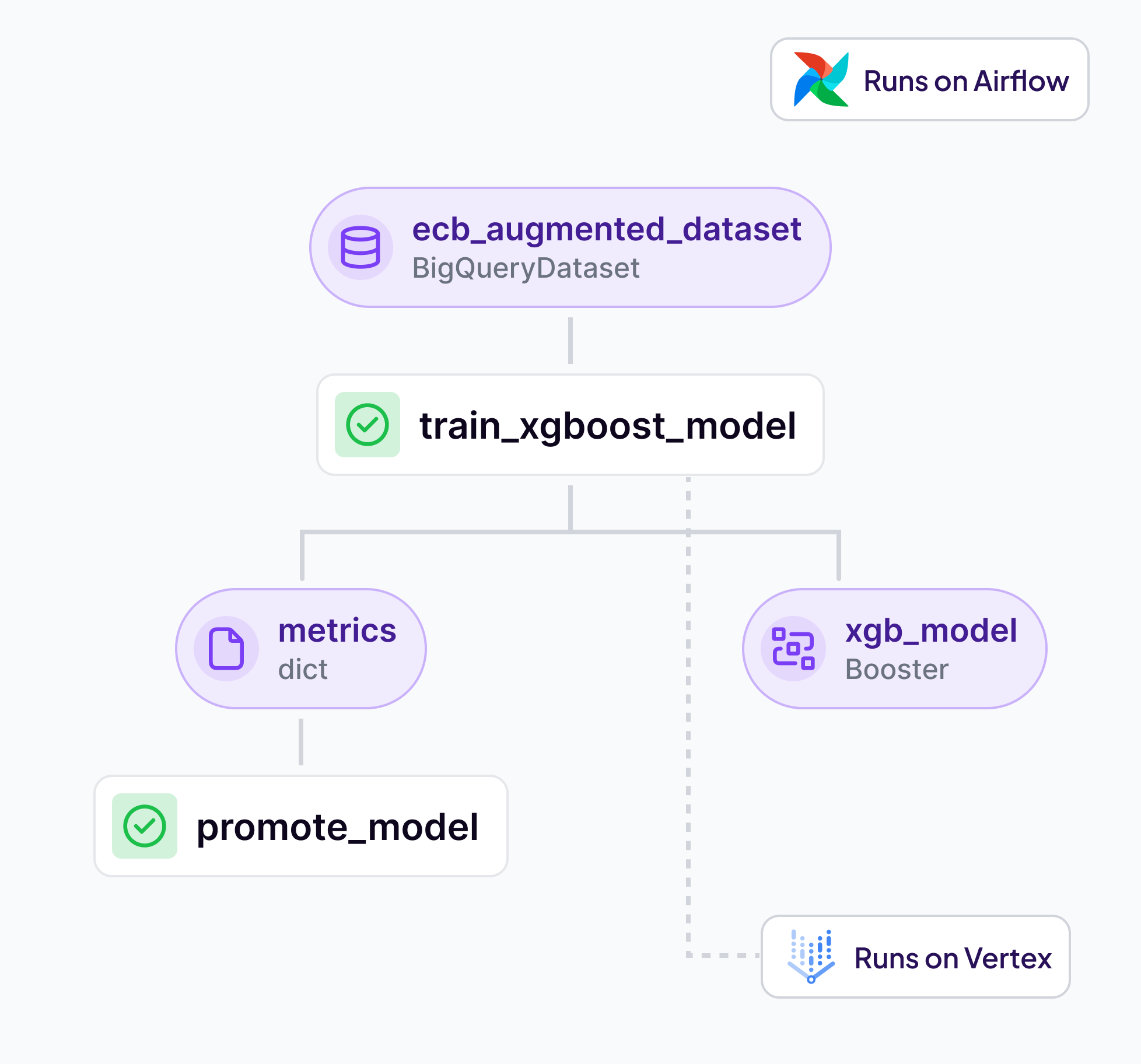
On this page
In today’s rapidly evolving ML landscape, organizations face a common challenge: transitioning from manual, ad-hoc machine learning workflows to scalable, automated MLOps practices. As projects grow from a handful of models to dozens, the complexity of managing training, deployment, and monitoring becomes exponentially more challenging.
