On this page
Last updated: November 3, 2022.
ZenML recently added an integration with Evidently, an open-source tool that allows you to monitor your data for drift (among other things). This post showcases the integration along with some of the other parts of Evidently that we like.
At its core, Evidently’s drift detection calculation functions take in a reference data set and compare it with a separate comparison dataset. These are both passed in as Pandas dataframes, though CSV inputs are also possible. ZenML implements this functionality in the form of several standardized steps along with an easy way to use the visualization tools also provided along with Evidently as ‘Dashboards’.
1. Drift is inevitable

If you’re working on any kind of machine learning problem that has an ongoing training loop that takes in new data, you’ll want to guard against drift. Machine learning pipelines are built on top of data inputs, so it is worth checking for drift if you have a model that was trained on a certain distribution of data. The incoming data is something you have less control over and since things often change out in the real world, you should have a plan for knowing when things have shifted. Evidently offers a growing set of features that help you monitor not only data drift but other key aspects like target drift and so on.
2. Monitoring is boring but essential
Monitoring is sometimes left by the wayside when allocating resources and time alongside developing and training a model or even deploying that model for inference. We’ve seen and heard stories of ML models in production that had monitoring thrown in right at the end, mostly as a way of ticking a box.
There are enough examples to help illustrate why this is probably a short-sighted approach, from the way Zillow’s predictive models drifted off course to Microsoft’s chatbot that went down the wrong path. Monitoring — how models perform out on the inference edge of things, whether incoming training data is similar to the data used to train the original model, or even knowing which features are driving prediction accuracy — should be considered an essential part of any machine learning pipeline.
3. Great documentation and visual explanations

Before we started using the tool, we heard about Evidently’s amazing documentation and visual explanations found in their blogposts. If you want to understand the ins and outs of drift detection, or how ML monitoring differs from traditional monitoring, look no further than reading through their blog archive.
It would be easy to just dive deep into a technical explanation of statistical calculation techniques and some math arcana, but Evidently keep it fresh and comprehensible with the strong visual storyline that runs through most of what they put out. Though we don’t have such a heavy visual footprint here at ZenML, their approachable content is a source of inspiration for us and we wish more tools in the space were this well documented.
4. Catch more than just data drift
Evidently is great for catching those moments when your incoming training data starts to really differ from the original data used to train your models, but that’s not the only thing that it can do. You can also get calculations for:
- numerical and categorical target drift — whether the numeric and category predictions generated from your current model are drifting from the original averages based on the original model
- regression, classification and probabilistic classification model performance — analyzes the ways your model is currently behaving, showing error distributions, confusion matrices and class separation quality.
5. Visualizing drift is easy
Evidently provide an easy way to visually inspect the status of their drift or other model performance reports. In our example of how to use our ZenML integration, we compare two separate slices of the same dataset as an easy way to get an idea for how evidently is making the comparison between the two dataframes. We chose the University of Wisconsin breast cancer diagnosis dataset to illustrate how it works. Getting the standard interface steps and the visualizer is an easy import:
# ... other imports
from zenml.integrations.evidently.steps import (
EvidentlyProfileConfig,
EvidentlyProfileStep,
)
from zenml.integrations.evidently.visualizers import EvidentlyVisualizerOnce we’ve created separate steps for importing and processing the diagnosis data, we can create our drift_detector step:
drift_detector = EvidentlyProfileStep(
EvidentlyProfileConfig(
column_mapping=None,
profile_section="datadrift",
)
)There is a little bit more to the example, but this piece suffices to show the creation of the EvidentlyProfileStep. (For the full example, please visit our examples page). Once your pipeline has run, visualizing the output is as simple as passing the Evidently output into our ZenML EvidentlyVisualizer step:
repo = Repository()
pipe = repo.get_pipelines()[-1]
evidently_outputs = pipe.runs[-1].get_step(name="drift_detector")
EvidentlyVisualizer().visualize(evidently_outputs)And you get an informative set of charts to explore relating to your dataset(s):
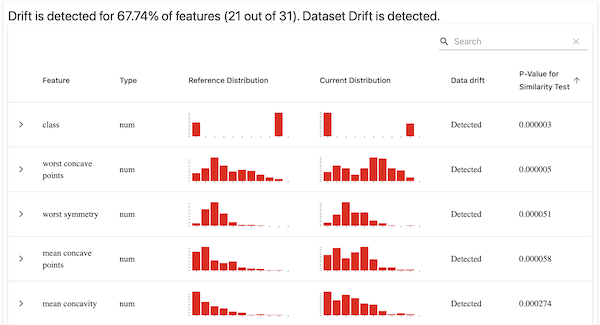
If you’re running this in Jupyter notebooks it’ll display the visualizations in-line, and outside it we’ll generate a temporary file showing the charts and automatically open your browser to display them.
6. Easy-to-use in continuous training
In a production setting, you’re not always going to have a human-in-the-loop. You might want to have a step or fork where depending on whether there’s drift you do one or another action. Looking at diagrams and charts is eminently suited to a human audience, but if you’re passing those conclusions into a subsequent decision step as described above you might want to have the drift calculation outputs in a different format. Luckily, Evidently has you covered again.
You can output the results of this calculation in the form of a JSON object or dictionary (called a Profile in Evidently) which contains all the raw conclusions that their tool has made. You can easily see which features have drifted, and there’s also statistical information provided to be able to make more fine-grained decisions. Indeed, it’s this output that you’ll likely be using in a continuous training setting, where the presence of drift is likely to need something like some retraining of your model or some more intensive involvement and investigation from your data team.
7. Evidently doesn’t get in the way
We’ve all encountered opinionated tools that take up mental and physical space. Evidently is not that. It’s a lightweight approach to solving a non-lightweight problem. It’s refreshing to use a tool that doesn’t try to do everything, but rather to do a few things really well.
8. Evidently is open-source
ZenML has open-source values in its blood and in that way we’re happy to work alongside Evidently in this same machine learning tooling ecosystem. Their development is quite public-facing and they are making regular iterations on the original product and set of features. There are lots of opportunities to get involved and contribute, and the core team actively encourage new issues and bug reports.
9. A kind and responsive community
The community hub for Evidently is their Discord chat where you’ll be welcomed by one of the core team soon after joining. Discussions about support requests or use cases involving Evidently are (in my experience) interesting and you receive quick replies. It takes some effort and time to create a welcoming and responsive community, and it certainly isn’t the norm, so it’s great that Evidently gets this right. I’d encourage you to join their Discord community.
10. Evidently is here to stay
The core team at Evidently is still relatively small, but it’s clear that they’re sticking around. Their 2000+ stars on Github shows that there’s a clear interest in what they’re doing. They took part in the summer 2021 batch of Y Combinator which tells you that they’re serious about what they want to achieve with their tool. Moreover, their core team is growing as they take on bigger use cases and problems to solve.
We really enjoyed creating this integration for Evidently visualizations and statistical drift calculation profiles. The tool is focused and easy to use, and also a perfect example of the way ZenML allows you to easily mix and match tools that allow you to get your work done.
Let us know if you end up using the Evidently <-> ZenML integration in your own projects! We would love to hear any feedback you have about your specific use cases and about any ways we can make it even better. As always, join our Slack to let us know or look at our contributions guide to submit an issue and/or pull request.