In 2022, Coles, one of Australia’s largest supermarket chains, faced a significant challenge in managing its vast inventory across over 800 stores nationwide. With millions of products and constantly changing consumer demands, Coles needed a robust solution to optimize stock levels and reduce waste. They turned to Databricks to implement an advanced demand forecasting system using machine learning. The result? A 30% improvement in demand forecasting accuracy, significant reductions in food waste, and a scalable system capable of processing massive amounts of data daily. This success story underscores the transformative potential of integrating MLOps practices with Databricks.
Much like Coles’ achievement in inventory management, the landscape of Large Language Models (LLMs) presents its own set of challenges and opportunities. As organizations increasingly turn to LLMs to power their AI-driven initiatives, the need for streamlined development, fine-tuning, and deployment processes becomes critical. This is where the integration of ZenML with Databricks comes into play. In this article, we will explore how combining ZenML’s pipeline orchestration with Databricks’ scalable compute and MLflow integration can revolutionize your LLM workflows. Using the fine-tuning of the Llama 3.1 model as our example, we’ll guide you through a workflow that empowers data scientists and ML engineers to deliver production-ready, reproducible results with ease.
The Power of ZenML and Databricks Integration
ZenML is an extensible, open-source MLOps framework designed to streamline the development and production of machine learning pipelines. It offers robust version control, ensures reproducibility, and seamlessly integrates with various tools and platforms in the ML ecosystem. On the other hand, Databricks provides a unified platform for data analytics and machine learning, offering scalable compute resources and integrated tools like MLflow for experiment tracking and model management and model deployment.
The synergy between these platforms is particularly powerful for LLM development:
- 🚀 Scalability: Databricks' distributed computing capabilities allow for efficient processing of large datasets and training of resource-intensive models with GPU's offering.
- 🔄 Reproducibility: ZenML's pipeline orchestration ensures that complex workflows are version-controlled and easily reproducible.
