

On this page
Recent advancements in large language models (LLMs) have stirred up the field of natural language processing, enabling applications with unprecedented fluency and coherence. However, despite their impressive capabilities, LLMs often struggle with hallucinations, outdated knowledge, and limited domain expertise. Enter Retrieval Augmented Generation (RAG) - a powerful technique that connects LLMs to external knowledge sources, allowing them to access and process information beyond their training data.
In this blog post, we’ll use ZenML’s LLMOps database to examine case studies from companies like Amazon, BNY Mellon, and Salesforce to understand how RAG is being used to build LLM applications that are both eloquent and informed. By the end, you’ll have a solid understanding of the different ways that RAG is being used in production and be equipped with actionable guidance for implementing it in your own projects.
All our posts in this series will include NotebookLM podcast ‘summaries’ that capture the main themes of each focus. Today’s blog is about RAG in production so this podcast focuses on some of the core case studies and how specific companies developed and deployed RAG application(s).“
To learn more about the database and how it was constructed read this launch blog. Read this post if you’re interested in an overview of the key themes that come out of the database as a whole. What follows is a slice around how RAG was found in the production applications of the database.
Real-World Applications of RAG: Showcasing its Versatility 🌍
Let’s explore some real-world applications across various domains, diving into the technical details and practical considerations that make these implementations successful.
Customer Support 🙋♀️
In the realm of customer support, companies like Amazon Pharmacy and InsuranceDekho are harnessing the power of RAG to build chatbots that provide accurate and up-to-date information to customers. By integrating their knowledge bases with LLMs, these chatbots can handle a wide range of queries, from product information to policy details, improving customer service efficiency and reducing response times.
Amazon Pharmacy’s HIPAA-compliant chatbot is a prime example of RAG in action. Built using Amazon SageMaker JumpStart foundation models and a RAG architecture, the system combines embedding-based search and LLM-based response generation to provide accurate answers to customer queries while maintaining stringent security and compliance requirements. The chatbot’s architecture includes an agent feedback collection mechanism, enabling continuous improvement based on real-world interactions.
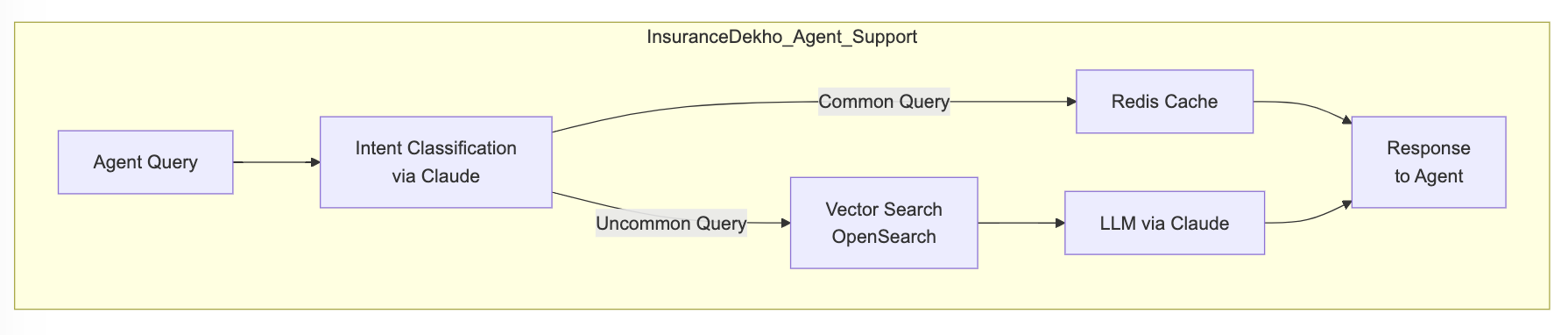
InsuranceDekho, on the other hand, transformed its insurance agent support system using Amazon Bedrock and Anthropic’s Claude Haiku. By eliminating the need for constant subject matter expert consultation, the RAG-based solution achieved an impressive 80% reduction in response times for customer queries about insurance plans. The system’s performance is further optimized through the use of Redis for caching frequent responses and OpenSearch for efficient vector storage.