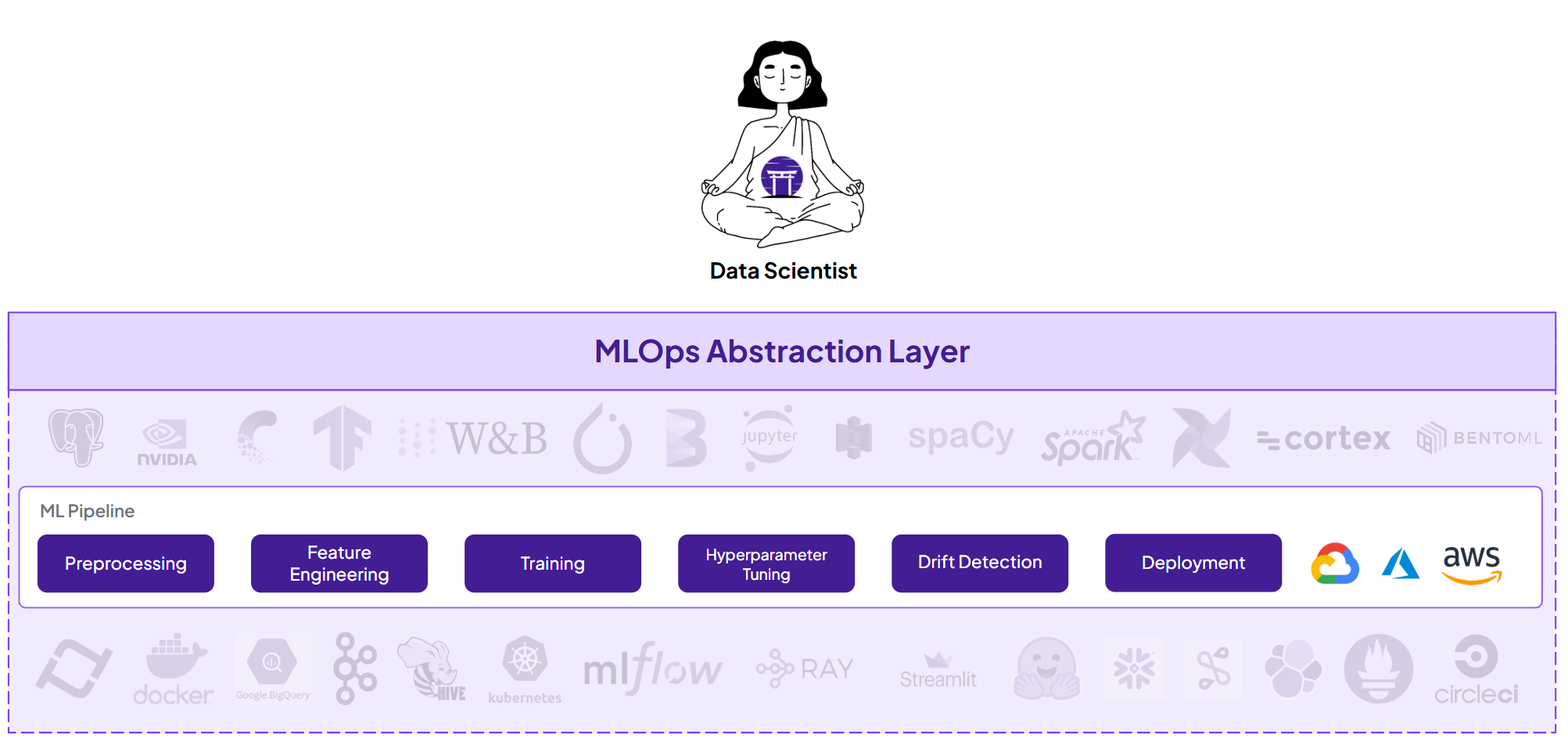
The Growing Pains of MLOps Adoption
Many organizations start their ML journey with a straightforward approach: data collection, model training, and deployment. However, as teams expand and use cases multiply, several critical challenges emerge:
- Manual Retraining Bottlenecks: Models need frequent retraining to maintain performance, but manual processes make this time-consuming and error-prone
- Limited Experimentation Velocity: Teams struggle to quickly iterate on new model architectures due to setup overhead
- Infrastructure Complexity: Managing multiple compute environments, from cloud providers to bare metal servers, creates operational overhead
- Observability Gaps: Tracking model performance, data drift, and debugging issues becomes increasingly difficult at scale

The Multi-Modal Challenge
Modern ML applications often combine multiple modalities - text, vision, and even multi-modal models. This diversity introduces unique challenges:
- Infrastructure Flexibility: Different model types require different compute resources and environments
- Deployment Complexity: Managing multiple model types in production requires sophisticated orchestration
- Unified Monitoring: Teams need consolidated visibility across all model types and deployments
Security and Compliance in MLOps
As organizations scale their ML operations, security and compliance become paramount concerns. Key considerations include:
- Data sovereignty and processing location requirements
- Audit trails for model training and deployment
- Access control and permissions management
- Traceability of model artifacts and training data
Building a Future-Proof MLOps Foundation
