

In the rapidly evolving landscape of Large Language Models (LLMs), embeddings have emerged as a powerful technique for building intelligent search, retrieval, and recommendation systems. By converting unstructured data into dense vector representations, embeddings capture semantic meaning and enable us to go beyond simple keyword matching. When combined with the capabilities of LLMs, embeddings unlock a new level of understanding and interaction with vast amounts of information.
In this post, we’ll explore the key concepts behind embeddings and dive into real-world case studies that demonstrate their transformative potential. From patent processing to e-commerce search, we’ll see how industry leaders are leveraging embeddings to build systems that truly understand user intent and deliver highly relevant results.
All our posts in this series will include NotebookLM podcast ‘summaries’ that capture the main themes of each focus. Today’s blog is about embeddings in production so this podcast focuses on some of the core case studies and how specific companies developed and deployed embeddings (for search / recommendation) application(s).
To learn more about the database and how it was constructed read this launch blog. Read this post if you’re interested in an overview of the key themes that come out of the database as a whole. What follows is a slice around how embeddings was found in the production applications of the database.“
Search and Retrieval: The Core Use Case
Building RAG Systems with Embeddings
Retrieval-Augmented Generation (RAG) is one of the most compelling applications of embeddings in the LLM era. RAG systems use embeddings to find relevant information which is then injected into LLM prompts, enhancing the accuracy and context-awareness of generated responses. (Check out our previous blog on how RAG is used in production.)
The RAG workflow typically involves four key steps:
- Chunking: Breaking down large documents into smaller, manageable chunks that can be efficiently processed and retrieved.
Chunking strategies themselves vary significantly depending on the underlying data and the format of documents being used. While some companies found success with simple sentence splitting, others, like Thomson Reuters in their Open Arena project, used more sophisticated approaches, leveraging document structure and semantic segmentation to create meaningful chunks. The key takeaway is that there’s no one-size-fits-all solution for chunking. Experimentation and careful consideration of the specific use case are crucial.
- Embedding Generation: Creating dense vector representations of each chunk using an embedding model. This step is critical for capturing the semantic meaning of the text.
- Storage: Storing the chunks and their corresponding embeddings in a vector database. This enables fast similarity search and retrieval of relevant information.
- Retrieval: When a user query comes in, the system generates an embedding for the query and searches the vector database for the most semantically similar chunks. These chunks are then used to augment the LLM prompt, providing additional context for generating a response.
Beyond basic semantic similarity, production RAG systems often need to handle complex queries involving multiple constraints, negations, and temporal relationships. Instacart, for example, faced the challenge of understanding complex user intents like ‘breakfast items for a family of four with no nuts or dairy.’ To address this, they combined LLM-powered query understanding with advanced filtering and ranking techniques applied to the retrieved embeddings. This allowed them to narrow down the results to precisely match user needs.
Real-world examples showcase the power of RAG with embeddings. Clipping, an AI-powered education startup, used embeddings and a vector database to build a knowledge base for their AI tutor. By augmenting LLM prompts with relevant information, they were able to achieve higher accuracy than GPT-4 on complex exams. Similarly, companies like Kapa.ai and Activeloop have leveraged RAG to improve information retrieval accuracy in domains like patent processing and organizational knowledge management.
The benefits of RAG with embeddings are clear: improved accuracy through context injection, up-to-date information retrieval without model retraining, and greater explainability by linking generated responses back to source documents.
Optimizing Retrieval Performance
While the basic RAG workflow is powerful, there are several techniques for optimizing retrieval performance and relevance. One popular approach is hybrid search, which combines semantic similarity with traditional keyword matching. This allows the system to capture both the overall meaning and specific terms, improving retrieval precision.
