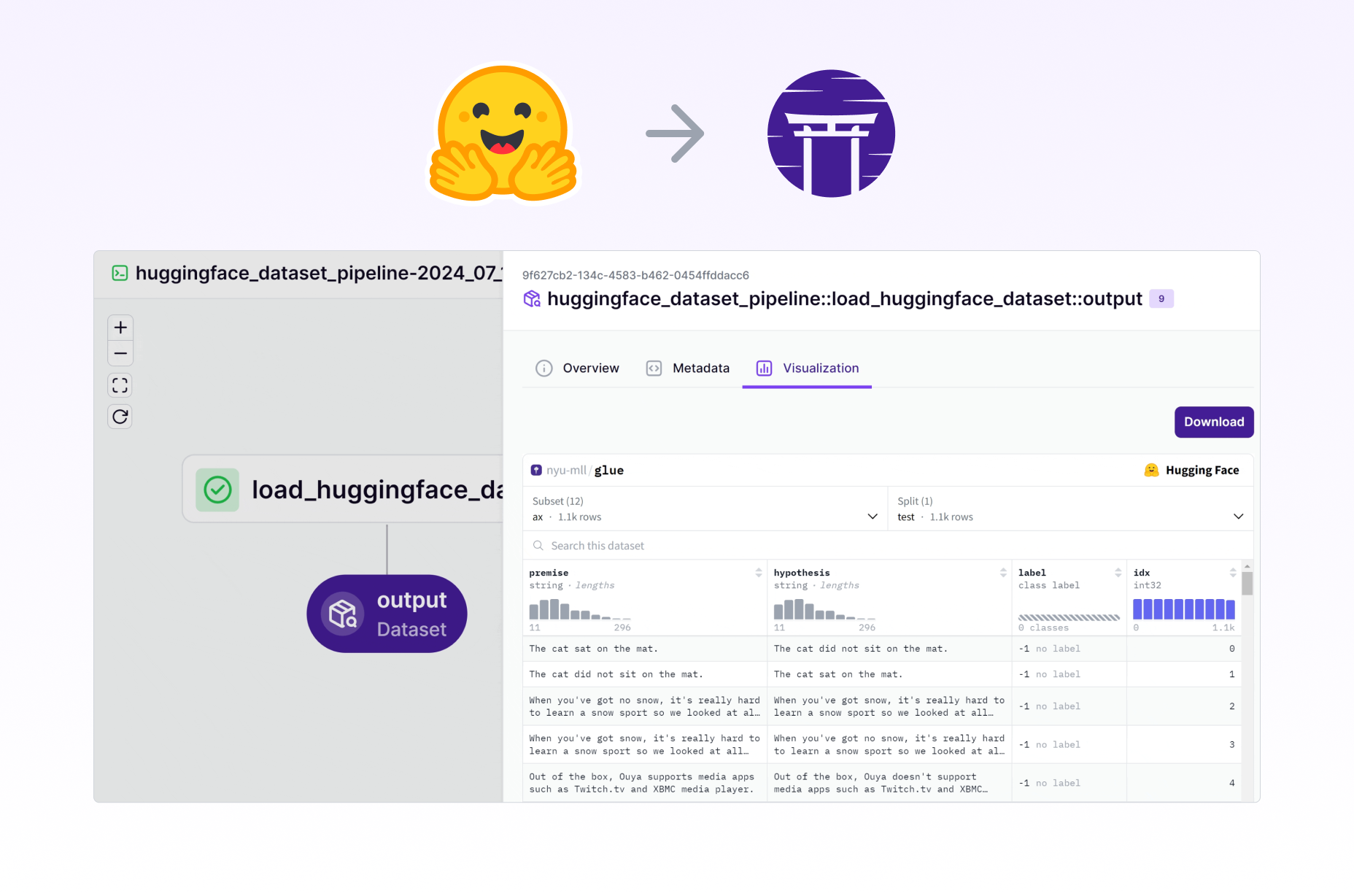
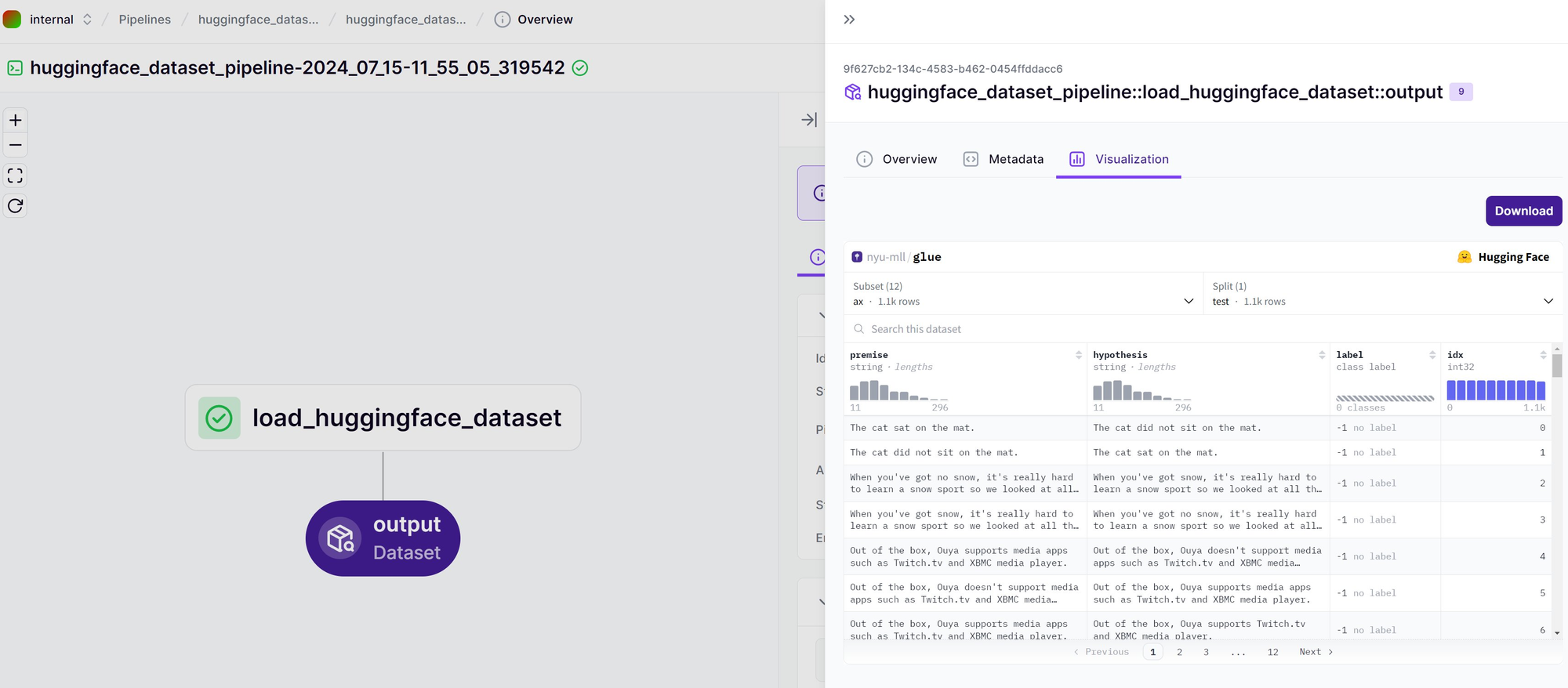
How to embed a 🤗 dataset view in ZenML
Here is a simple example in action that embeds the glue dataset:
from zenml import pipeline, step
