

Don't make Claude do the same work twice
Claude Agent SDK runs the agent loop. Kitaru adds the durable runtime around a completed invocation — checkpointed results, artifacts, replay boundaries, and waits.
This article contrasts ZenML and Airflow to emphasize which platform aligns best with your requirements for scalability, user-friendliness, and comprehensive functionality. Uncover the primary distinctions that will optimize your ML workflows and accelerate your project progress.

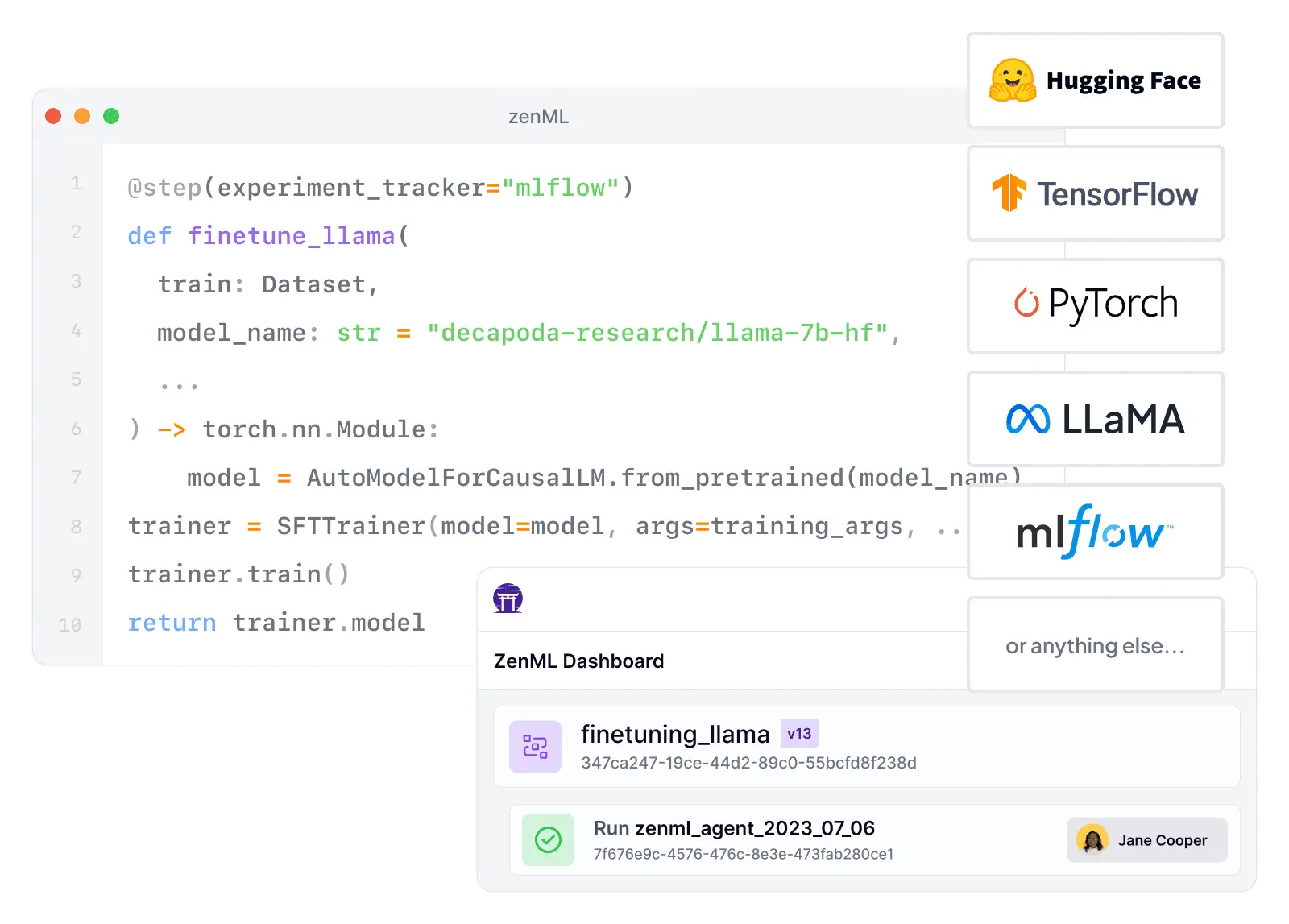

“ZenML allows orchestrating ML pipelines independent of any infrastructure or tooling choices. ML teams can free their minds of tooling FOMO from the fast-moving MLOps space, with the simple and extensible ZenML interface. No more vendor lock-in, or massive switching costs!”

Richard Socher
Former Chief Scientist Salesforce and Founder of You.com

Feature-by-feature comparison
| ML Experiment Tracking | Built-in experiment tracking tailored for ML workflows | Limited native experiment tracking, often requires third-party tools |
| Data Versioning | Native data versioning for reproducibility and lineage | Limited built-in data versioning capabilities |
| ML Deployment | Streamlined deployment of ML models to production | Deployment of ML models can be complex, requiring additional setup |
| Integration Flexibility | Seamless integration with ML frameworks and tools out-of-the-box | Flexible but may require more setup for ML-specific tools |
| ML-Centric Design | Purpose-built for machine learning projects end-to-end | General purpose workflow orchestration, not ML-native |
| Scalability | Designed to scale ML workloads with minimal overhead | Scalable, but may require additional setup and configuration |
| Collaboration | Collaborative features tailored for ML teams | Basic collaboration through shared repositories and workflows |
Code comparison
# ZenML pipeline syntax
from zenml import pipeline, step
@step
def data_preprocessing(data):
... # preprocessing logic
@step
def model_training(preprocessed_data):
... # model training logic
@pipeline
def ml_pipeline(data):
preprocessed_data = data_preprocessing(data)
trained_model = model_training(preprocessed_data)
return trained_model# Airflow DAG syntax
from airflow import DAG
from airflow.operators.python import PythonOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2023, 1, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
def data_preprocessing(**kwargs):
... # preprocessing logic
def model_training(**kwargs):
... # model training logic
with DAG('ml_pipeline', default_args=default_args, schedule_interval=timedelta(days=1)) as dag:
preprocess_task = PythonOperator(
task_id='preprocess_data',
python_callable=data_preprocessing,
)
train_model_task = PythonOperator(
task_id='train_model',
python_callable=model_training,
)
preprocess_task >> train_model_task
ZenML guarantees swifter initialization, surpassing orchestrators for prompt, optimized ML workflows.

ZenML is a native interface to the whole end-to-end machine learning lifecycle, taking you beyond just orchestration.

ZenML excels with dedicated support, offering personalized assistance beyond standard orchestrators.
Expand Your Knowledge
Claude Agent SDK runs the agent loop. Kitaru adds the durable runtime around a completed invocation — checkpointed results, artifacts, replay boundaries, and waits.

LangGraph keeps graph state, threads, and interrupts. Kitaru adds the durable workflow around the graph call — replay boundaries, durable waits, and inspectable runs.

The OpenAI Agents SDK stays the harness; Kitaru adds the runtime around it — durable workflow waits, replay boundaries, and inspectable execution history.