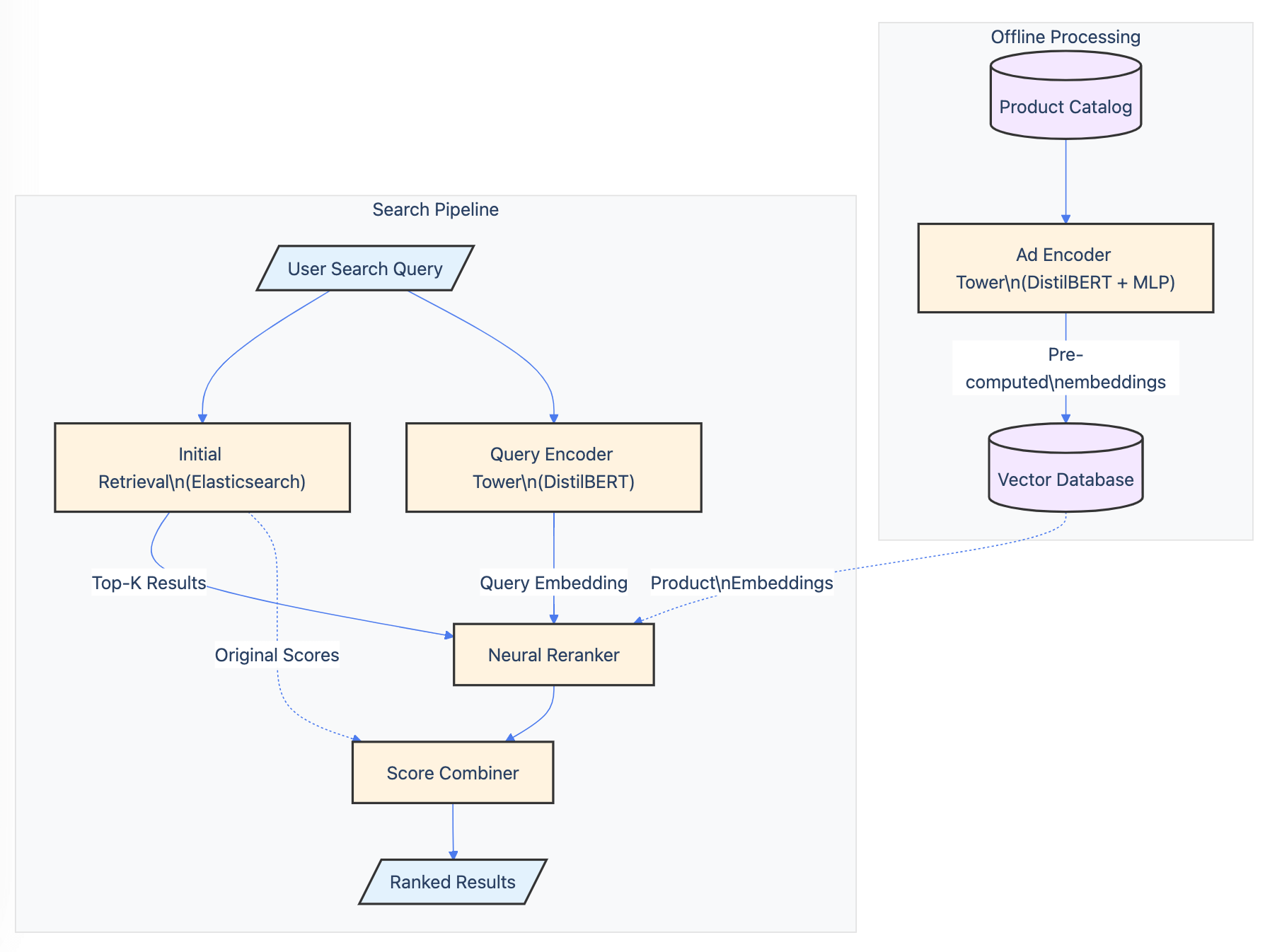
Reranking is another powerful technique for refining search results. LeBonCoin, a classifieds marketplace, implemented a two-tower neural architecture for retrieval and reranking. The initial retrieval step uses separate query and ad embeddings to efficiently generate a candidate set, while the reranking step employs a more computationally intensive cross-encoder to score and sort the results. This approach led to significant improvements in click-through and conversion rates.