from datasets import load_dataset
from datasets import Dataset
from zenml.integrations.huggingface.materializers.huggingface_datasets_materializer import HFDatasetMaterializer
@step(enable_cache=False, output_materializers=HFDatasetMaterializer)
def load_huggingface_dataset() -> Dataset:
# Load a sample dataset from Hugging Face
dataset = load_dataset("nyu-mll/glue", split="train")
return dataset
@pipeline
def huggingface_dataset_pipeline():
dataset = load_huggingface_dataset()
if __name__ == "__main__":
# Run the pipeline
huggingface_dataset_pipeline()Run the above from version 0.62.0 onwards, and you’ll see the following in the ZenML dashboard:
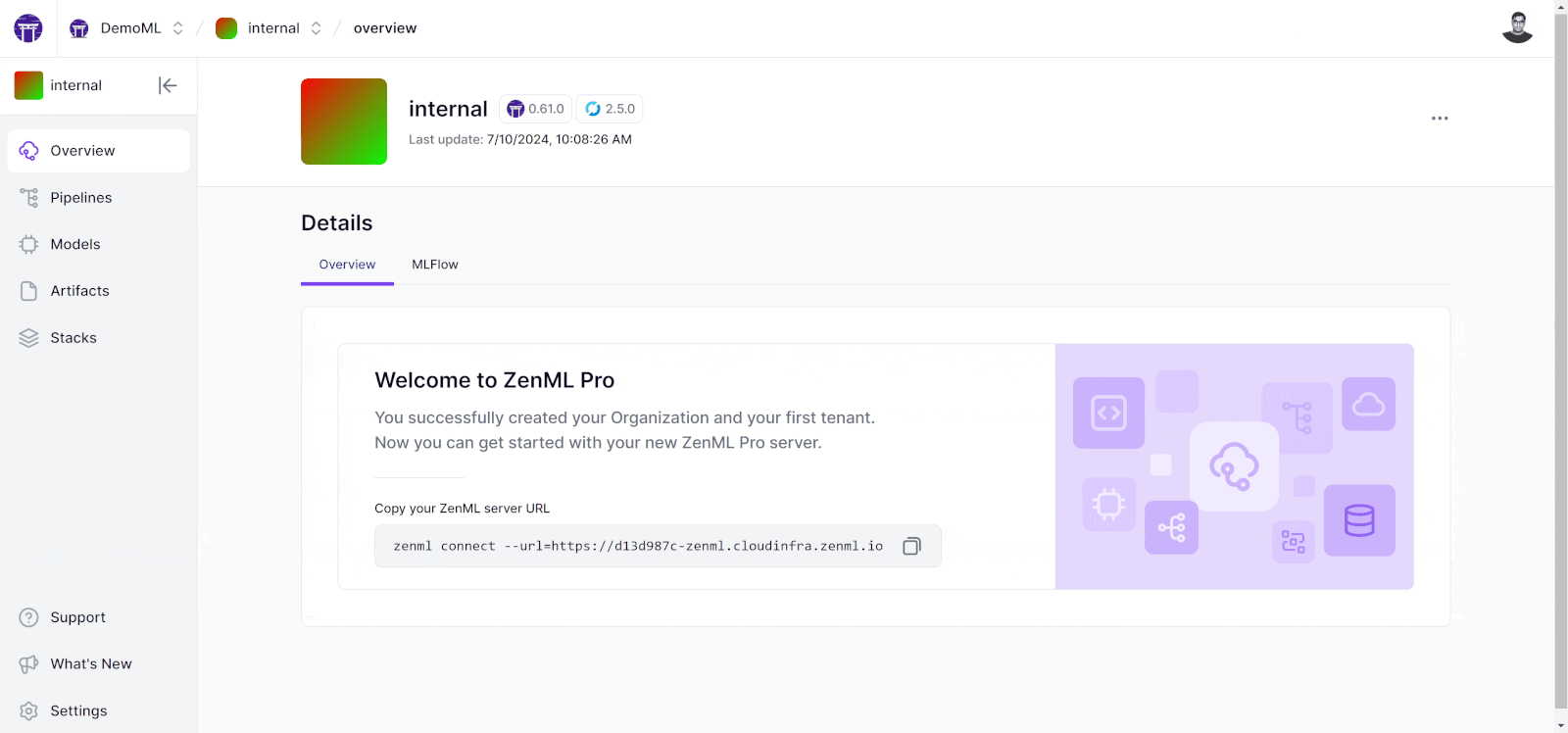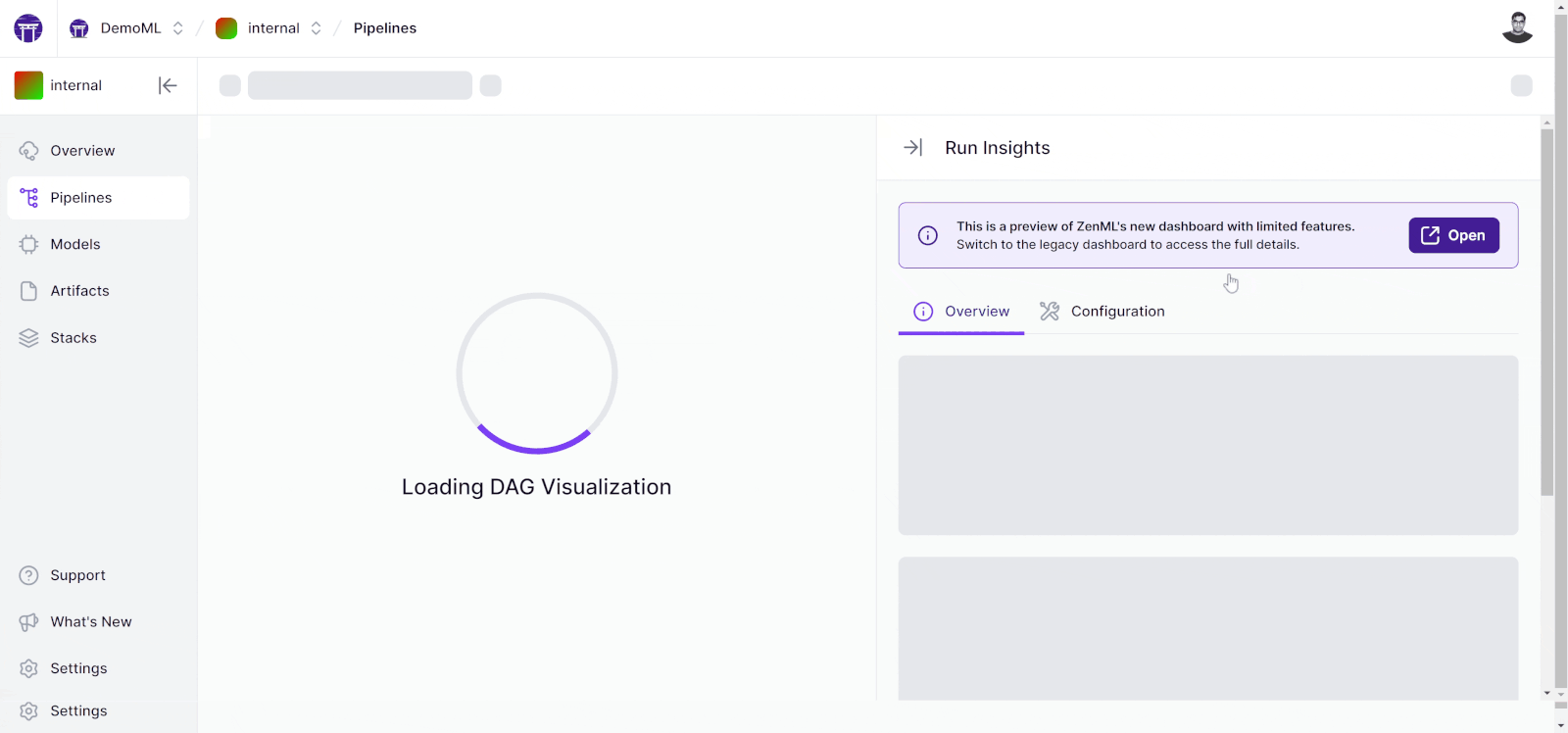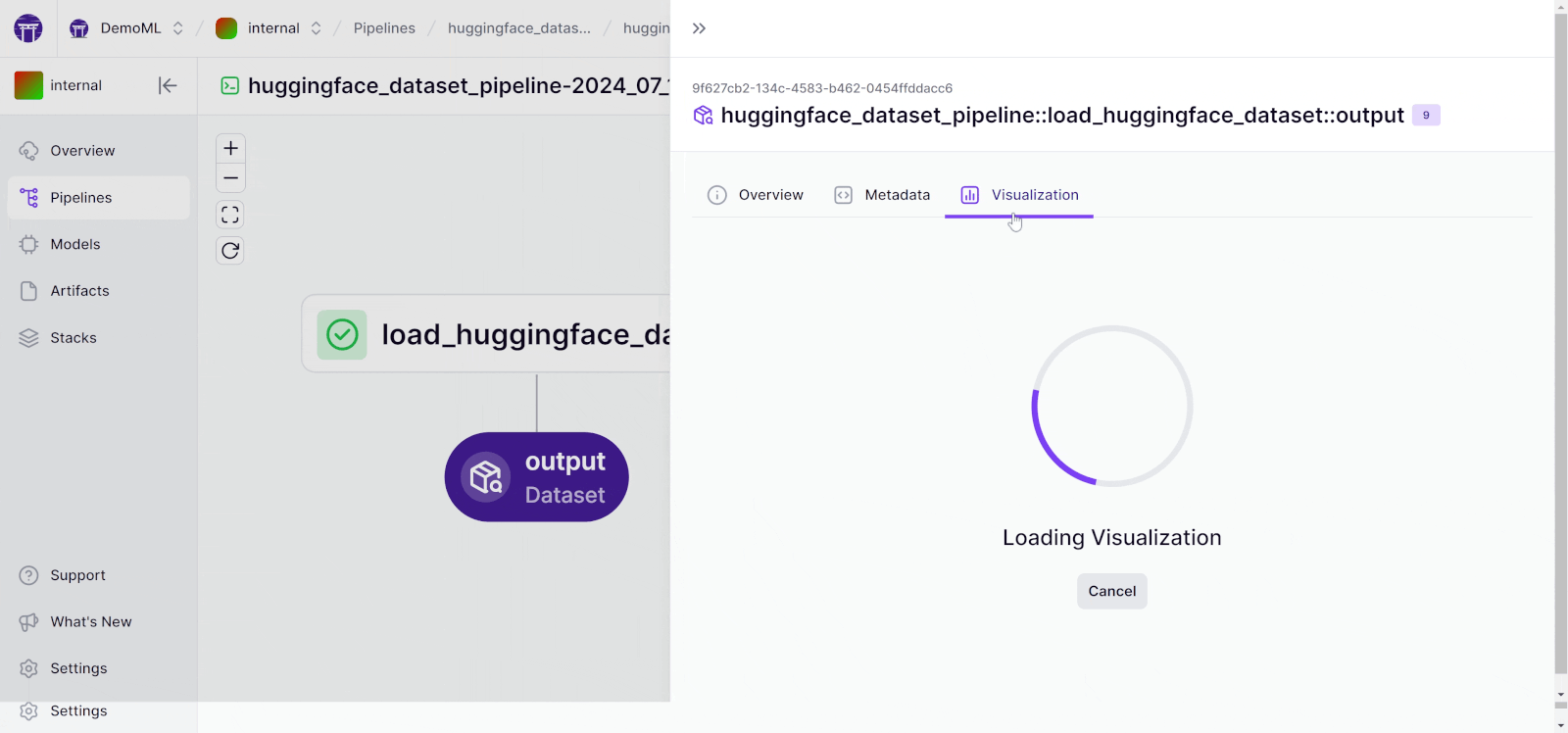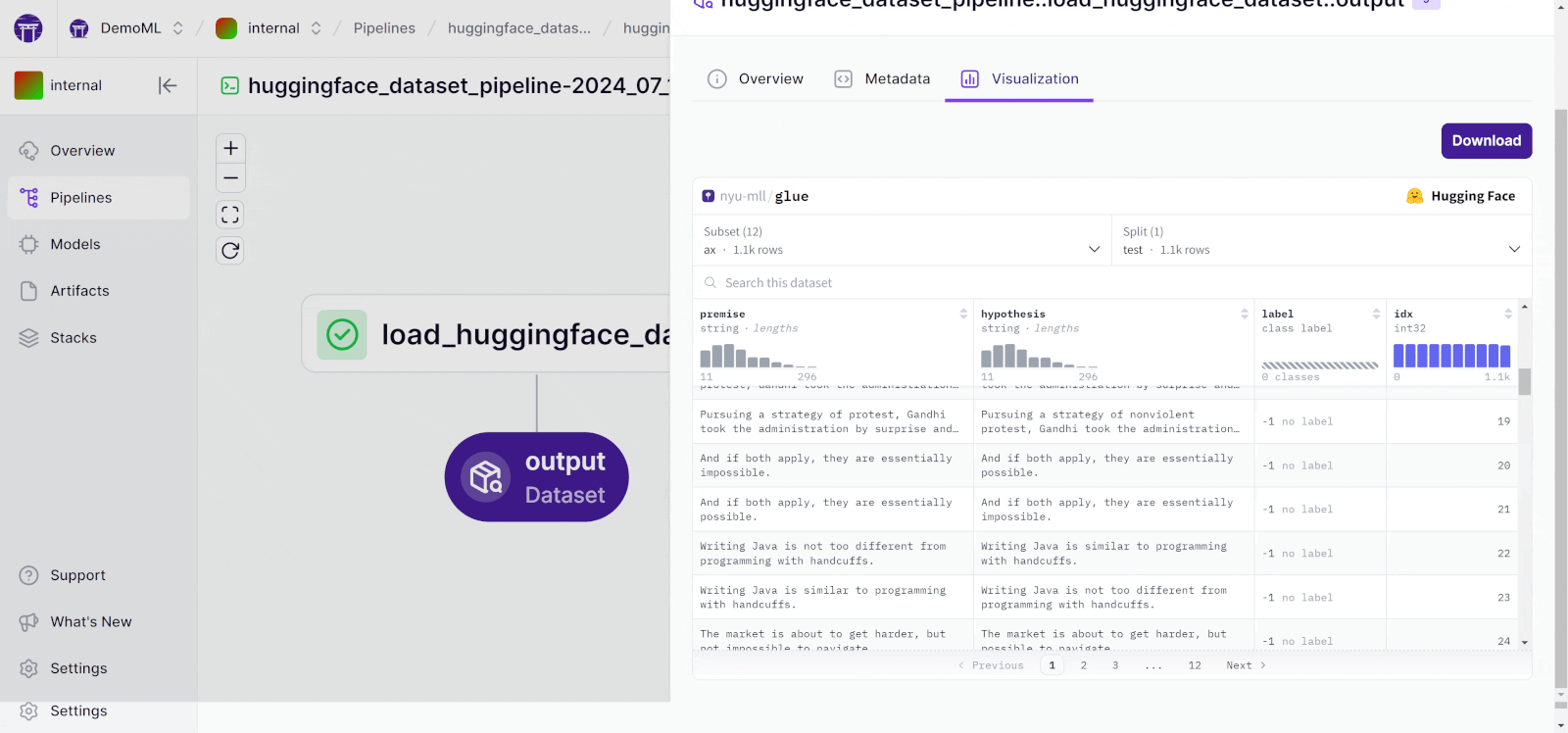
This was a fun two hours to spend on this relatively simple but hopefully popular enhancement to the ZenML Huggingface integration. Give us a star if you like it, or say hi on Slack! Till next time.