- 🧩 Flexibility: The integration supports various ML frameworks and libraries, allowing data scientists to use their preferred tools.
- 🤝 Collaboration: Databricks' collaborative notebooks and ZenML's shareable pipelines foster team collaboration and knowledge sharing.
- 🔁 End-to-end MLOps: From data preparation to model deployment, the integration covers the entire ML lifecycle.
Setting Up the Integration
To harness the power of ZenML and Databricks for your LLM projects, you’ll need to set up the integration. Follow these steps to get started:
- Install the ZenML Databricks integration: First, ensure you have ZenML installed in your environment. Then, run the following command to install the Databricks integration:
zenml integration install databricks -y- Configure Databricks authentication: You'll need to set up authentication to connect ZenML with your Databricks workspace. Databricks supports various authentication methods, but for this example, we'll use token-based authentication. Generate a Databricks access token in your Databricks workspace (User Settings > Access Tokens > Generate New Token).
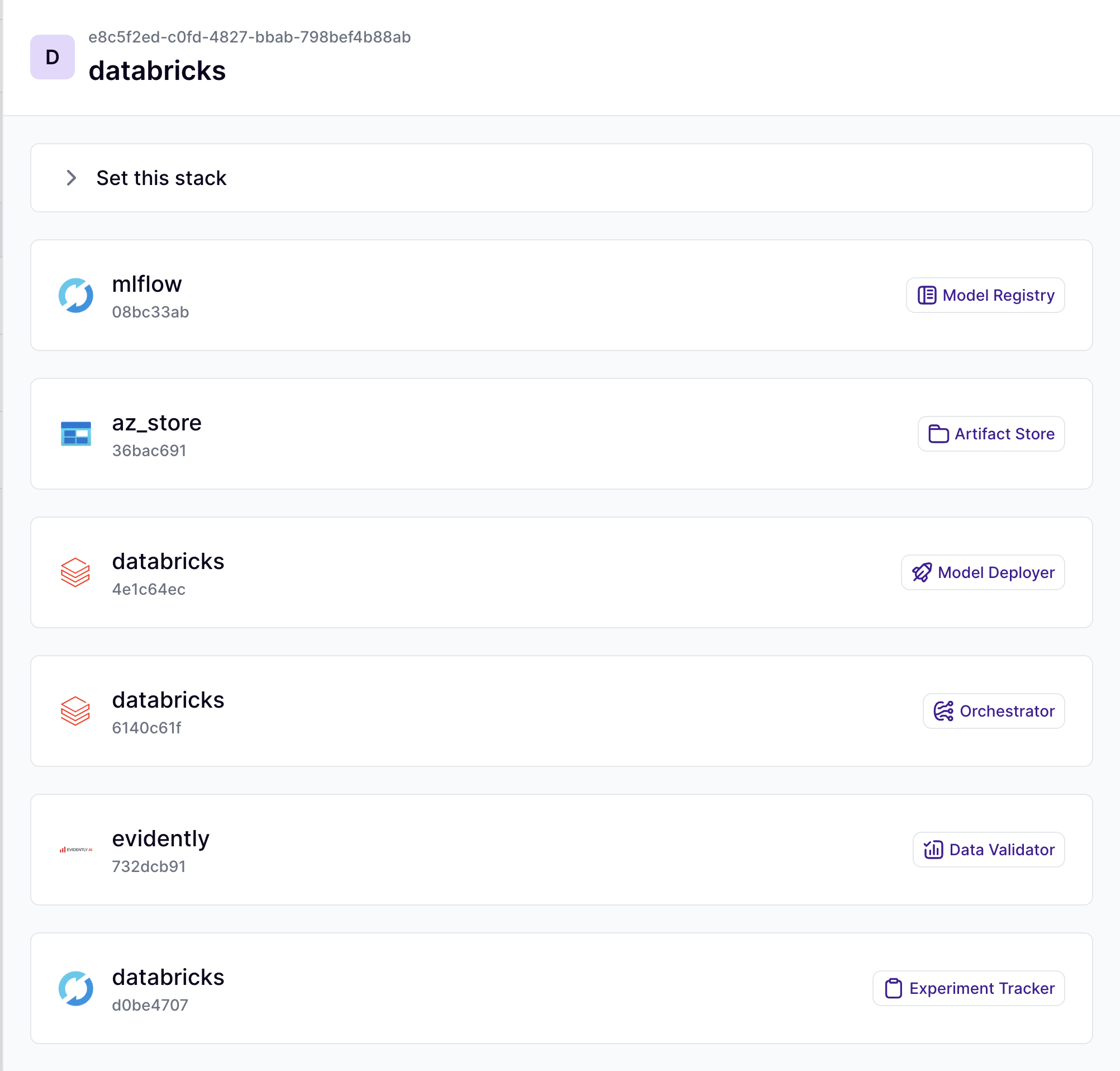
- Register the Databricks orchestrator with ZenML: Use the following command to register the Databricks orchestrator, replacing the placeholders with your actual Databricks information:
zenml orchestrator register databricks_orchestrator \\
--flavor=databricks \\
--host="<https://your-databricks-instance.cloud.databricks.com>" \\
--client_id="your-client-id" \\
--client_secret="your-client-secret"- Update your ZenML stack: Incorporate the Databricks orchestrator into your ZenML stack:
zenml stack update llm_stack -o databricks_orchestrator --set- Configure Databricks cluster settings: You can customize the Databricks cluster settings for your LLM workflows. Create a DatabricksOrchestratorSettings object in your Python code:
from zenml.integrations.databricks.flavors.databricks_orchestrator_flavor import DatabricksOrchestratorSettings
databricks_settings = DatabricksOrchestratorSettings(
spark_version="15.3.x-gpu-mlscala2.12",
node_type_id="Standard_NC24ads_A100_v4",
autoscale=(0,1),
)This configuration sets up a GPU-enabled cluster (A group of computers with specialized graphics processing units for faster ML model training) suitable for LLM fine-tuning.
With these steps completed, you’re ready to leverage the combined power of ZenML and Databricks for your LLM projects.