Context window limitations pose another challenge for RAG systems. Since LLMs have a fixed input size, there’s a tradeoff between the number of retrieved chunks and the amount of context from each chunk. Hierarchical retrieval, where the system first retrieves larger document sections and then drills down into specific chunks, can help balance this tradeoff. Another solution is to use larger context window models like Claude (from Anthropic) or Gemini Pro (from Google) which can handle longer input sequences.
Vector Database Selection
Choosing the right vector database is crucial for building high-performance RAG systems. Key considerations include query speed, scalability, filtering capabilities, and ease of integration.
Malt, a freelancer platform, conducted a thorough benchmarking study of different vector databases including Elasticsearch, PGVector, and Qdrant. They ultimately chose Qdrant for its fast query performance, advanced filtering features, and scalability. By carefully evaluating their options and aligning the choice with their specific requirements, Malt was able to build a highly efficient recommendation system.
The choice of a vector database also impacts performance and scalability. While smaller projects might start with simpler solutions like PostgreSQL with pgvector (as seen in the early stages of the IDinsight Ask-a-Metric project), scaling to millions or billions of embeddings often necessitates specialized vector databases like Pinecone (used by Devin Kearns for his AI agent system), Qdrant (chosen by Malt after extensive benchmarking), or Weaviate. Factors like query speed, filtering capabilities, and cloud vs. on-premise deployment play a significant role in this decision.
Recommendations: A Specific Application
Building Recommendation Engines with Embeddings