Knowledge Management 📚
In the domain of knowledge management, RAG is improving how organizations provide their employees with instant access to vast repositories of information. Morgan Stanley, for instance, leverages GPT-4 and RAG to empower financial advisors with real-time access to a comprehensive knowledge base. By integrating internal documents, research reports, and market data, the system enables advisors to quickly find relevant information and provide timely advice to clients. The RAG implementation significantly improves information accessibility and enhances the quality of financial recommendations.

BNY Mellon, another financial giant, implemented an LLM-based virtual assistant to streamline information access for their 50,000 employees across the organization. Starting with targeted pilot deployments in specific departments, they gradually scaled the solution enterprise-wide using Google’s Vertex AI platform. The system tackles challenges in document processing, chunking strategies, and context-awareness for location-specific policies, ultimately transforming how employees navigate and retrieve critical information.
Technical Documentation 📄
RAG is also making waves in the realm of technical documentation, with companies like Weights & Biases and Alaska Airlines leveraging its power to build intelligent documentation assistants. These assistants combine LLMs with internal documentation repositories, providing developers with quick and accurate answers to their technical queries, improving productivity and reducing the time spent searching for information.
Scaling RAG systems for technical documentation involves optimizing the document processing pipeline, implementing efficient vector search, and ensuring low-latency response generation. Weights & Biases, in their journey of refactoring Wandbot, their LLM-powered documentation assistant, achieved remarkable results - an 84% reduction in latency and a 9% improvement in accuracy. Their experience highlights the importance of systematic evaluation and continuous monitoring throughout the development process, ensuring that the system remains performant and reliable as it scales.
Research and Analysis 🔬
RAG is also transforming the landscape of research and analysis, empowering companies like Emergent Methods and Thomson Reuters to process vast amounts of data and generate valuable insights. By integrating LLMs with structured and unstructured data sources, these systems can analyze massive volumes of information, identify patterns, and provide actionable recommendations, streamlining research workflows and enabling more comprehensive analysis.

Emergent Methods’ production-scale RAG system is a testament to the scalability and robustness of this approach. Processing over 1 million news articles daily, the system employs a microservices architecture to deliver real-time news analysis and context engineering. By combining open-source tools like Quadrant for vector search, VLM for GPU optimization, and their proprietary Flow.app for orchestration, Emergent Methods addresses challenges in news freshness, multilingual processing, and hallucination prevention while maintaining low latency and high availability.