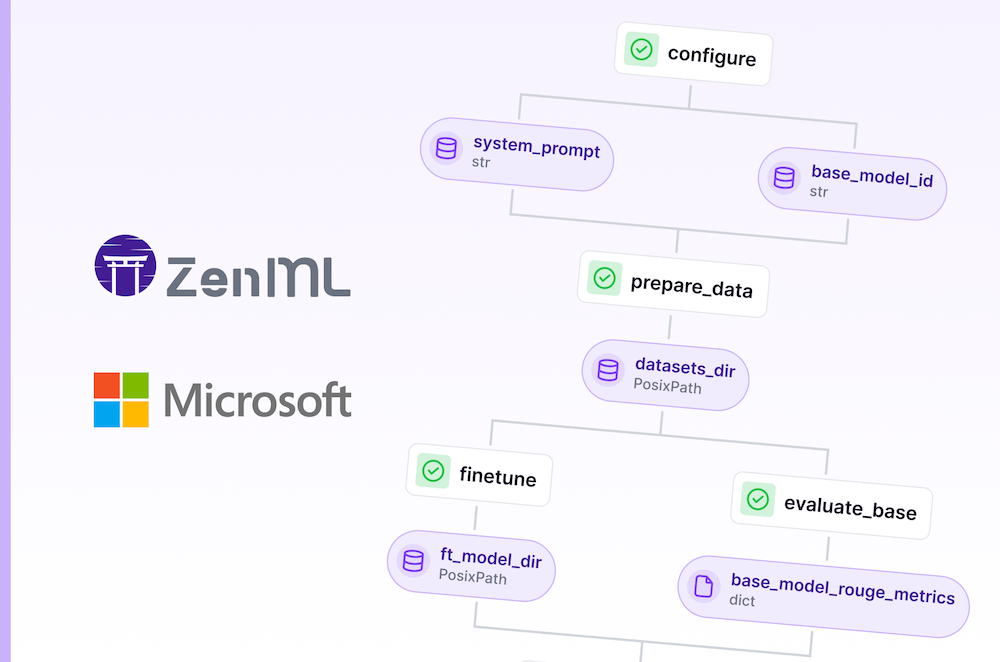
Now that we have our environment set up, let’s design a ZenML pipeline for fine-tuning the Llama 3.1 model. Our pipeline will consist of several key steps:
- Data Preparation
- Model Fine-tuning
- Evaluation
- Model Merging and Logging
Here’s a Python implementation of our pipeline:
from zenml import pipeline, step
from zenml.integrations.databricks.flavors.databricks_orchestrator_flavor import DatabricksOrchestratorSettings
@step
def prepare_data(base_model_id: str, system_prompt: str):
# Implementation for data preparation
...
return datasets_dir
@step
def finetune(base_model_id: str, datasets_dir: str, load_in_8bit: bool = False, load_in_4bit: bool = False):
# Implementation for model fine-tuning
...
return ft_model_dir
@step
def evaluate_model(base_model_id: str, system_prompt: str, datasets_dir: str, ft_model_dir: str, load_in_8bit: bool = False, load_in_4bit: bool = False):
# Implementation for model evaluation
...
return evaluation_results
@step
def merge_and_log_model(base_model_id: str, ft_model_dir: str):
# Implementation for merging and logging the model
...
return merged_model_dir
@pipeline(settings={"orchestrator.databricks": databricks_settings})
def llm_peft_full_finetune(
system_prompt: str,
base_model_id: str,
load_in_8bit: bool = False,
load_in_4bit: bool = False,
):
datasets_dir = prepare_data(base_model_id=base_model_id, system_prompt=system_prompt)
ft_model_dir = finetune(base_model_id, datasets_dir, load_in_8bit=load_in_8bit, load_in_4bit=load_in_4bit)
evaluation_results = evaluate_model(
base_model_id,
system_prompt,
datasets_dir,
ft_model_dir,
load_in_8bit=load_in_8bit,
load_in_4bit=load_in_4bit,
)
merged_model_dir = merge_and_log_model(base_model_id=base_model_id, ft_model_dir=ft_model_dir)This pipeline structure ensures that each step is executed in the correct order, with dependencies clearly defined. ZenML handles the orchestration, ensuring that the pipeline runs seamlessly on the Databricks infrastructure.
The databricks_settings object we created earlier is passed to the pipeline, configuring it to run on our GPU-enabled Databricks cluster. This allows us to leverage Databricks’ powerful computing resources for the resource-intensive task of fine-tuning an LLM.
