On this page
Breaking Free from Orchestration Lock-in: A Guide to Flexible MLOps Architecture
In today’s rapidly evolving MLOps landscape, organizations face a common challenge: how to maintain flexibility in their machine learning infrastructure while ensuring operational efficiency. As ML teams scale and requirements evolve, being locked into specific orchestration tools or cloud providers can become a significant bottleneck. This post explores key considerations for building a more adaptable MLOps architecture.
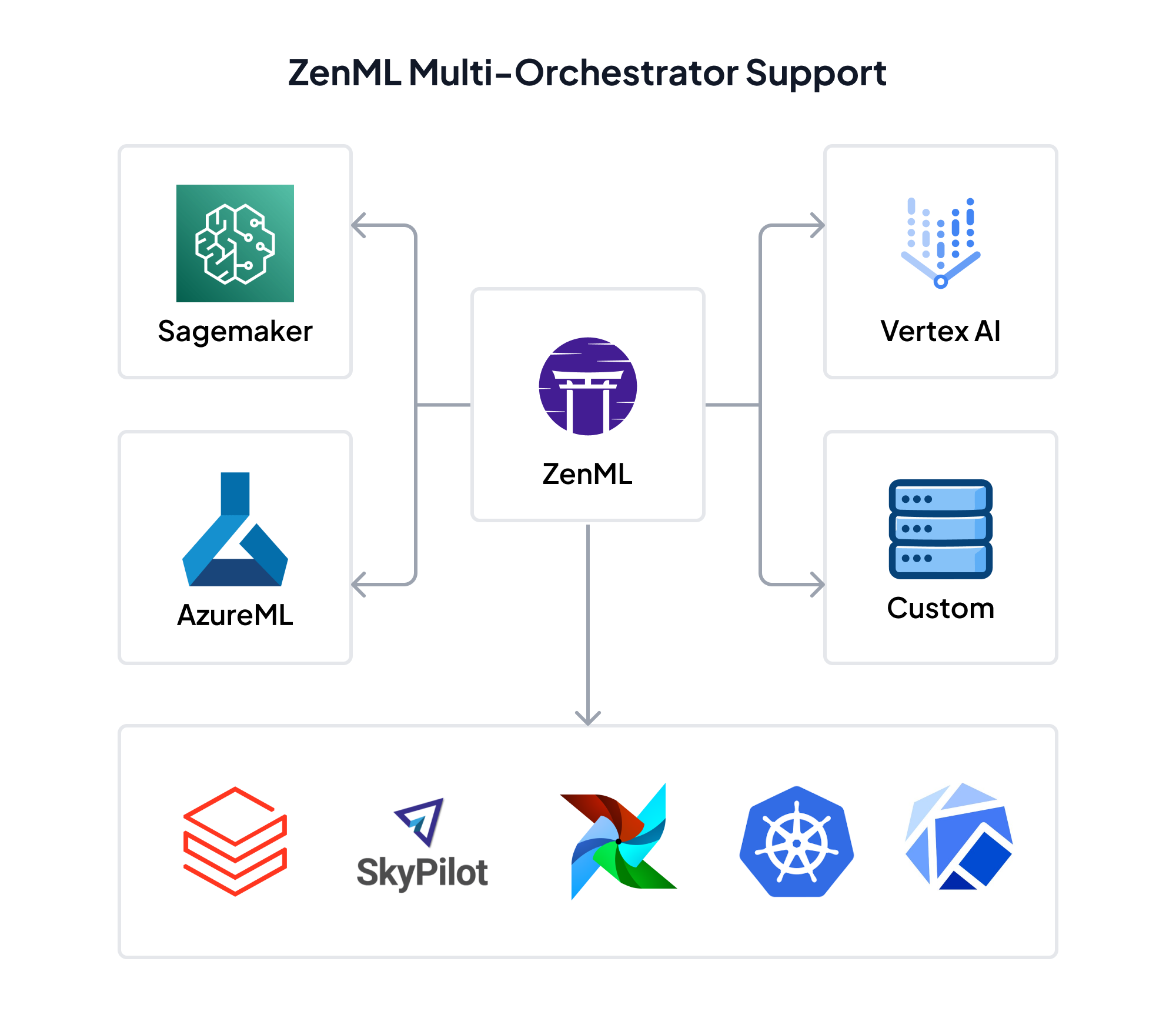
The Multi-Orchestrator Reality
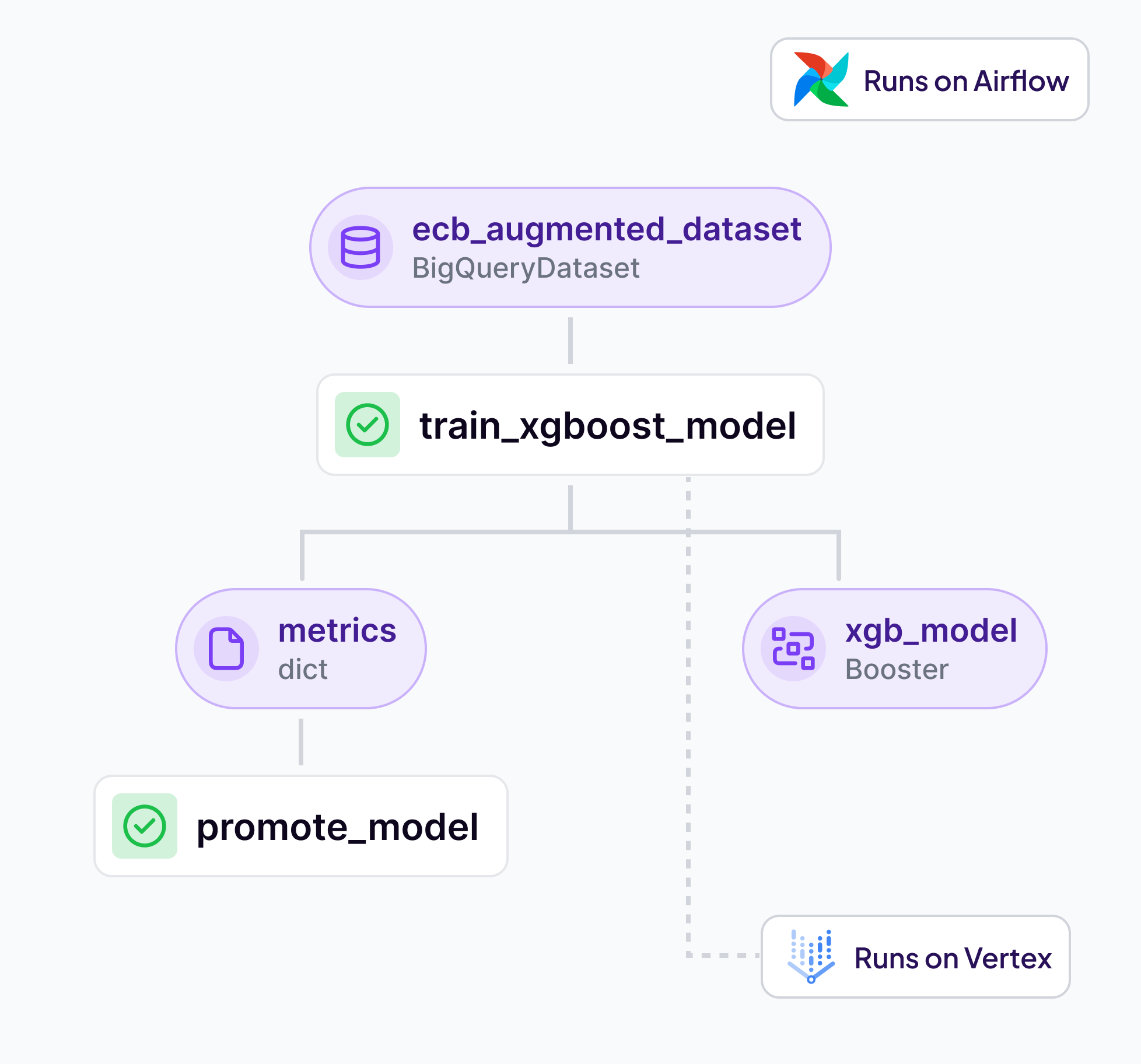
Many enterprise ML teams find themselves managing multiple orchestration tools, each serving different use cases or teams. It’s common to see Kubeflow handling complex ML workflows alongside Airflow managing simpler data pipelines. While this diversity can offer flexibility, it also introduces several challenges:
- Increased maintenance overhead
- Inconsistent deployment patterns
- Duplicated infrastructure code
- Complex migration paths
- Training overhead for team members
The Hidden Costs of Orchestrator Lock-in

When organizations heavily invest in one orchestration tool, they often discover limitations only after significant resource commitment. Common pain points include:
- Challenges in managing custom operators and configurations
- Complex security and compliance requirements across different tools
- Integration challenges with existing jobs and data processing processes
- Limited flexibility in choosing deployment targets
- Difficulty in performing backfills across different environments
and more.
Building for Orchestration Independence
The key to avoiding orchestration lock-in lies in abstracting away the infrastructure complexity while maintaining access to underlying capabilities. Here’s how organizations can approach this:
1. Abstract the Pipeline Definition
Create a unified pipeline definition language that can work across different orchestrators. This allows teams to focus on business logic rather than infrastructure details.
2. Standardize Artifact Management
Implement a consistent approach to artifact tracking and versioning that works independently of the chosen orchestrator. This should allow you to upload/download artifacts across different environments.