Challenges and Best Practices: Practical Considerations 🚧
While RAG offers immense potential, implementing it in production comes with its own set of challenges. Let’s explore some of these challenges and discuss best practices to overcome them, drawing insights from real-world implementations.
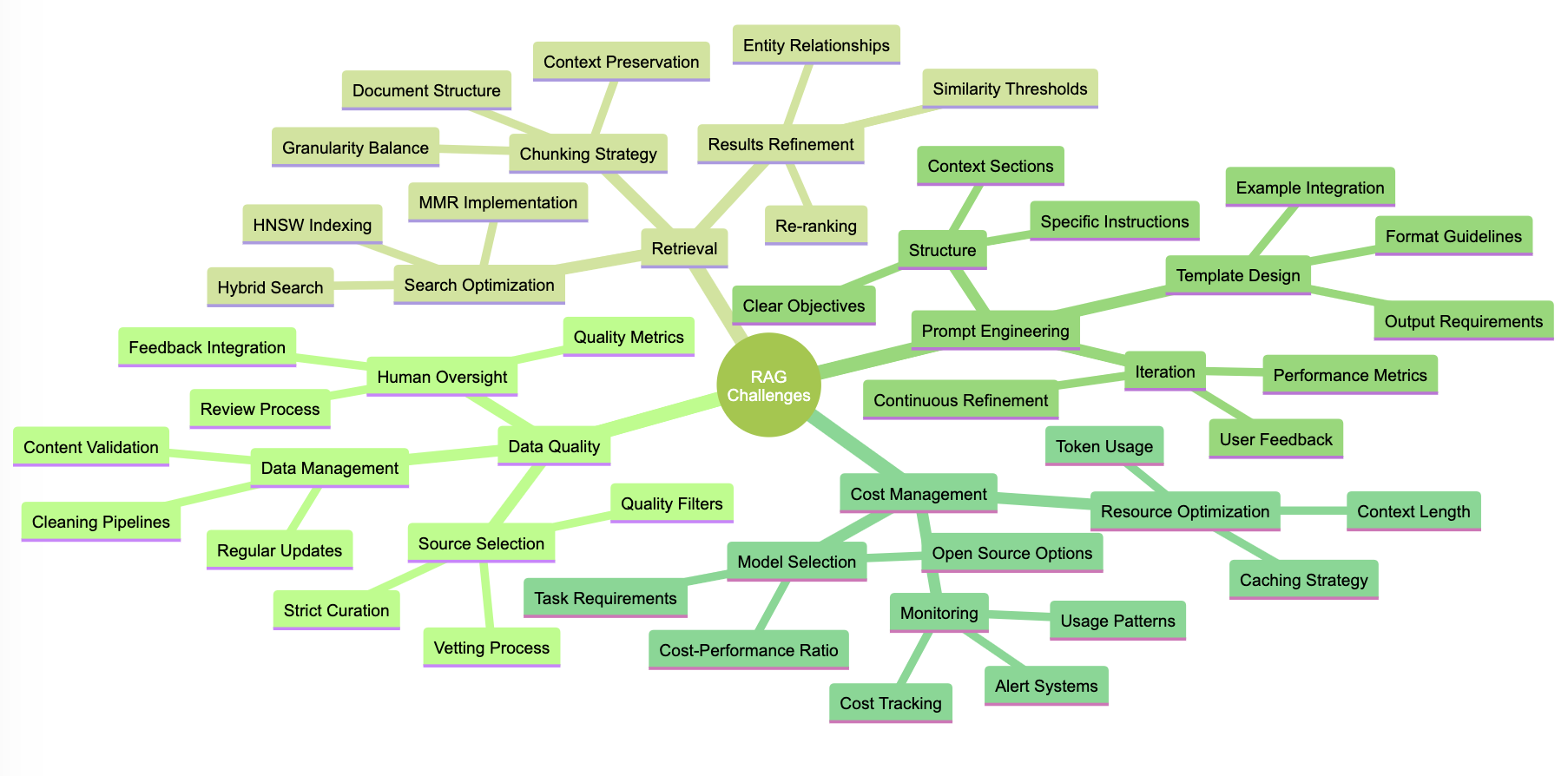
Data Quality and Management 📊
One of the primary challenges in implementing RAG is ensuring the quality and relevance of the knowledge base. The effectiveness of the system heavily depends on the data used for retrieval. As the saying goes, “garbage in, garbage out.” To address this challenge, it’s crucial to establish rigorous data curation, cleaning, and preprocessing workflows.
Trace3’s Innovation-GPT, a custom RAG solution for technology research and knowledge management, emphasizes the importance of data quality and human oversight in their research process. They implement strict data source curation, quality filters for secondary sources, and regular content validation to maintain the integrity of their knowledge base.
Best practices include careful selection and vetting of data sources, automated data cleaning and normalization pipelines, regular updates to keep the knowledge base current, and human review and validation of data quality. By prioritizing data quality and implementing robust management processes, organizations can ensure that their RAG systems are built on a solid foundation.
Retrieval Challenges 🔍
Retrieving the most relevant information is critical for the success of a RAG system. Suboptimal retrieval can lead to irrelevant or incomplete responses, undermining the effectiveness of the system. To optimize retrieval performance, it’s important to experiment with different techniques and fine-tune the parameters of the vector database.
Retrieval strategies like Maximum Marginal Relevance (MMR) and Hierarchical Navigable Small World (HNSW) can significantly improve the diversity and relevance of retrieved documents. Qatar Computing Research Institute’s T-RAG system, for example, utilizes MMR to ensure diverse document retrieval and incorporates a tree-based entity structure to handle complex entity relationships within organizational hierarchies.
Best practices for retrieval optimization include experimenting with different chunking strategies to find the optimal balance between granularity and context preservation, fine-tuning retrieval parameters like the number of retrieved documents and similarity thresholds, implementing hybrid search approaches combining lexical and semantic search, and incorporating re-ranking mechanisms to further refine retrieval results. By iteratively optimizing the retrieval process, organizations can ensure that their RAG systems consistently provide the most relevant information to the LLM.
Prompt Engineering for RAG 📝
Crafting effective prompts is essential for guiding the LLM to generate accurate and coherent responses based on the retrieved information. Prompt engineering for RAG requires careful consideration of the prompt structure, instructions, and examples to ensure the model effectively incorporates the retrieved context.
