On this page
The rise of Generative AI has introduced new complexities in how we structure engineering teams and ownership of AI products. Having worked on ZenML, I’ve observed the transition from a clear MLOps/ML Engineering divide to a more nuanced landscape that now includes AI Engineers.
The Current State
Traditional ML Engineering focused on building and deploying classical machine learning models, with clear ownership boundaries between ML Engineers, MLOps Engineers, and Data Scientists. AI Engineers have emerged as a new role, primarily focused on integrating generative AI into software products through API calls to models like GPT-4 or Claude.
While AI Engineers often come from full-stack backgrounds with strong JavaScript/TypeScript and Python skills, this creates challenges at scale. What starts as simple API calls to OpenAI quickly evolves into complex data and ML problems that traditional software engineers aren’t equipped to handle.
The Ownership Problem
Take RAG applications as an example. They require:
- Document chunking strategies
- Data ingestion pipelines
- Refresh mechanisms
- Experiment tracking (e.g. MLflow)
- LLM observability (Langsmith /)
These aspects align more closely with ML engineering skills than traditional software engineering. While software engineers can learn these skills, enterprise environments need clear ownership boundaries and specialized expertise.
A Proposed Solution: Layer Separation
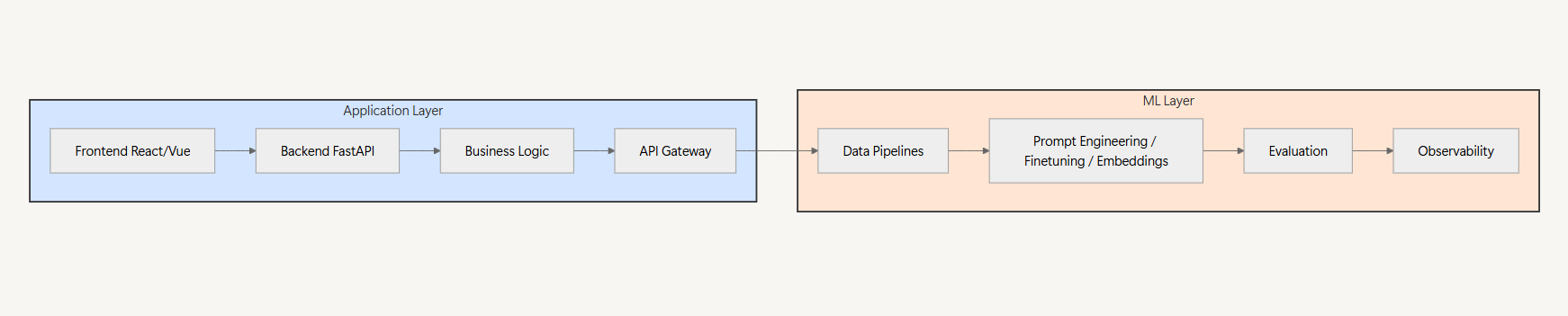
The most effective approach is separating concerns into two distinct layers:
1. Application Layer (AI Engineers/Software Engineers)
- Frontend development (React, Vue, etc.)
- Backend APIs (FastAPI, Express)
- Business logic
- User experience
2. ML Layer (ML Engineers)
- Prompt management / fine-tuning / embeddings strategy
- Data pipeline management
- Evaluation frameworks
- MLOps infrastructure
These layers communicate through well-defined interfaces like REST APIs or pub/sub patterns, but maintain independent lifecycles and ownership.