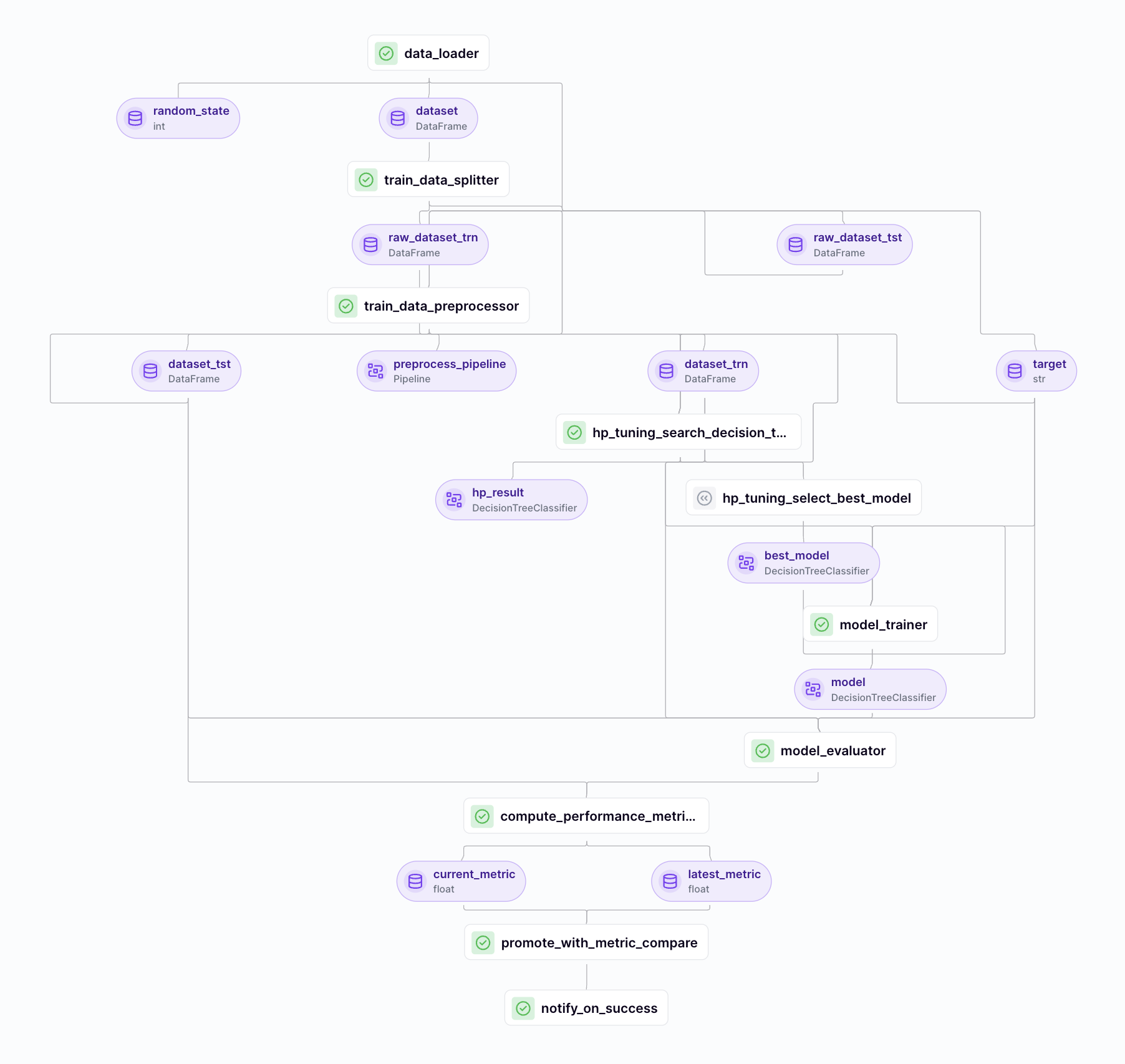
Running the Pipeline on Databricks
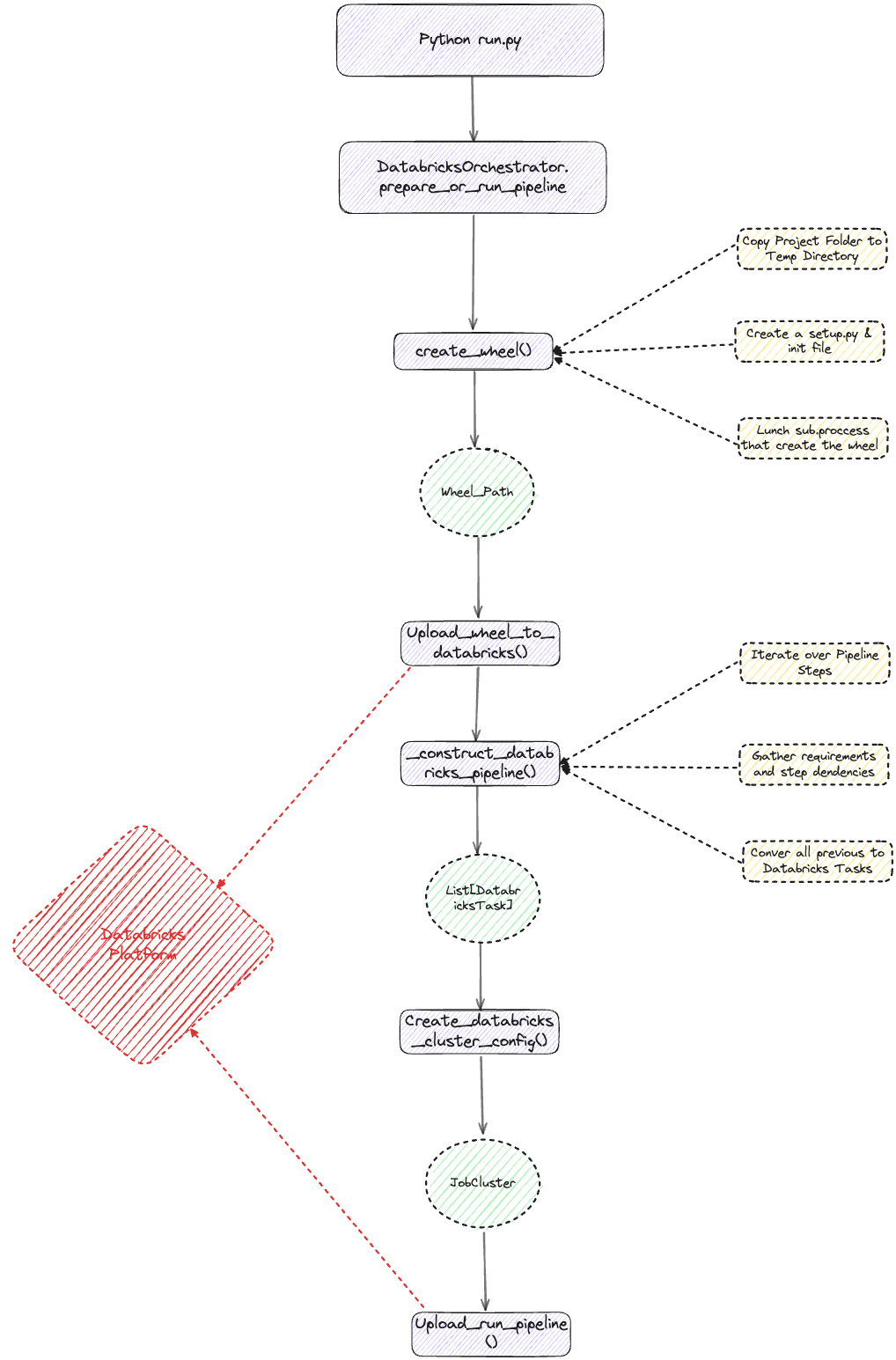
With our pipeline defined, we can now execute it on Databricks. ZenML abstracts away much of the complexity involved in submitting and managing jobs on Databricks. Here’s how you can run the pipeline:
from zenml.client import Client
client = Client()
pipeline_instance = client.get_pipeline_by_name("llm_peft_full_finetune")
pipeline_instance.run(
base_model_id="meta-llama/Llama-2-7b-hf",
system_prompt="You are a helpful AI assistant.",
load_in_8bit=True
)When you execute this code, ZenML performs several actions behind the scenes:
- Code Packaging: ZenML creates a Python wheel package of your project, including all necessary dependencies.
- Databricks Job Creation: Using the Databricks SDK, ZenML creates a job definition on your Databricks workspace. This job includes information about the pipeline steps and their dependencies.