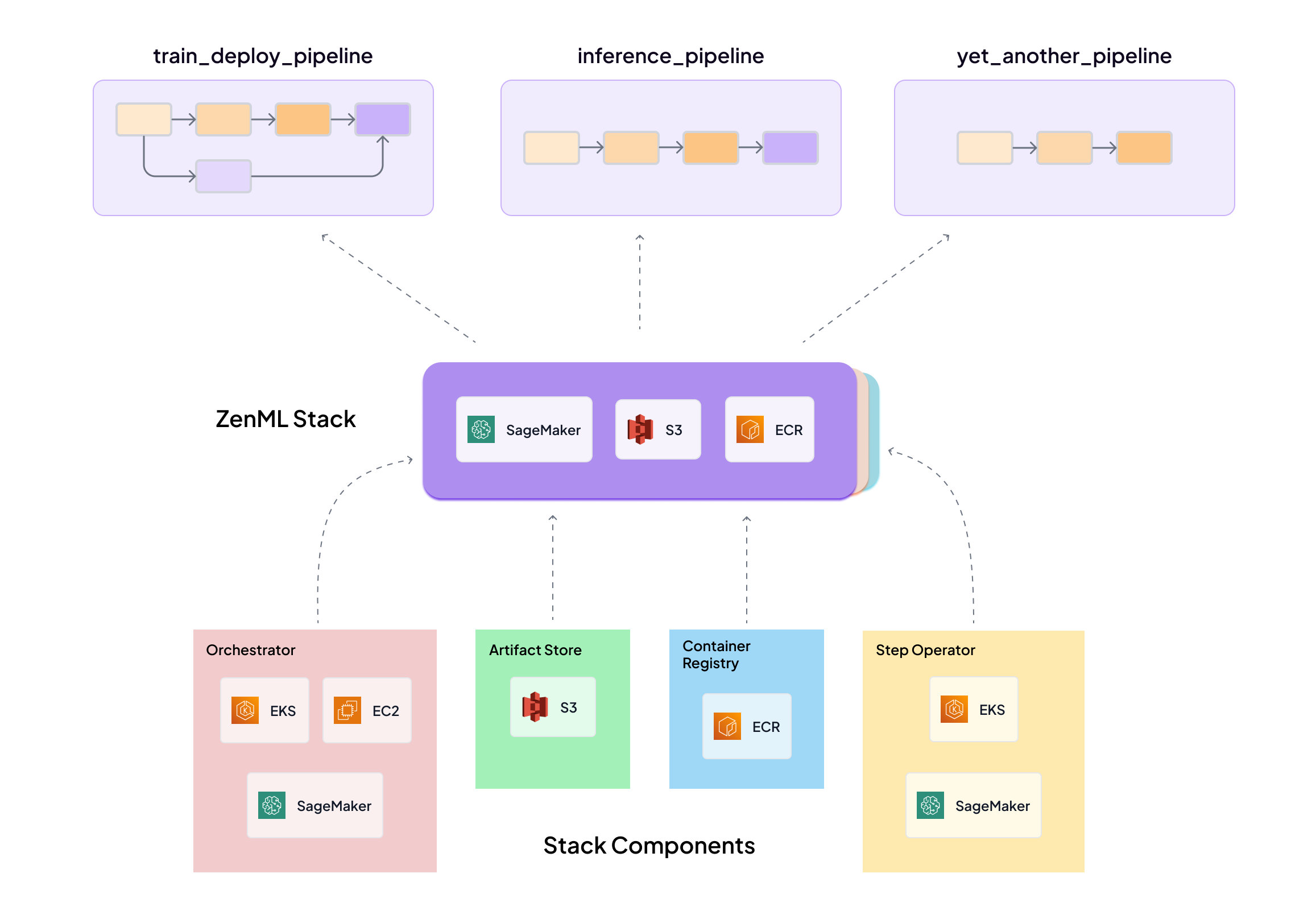
3. Detach Infrastructure from Pipeline Code
Maintain infrastructure configurations separately from pipeline logic, allowing for easy switching between different execution environments.
The diagram below shows how ZenML allows you to detach pipeline logic from the infrastructure it runs on using the concept of a Stack. You can switch stacks without changing your pipeline code.
Security and Compliance Considerations
When implementing a flexible MLOps architecture, security cannot be an afterthought. Key considerations include:
- Ensuring data never leaves your VPC
- Maintaining SOC2 and ISO 27001 compliance
- Implementing proper role-based access control
- Managing service account permissions across different environments
- Securing artifact storage and model registry access
The Path Forward
Building a flexible MLOps architecture is an iterative process. Here are some suggestions:
- Start with a non-critical ML use case for testing
- Validate orchestrator switching capabilities
- Document infrastructure requirements and security considerations
- Gradually migrate existing pipelines
- Build team expertise across different orchestration patterns

Conclusion
As ML operations continue to evolve, maintaining flexibility in your MLOps architecture becomes increasingly important. By focusing on abstraction, standardization, and security from the start, organizations can build systems that adapt to changing requirements while maintaining operational efficiency.
Remember that the goal isn’t to eliminate orchestrator-specific features, but rather to create an architecture that allows teams to leverage the best tools for their specific needs while maintaining consistency and manageability across the organization.
The future of MLOps lies not in betting on a single orchestration tool, but in building systems that can evolve with your organization’s needs while maintaining security, compliance, and operational excellence.