Human Loop, a developer platform for building reliable LLM applications, highlights the importance of structured prompt templates in their RAG implementations. They recommend including clear objective statements, detailed context sections, specific instructions, output requirements, and comprehensive examples in prompts. Their experience shows that well-crafted examples can improve success rates from 90% to 99.9%.
Best practices for prompt engineering in RAG systems include developing a consistent prompt structure that clearly separates instructions, context, and examples, providing explicit instructions on how to incorporate the retrieved information into the response, including diverse examples that demonstrate the desired output format and style, and iteratively refining prompts based on user feedback and system performance.
Cost Optimization 💰
Running LLM APIs and storing large amounts of data in vector databases can be expensive, especially as the scale of the application grows. Cost optimization is a crucial consideration when implementing RAG in production.
Prosus, a global technology group, shares their experience with cost optimization in their enterprise-wide RAG deployment. They emphasize the importance of careful model selection based on task requirements, efficient prompting to minimize token usage, context length management to reduce unnecessary processing, and strategic use of fine-tuning only when necessary. By implementing these cost optimization strategies, Prosus has achieved significant reductions in token costs and infrastructure expenses.
Best practices for cost optimization in RAG systems include monitoring and analyzing usage patterns to identify inefficiencies, leveraging caching mechanisms to reduce redundant processing, exploring alternative LLMs or open-source models that offer better cost-performance trade-offs, and implementing automated cost monitoring and alerting systems to proactively manage expenses.
Beyond Basic RAG: Advanced Techniques and Future Directions 🚀
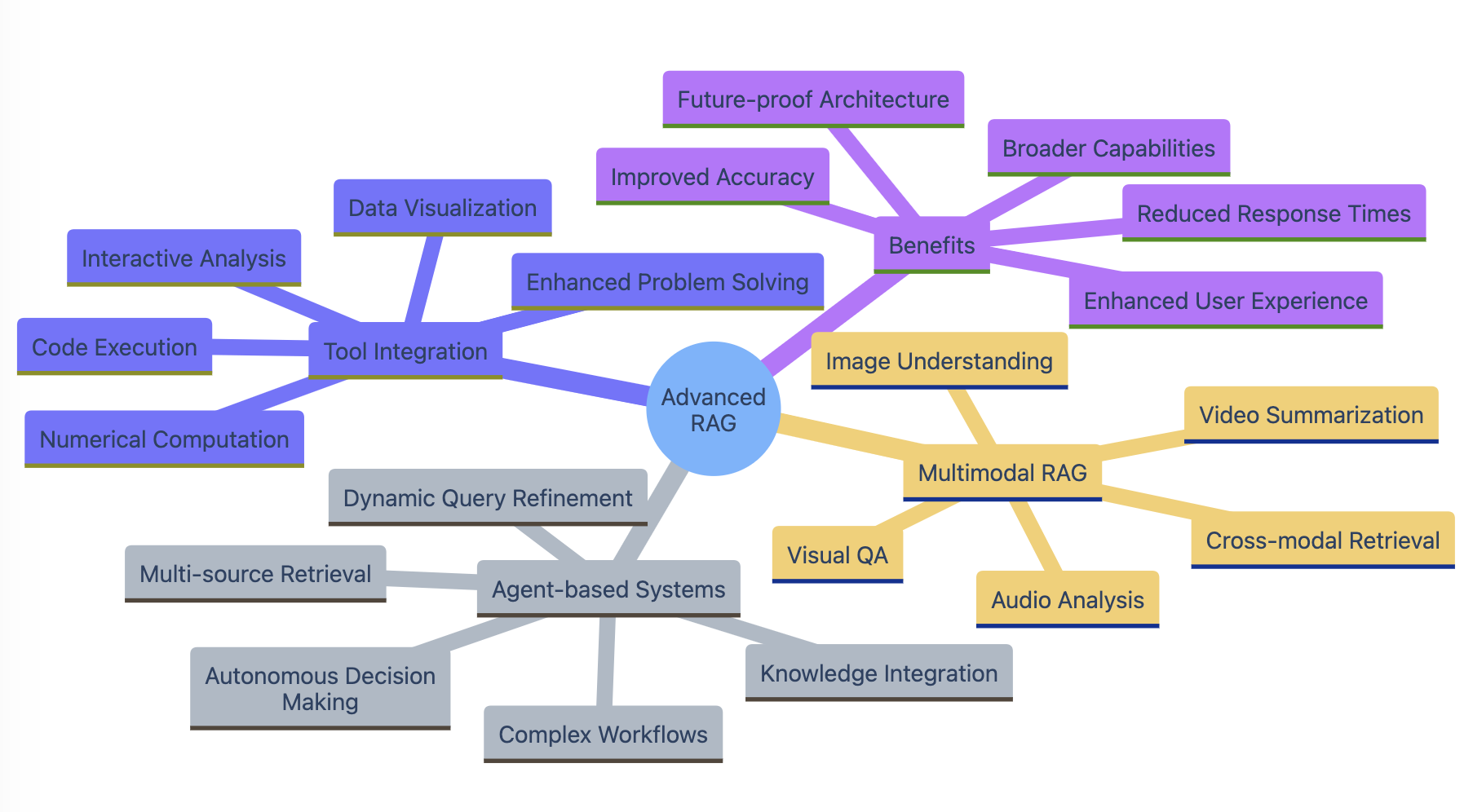
As the field of RAG continues to evolve, researchers and practitioners are exploring advanced techniques and future directions to further enhance the capabilities of LLM applications. Let’s briefly touch upon a few exciting areas of development:
Multimodal RAG 🖼️🎥
While traditional RAG focuses on textual data, the concept can be extended to other modalities like images, audio, and video. By leveraging multimodal embeddings, RAG systems can retrieve and integrate information from diverse data types, enabling more comprehensive and contextualized responses. This opens up new possibilities for applications in domains like visual question answering, video summarization, and audio analysis.
Agent-based RAG 🤖