Embeddings are a natural fit for building recommendation engines that surface relevant items based on user preferences and behavior. By learning vector representations of both users and items, these systems can identify similar items and generate personalized recommendations.
eBay employs embeddings for multiple recommendation tasks, from pricing guidance to similar item suggestions. Their hybrid model combines semantic similarity with direct price prediction, generating embeddings that balance relevance and price accuracy. The system ingests user interaction data like search queries, clicks, and purchases to continuously refine its understanding of user intent and item relationships.
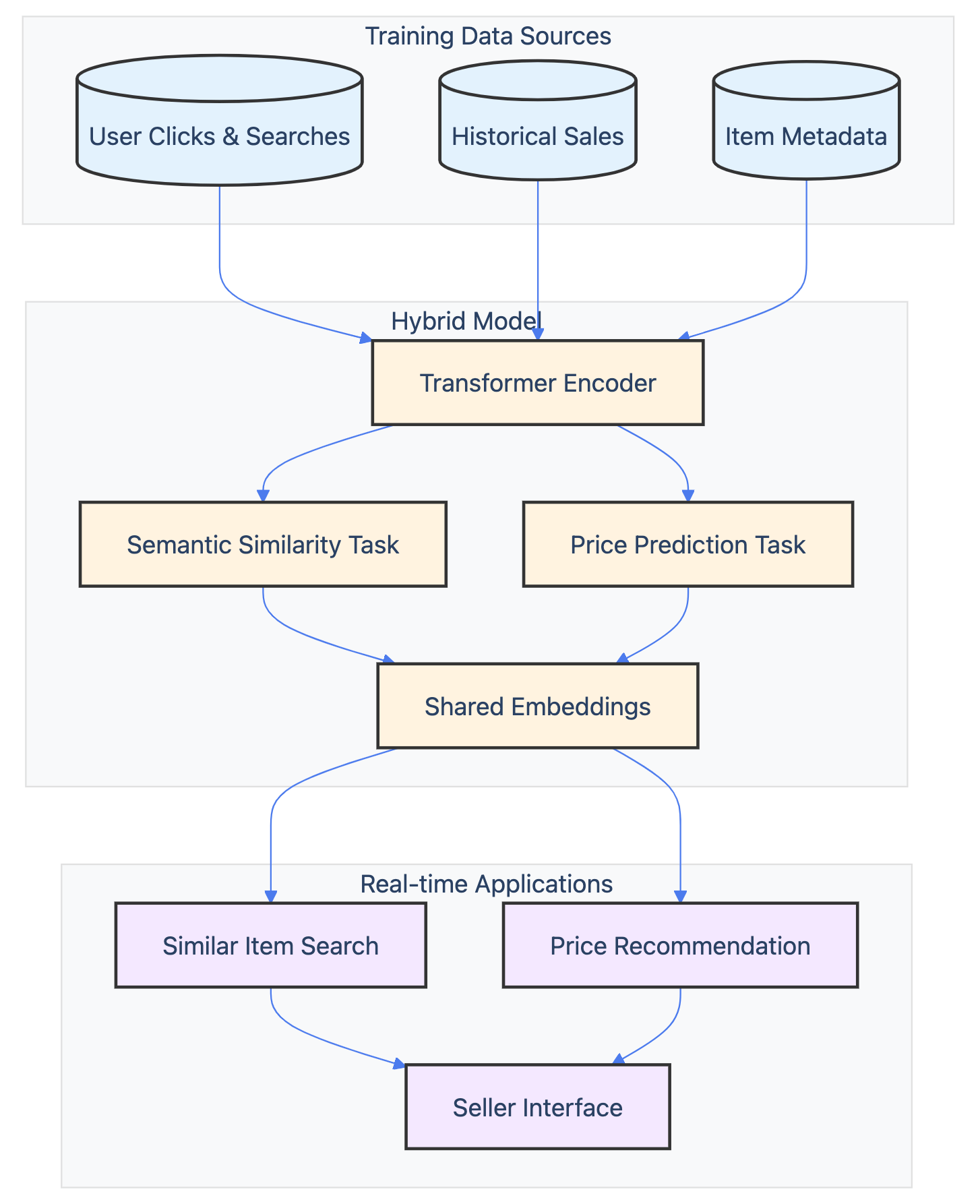
Other examples showcase the versatility of embeddings in recommendations. Golden State Warriors created personalized content suggestions, while Nextdoor used embeddings to optimize email subject lines for user engagement.
Personalization with Embeddings
One of the key benefits of embeddings in recommendation systems is the ability to create highly personalized experiences. By learning user-specific representations based on historical interactions, these systems can surface content and products tailored to individual preferences.
Amazon provides a compelling example with their use of embeddings in product recommendations. They constructed a knowledge graph that captures relationships between users, products, and broader concepts, allowing them to identify deeper connections and generate more relevant suggestions.
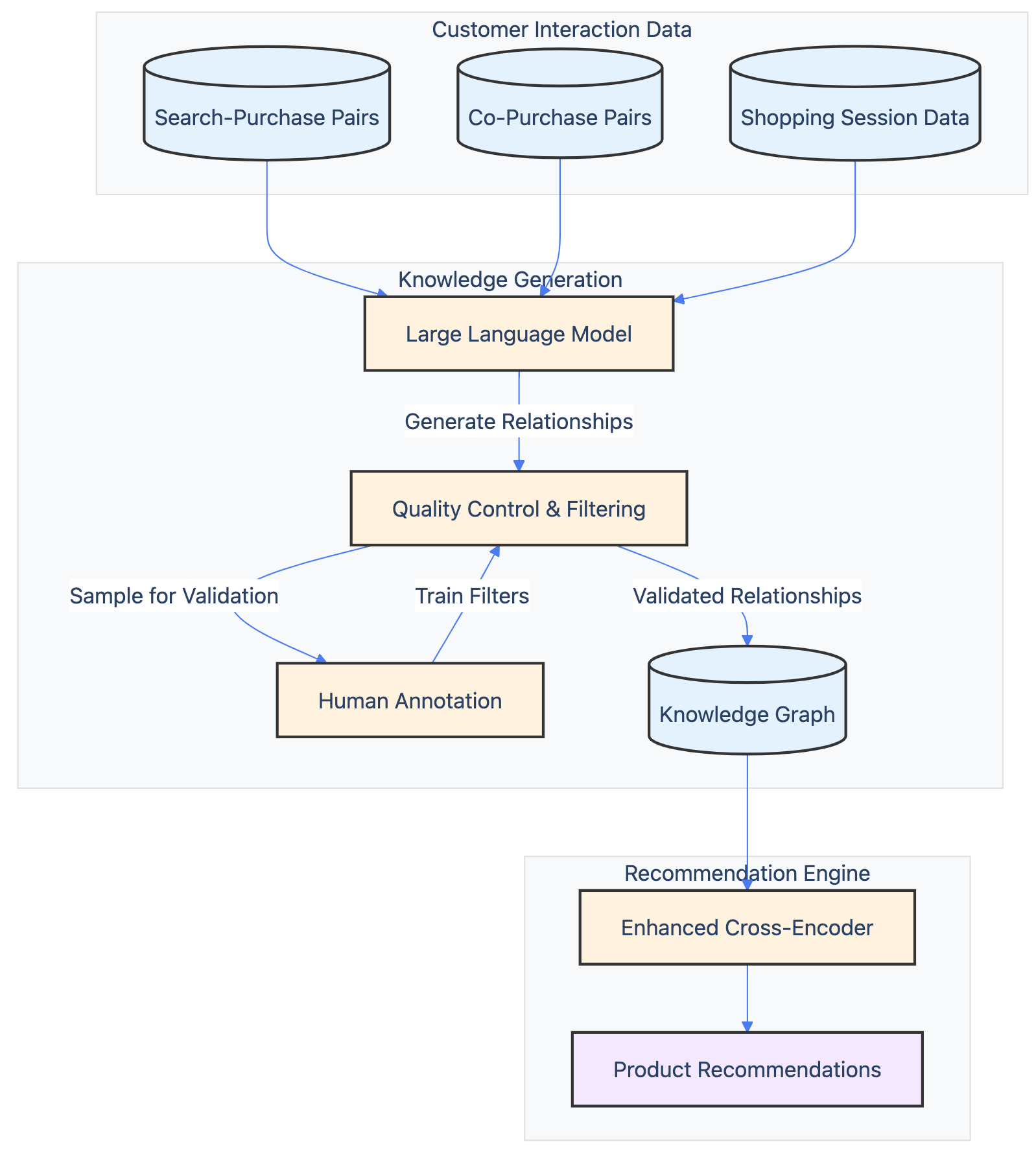
Faber Labs took personalization a step further by building LLM-powered agents that optimize for specific conversion goals. By combining user and item embeddings with reinforcement learning, their Gora system generates recommendations aimed at improving metrics like revenue and order value.
