Compare ZenML vs
Orchestrate Your Data Pipelines with Ease
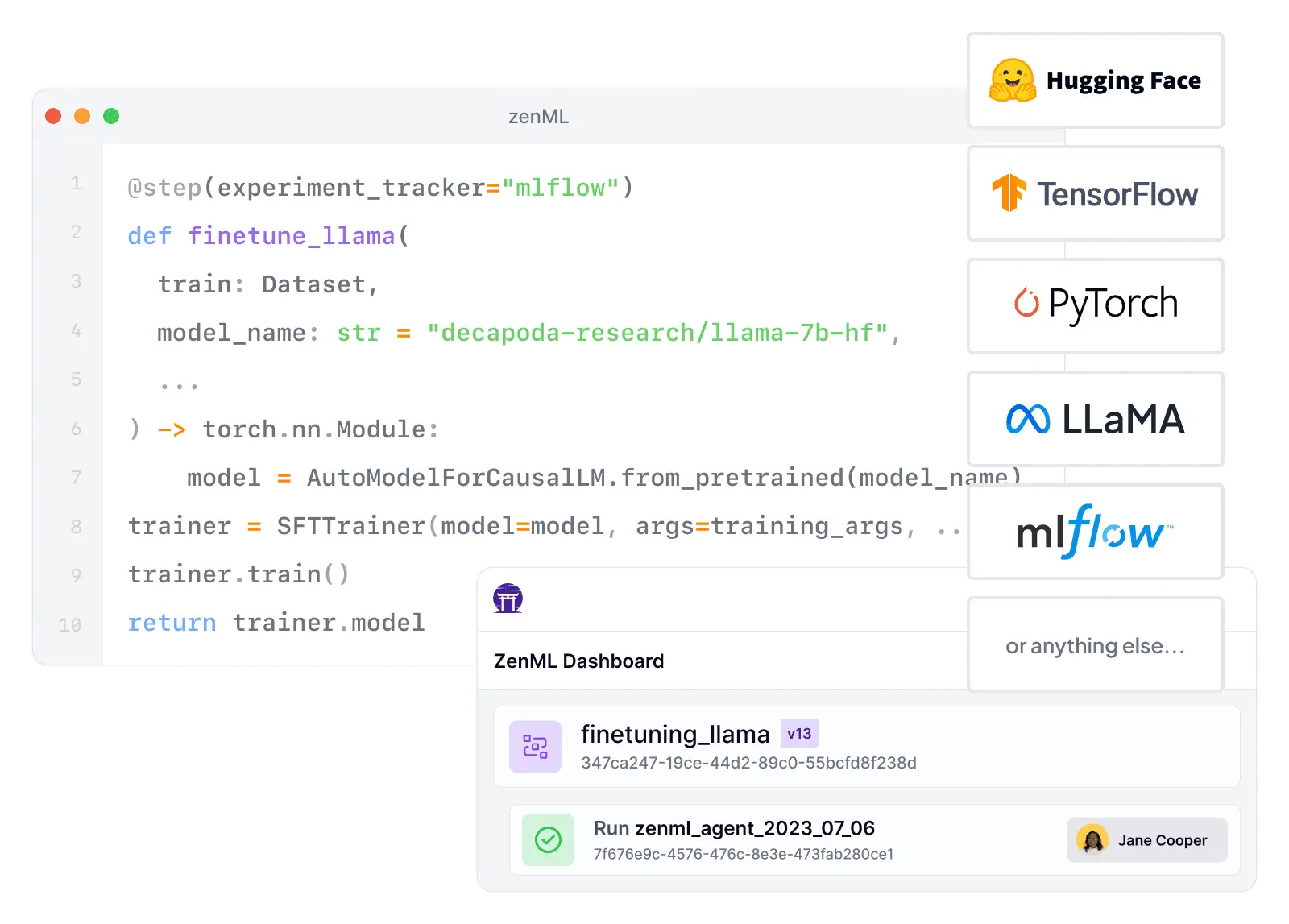
Discover how ZenML stacks up against Dagster in the world of data pipeline orchestration. While Dagster offers a flexible, open-source platform for building and managing data pipelines, ZenML provides a more specialized solution focused on machine learning workflows. Compare ZenML's ML-centric features and integrations with Dagster's general-purpose pipeline orchestration capabilities. Learn how ZenML can streamline your ML operations with its intuitive pipeline definition, built-in experiment tracking, and seamless integration with popular ML frameworks, while Dagster caters to a broader range of data engineering and ETL use cases.