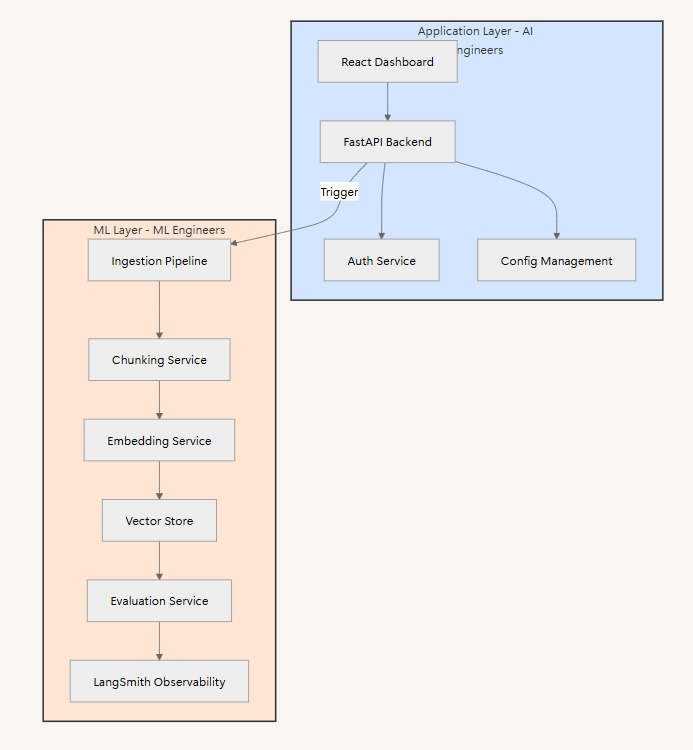
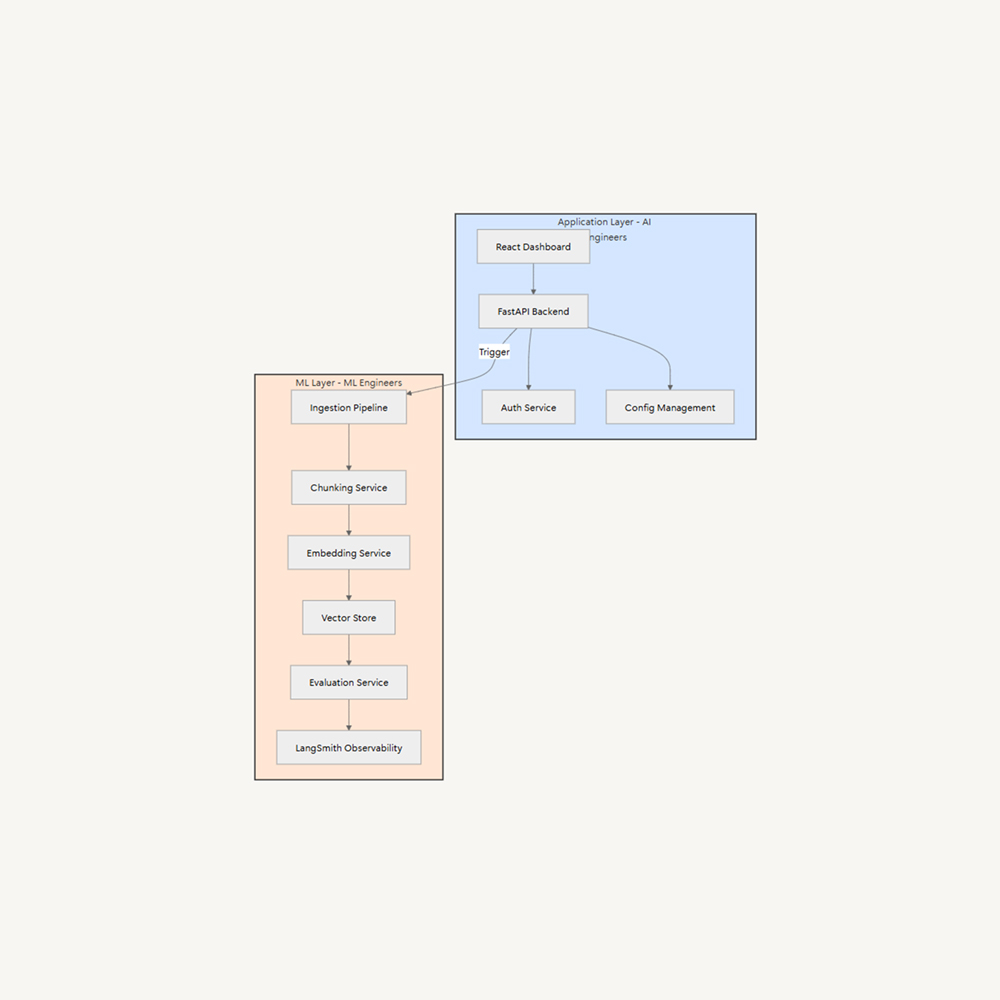
Example: Enterprise RAG Platform
Let’s examine how this layer separation works in practice. Consider building an internal platform where employees can create their own RAG-powered chatbots without writing code.