Personalization is where embeddings truly shine in recommendation systems. Nextdoor, for instance, went beyond basic content recommendations and used embeddings to personalize email subject lines, leading to a measurable increase in user engagement. By incorporating user behavior data and preferences into the embedding space, they were able to generate subject lines that resonated with individual users, resulting in a 1% lift in sessions. This example highlights how even subtle applications of embeddings can drive meaningful business outcomes.
Multimodal Search: A Glimpse into the Future
While most of the examples so far have focused on text-based applications, embeddings are equally powerful for multimodal search and retrieval. By learning joint representations across different data types like images, audio, and video, these systems can enable rich, cross-modal interactions.
Emerging use cases in the e-commerce space highlight the potential of multimodal search. Instacart and Delivery Hero are exploring image-based product recommendations, using embeddings to match user-provided photos with visually similar items in their catalogs. This opens up exciting possibilities for more intuitive and natural search experiences.
The potential of multimodal search extends beyond e-commerce. In healthcare, for instance, BenchSci is using a combination of text and image embeddings to accelerate drug discovery. Their platform integrates scientific literature with visual data from research papers, enabling researchers to explore complex relationships between diseases, genes, and potential treatments. This example demonstrates how multimodal embeddings can unlock new possibilities in data-rich domains.
Challenges and Best Practices
Maintaining Embedding Freshness
One of the key challenges in building embedding-based systems is keeping the vector representations up-to-date as new data arrives. Stale embeddings can lead to irrelevant search results and suboptimal recommendations.