- Execution: The job is submitted to Databricks for execution. Each step of your pipeline runs as a separate task within the Databricks job.
- Monitoring: You can monitor the progress of your pipeline directly in the Databricks UI. ZenML provides links to the Databricks job for easy access.
- Results Retrieval: Once the job is completed, ZenML retrieves the results and updates the pipeline run information in its own database.
This process allows you to leverage Databricks’ distributed computing capabilities while maintaining the simplicity and reproducibility of ZenML pipelines. The GPU-enabled cluster we configured earlier ensures that the resource-intensive fine-tuning process can be completed efficiently.
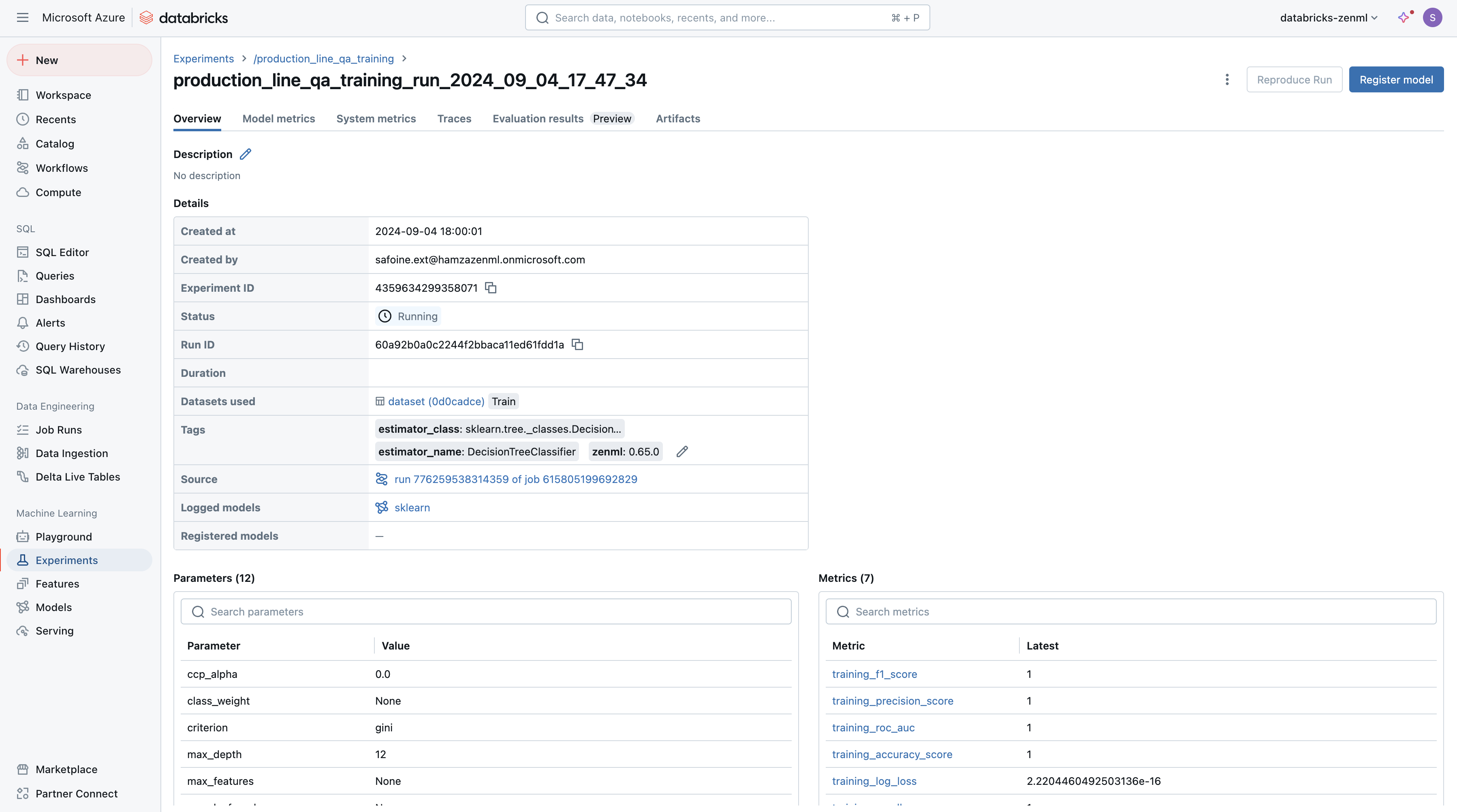
One of the key benefits of the ZenML-Databricks integration is seamless model tracking and registration using MLflow. As your pipeline runs, ZenML automatically logs metrics, parameters, and artifacts to MLflow, which is natively integrated with Databricks.