Another promising direction is the integration of RAG with agent-based systems. By combining RAG with autonomous agents, organizations can develop more sophisticated workflows that involve retrieving information from multiple sources, dynamically refining queries based on previous results, and performing complex tasks through a series of interactions. Agent-based RAG has the potential to automate complex knowledge-intensive processes and enable more intelligent decision-making.
Tool Augmentation 🛠️
RAG can also be combined with other tools and techniques to further enhance the capabilities of LLM applications. For example, integrating RAG with calculators or code interpreters allows LLMs to perform numerical computations or execute code snippets, expanding their problem-solving abilities. Similarly, combining RAG with interactive visualization tools enables LLMs to generate data-driven insights and explanations.
These advanced techniques and future directions highlight the vast potential of RAG and its ability to push the boundaries of what LLM applications can achieve. As research progresses and new innovations emerge, we can expect to see even more powerful and versatile RAG systems in the future.
Conclusion: Practical Implications and Future Considerations 🔍
This exploration of RAG implementations in production environments reveals both significant opportunities and notable challenges that organizations must carefully consider. Through case studies ranging from Amazon Pharmacy’s HIPAA-compliant chatbot to Emergent Methods’ news processing system, we’ve seen how RAG can enhance LLM applications when thoughtfully implemented.
The real-world implementations demonstrate that RAG’s effectiveness heavily depends on several critical factors:
- Quality and maintenance of the knowledge base
- Careful optimization of retrieval mechanisms
- Thoughtful prompt engineering
- Strategic cost management
- Integration with existing systems and workflows
While RAG has shown promise in improving accuracy and reducing response times, organizations should approach implementation with realistic expectations. Success requires sustained investment in data quality, retrieval optimization, and system maintenance. The experiences of companies like BNY Mellon and Weights & Biases highlight that achieving reliable performance often involves iterative refinement and careful attention to system design.
Looking ahead, emerging techniques like multimodal RAG and agent-based systems present intriguing possibilities, but their practical implementation will likely present new challenges. Organizations considering RAG implementation should:
- Start with well-defined use cases where traditional approaches fall short
- Invest in robust data management practices
- Plan for ongoing optimization and maintenance
- Monitor and measure system performance against clear objectives
The path forward with RAG isn’t about wholesale adoption but rather thoughtful integration where it adds demonstrable value. As the field matures, success will likely come from balanced implementation strategies that acknowledge both the technology’s potential and its practical limitations.