The solution lies in implementing robust refresh pipelines that continuously update the vector index as documents change. Notion’s data infrastructure provides a good example, using Apache Hudi to support efficient updates and ensure data freshness for their embedding-based features.
Incremental update strategies, where only the changed portions of a document are re-embedded, can help optimize the refresh process. Dropbox employs this technique in their machine learning platform, leveraging their Nautilus system to identify and propagate content changes for embedding updates.
Keeping embeddings fresh is an ongoing challenge. Simply recomputing all embeddings periodically is often computationally expensive and inefficient. Kapa.ai, in their work with various companies on RAG deployments, recommends a delta processing approach, similar to Git, where only the changed portions of documents are re-embedded. This requires careful tracking of document versions and efficient change detection mechanisms, but significantly reduces the computational overhead of maintaining a fresh vector index.
Scaling Embedding Systems
As embedding-based applications grow in popularity and usage, scalability becomes a critical concern. Handling large datasets and high query volumes requires careful system design and optimization.
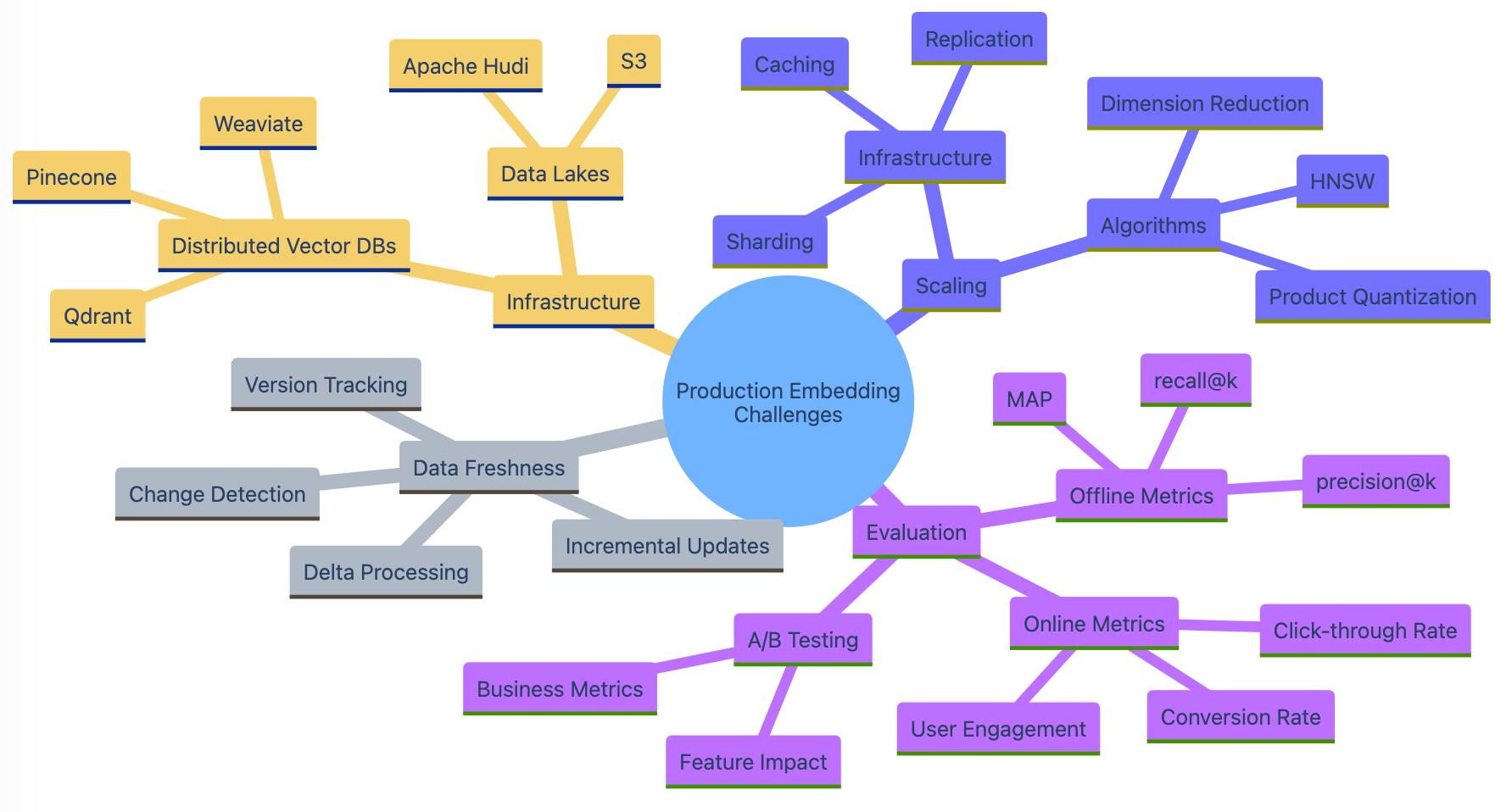
Distributed vector databases like Qdrant, Pinecone, and Weaviate offer scalable infrastructure for storing and searching billions of embeddings. These systems employ techniques like sharding, replication, and caching to ensure high availability and fast query performance.
On the retrieval side, optimizations like approximate nearest neighbor search and dimension reduction can help improve efficiency and reduce computational costs. Techniques like product quantization and hierarchical navigable small world graphs have been successfully applied to scale embedding-based retrieval to massive datasets.
Scaling embedding systems presents both infrastructure and algorithmic challenges. On the infrastructure side, companies like Notion found that scaling their initial Postgres-based embedding storage became unsustainable, leading them to adopt a distributed data lake architecture with S3 and Apache Hudi. On the algorithmic side, techniques like product quantization (reducing the number of bits used to represent each vector) and hierarchical navigable small world (HNSW) graphs (allowing for efficient approximate nearest neighbor search) are crucial for handling billions of embeddings, as seen in production systems like Dropbox’s file understanding platform.