To access the MLflow experiment associated with your pipeline run, you can use the following code:
from zenml.client import Client
client = Client()
run = client.get_pipeline_run("your-run-name")
mlflow_run_id = run.run_metadata["mlflow_run_id"].value
print(f"MLflow Run ID: {mlflow_run_id}")With this MLflow run ID, you can easily access all the logged information in the Databricks MLflow UI, including model performance metrics, hyperparameters, and the model itself.
For model registration, ZenML provides a convenient way to promote your model to the MLflow Model Registry:
from zenml.integrations.mlflow.model_deployers import MLFlowModelDeployer
model_deployer = MLFlowModelDeployer.get_active_model_deployer()
model_deployer.promote_model(
"llama-3-1-finetuned",
pipeline_name="llm_peft_full_finetune",
step_name="merge_and_log_model",
model_stages=["Production"]
)This integration ensures that your fine-tuned LLM is properly versioned and easily accessible for deployment.
With our Llama 3.1 model fine-tuned, evaluated, and registered, the final step is deployment. Databricks offers several options for model deployment, including Databricks Model Serving and MLflow Model Serving. ZenML can facilitate this process, making it easy to deploy your fine-tuned LLM.
Here’s an example of how you might deploy your model using ZenML and Databricks:
from zenml.integrations.mlflow.services import MLFlowDeploymentService
deployment_service = MLFlowDeploymentService(
name="llama-3-1-chatbot",
model_name="llama-3-1-finetuned",
model_uri="models:/llama-3-1-finetuned/Production"
)
deployment_service.start()
print(f"Model deployed and serving at: {deployment_service.prediction_url}")This code snippet creates a deployment service for your model and starts it, making your fine-tuned Llama 3.1 model available for inference.
Databricks Model Serving provides a scalable and managed solution for deploying your model, handling aspects such as load balancing, auto-scaling, and monitoring. By leveraging this service through ZenML, you can ensure that your LLM is readily available for use in production environments.
Once your model is deployed, it’s crucial to monitor its performance and iterate as needed. Databricks provides robust monitoring capabilities through MLflow, allowing you to track your model’s performance over time.
You can set up automated monitoring jobs using ZenML pipelines that periodically fetch performance metrics and log them back to MLflow. This creates a feedback loop that helps you identify when it’s time to retrain or fine-tune your model.
For example, you might create a monitoring pipeline that looks like this:
@pipeline
def llm_monitoring_pipeline():
performance_metrics = fetch_model_performance()
log_metrics_to_mlflow(performance_metrics)
if needs_retraining(performance_metrics):
trigger_retraining_pipeline()
# Schedule this pipeline to run daily
Client().activate_stack("databricks_stack")
llm_monitoring_pipeline.run(schedule=Schedule(cron_expression="0 0 * * *"))This approach ensures that your LLM remains up-to-date and continues to perform well over time.
Conclusion
The integration of ZenML and Databricks offers a powerful solution for organizations looking to streamline their LLM development and deployment processes. By combining ZenML’s pipeline orchestration capabilities with Databricks’ scalable compute and MLflow integration, data scientists and ML engineers can focus on innovation while ensuring their workflows remain reproducible and production-ready.
This approach brings several key benefits:
- Scalability: Leverage Databricks' distributed computing power for training and fine-tuning large models.
- Reproducibility: ZenML's pipeline structure ensures consistent and version-controlled workflows.
- Efficiency: Automate and streamline the entire LLM lifecycle, from data preparation to deployment.
- Collaboration: Foster team collaboration through shared pipelines and experiments.
- Monitoring and Iteration: Easily track model performance and iterate on your LLMs.
As the field of AI continues to advance, tools like ZenML and Databricks will play a crucial role in helping organizations stay at the forefront of LLM development and deployment.