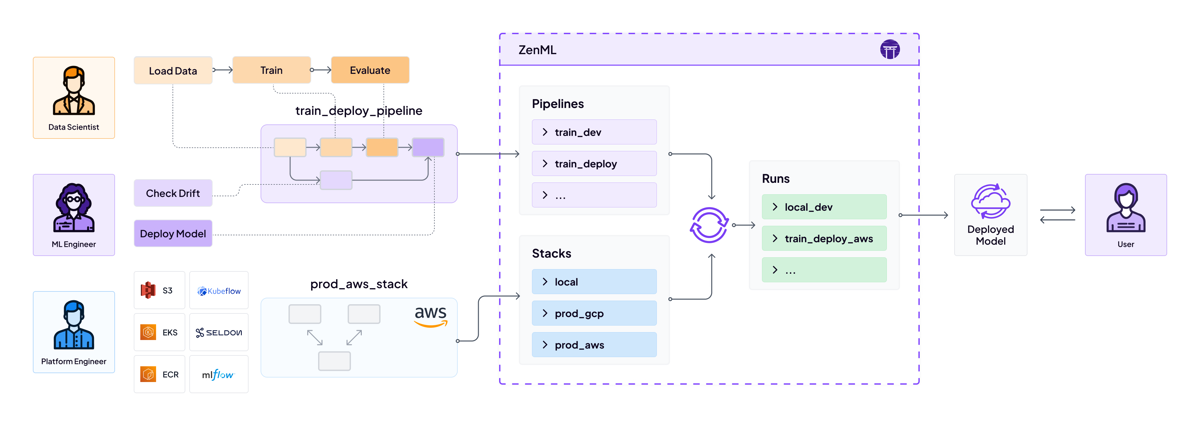
To address these challenges, organizations should focus on establishing:
1. Reproducible Workflows
- Standardized pipeline definitions
- Version control for both code and configurations
- Automated environment management
2. Infrastructure Abstraction
- Cloud-agnostic deployment capabilities
- Unified interface for different compute resources
- Flexible scaling options for varying workloads
3. Comprehensive Observability
- Centralized model performance monitoring
- Data drift detection
- Training metrics visualization
- Experiment tracking and comparison
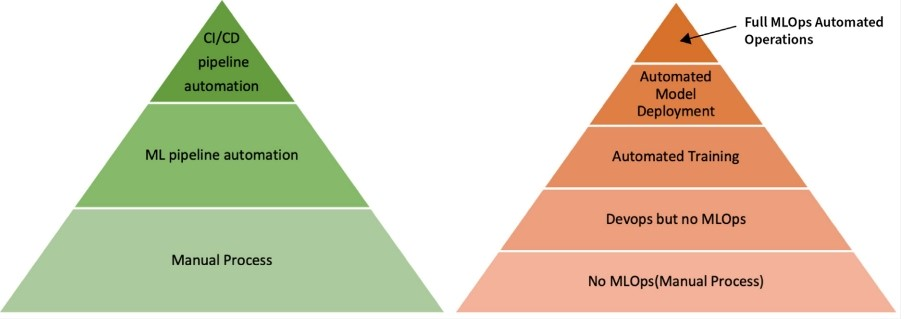
The Path Forward
The journey to MLOps maturity doesn’t happen overnight. Organizations should:
- Start with standardizing their ML workflows
- Implement basic automation for common tasks
- Gradually introduce more sophisticated monitoring and observability
- Build towards a fully automated CI/CD pipeline for ML
The key is finding the right balance between automation and flexibility, ensuring teams can move fast while maintaining control over their ML systems.
Conclusion
As organizations scale their ML operations, the transition from manual workflows to automated MLOps becomes not just beneficial but essential. By focusing on reproducibility, infrastructure abstraction, and comprehensive observability, teams can build a foundation that supports both current needs and future growth.
Remember: The goal isn’t to eliminate human involvement but to automate the repetitive aspects of ML workflows, allowing practitioners to focus on higher-value activities like model architecture improvements and business impact.