Evaluating Embedding Effectiveness
Measuring the quality and effectiveness of embeddings is crucial for building successful applications. Evaluation metrics like recall@k, precision@k, and mean average precision provide quantitative measures of retrieval performance.
However, it’s important to go beyond simple retrieval metrics and assess the end-to-end effectiveness of the system. For search and recommendation applications, online metrics like click-through rate, conversion rate, and user engagement are key indicators of success. Offline evaluation using human judgments can provide additional insights into relevance and user satisfaction.
Regular monitoring and analysis of these metrics is essential for identifying areas for improvement and ensuring the system continues to meet user needs.
Evaluation is crucial for ensuring that your embedding system is delivering real value. While offline metrics like recall@k and precision@k provide a starting point, they don’t tell the whole story. It’s vital to measure the impact of embeddings on downstream tasks and business metrics. For search applications, this could involve tracking click-through rates and user engagement. For recommendation systems, metrics like conversion rates and customer lifetime value are more relevant. A/B testing, as demonstrated by Nextdoor in their email subject line optimization project, is a powerful technique for evaluating the real-world impact of embedding-based features.
Conclusion
Embeddings have emerged as a transformative technology in the era of LLMs, enabling organizations to build highly intelligent search, retrieval, and recommendation systems. By capturing semantic meaning and relationships, embeddings allow us to go beyond keyword matching and interact with information in more intuitive and contextual ways.
The real-world examples we’ve explored, from Activeloop’s patent processing system to eBay’s hybrid pricing and recommendation engine, showcase the diverse applications and benefits of embeddings. These case studies highlight the importance of careful system design, scalable infrastructure, and continuous evaluation and improvement.
As LLMs continue to advance and multimodal applications become more prevalent, the potential for embeddings will only grow. By staying at the forefront of these developments and adopting best practices from industry leaders, organizations can unlock the power of embeddings and build systems that truly understand and serve user needs.