Consider building an internal no-code platform for employees to create RAG-powered chatbots:
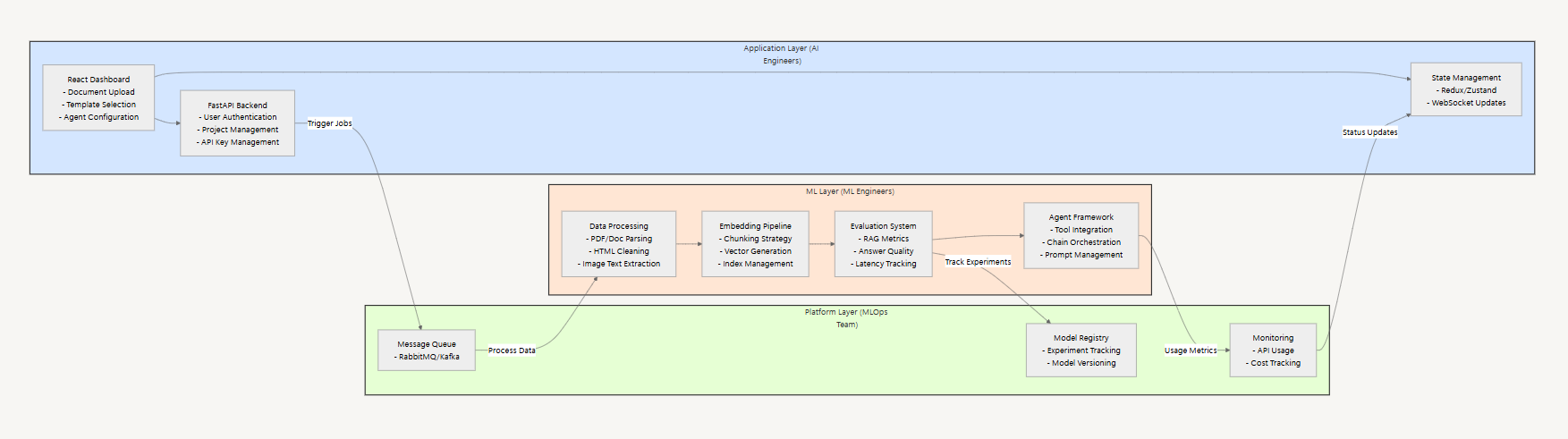
The Application team owns the user experience:
- Building the React dashboard where users drag and drop documents
- Implementing the FastAPI backend for business logic and user management
- Creating intuitive interfaces for model and agent configuration
Meanwhile, the ML team handles the AI infrastructure:
- Running robust ingestion pipelines for different document types
- Fine-tuning models for specific use cases
- Building evaluation frameworks to ensure quality
- Managing the agent orchestration layer
An internal platform team (MLOps / AI Platform) provides the bridge between these layers, maintaining shared infrastructure and ensuring smooth integration. This setup lets the AI Engineers focus on user experience while ML Engineers optimize the underlying AI systems.
Looking Forward
While “everyone will be an AI Engineer” is a common refrain, specialized roles remain crucial for building robust AI systems at scale. The key is establishing clear boundaries between application development and ML infrastructure, allowing each team to focus on their core competencies while working toward a common goal.
The industry needs to move away from bespoke solutions and toward standardized patterns for building AI-powered applications. This starts with recognizing the distinct skill sets required and structuring teams accordingly.