On this page
Your team has developed a breakthrough machine learning model with impressive metrics in your development environment. Stakeholders are excited about the potential impact. But now comes the truly challenging part—bridging the gap between that promising prototype and a reliable production tool that end users can trust with real-world decisions.
Why ML Deployment Is Uniquely Challenging
Data scientists who excel at creating sophisticated algorithms often find themselves navigating unfamiliar territory when it comes to deployment. These hurdles typically involve model serving, monitoring, and governance:
- Reproducibility problems: When deployment involves manual handoffs between data scientists and IT teams, subtle inconsistencies between environments lead to unexplained performance degradation when real-world data is introduced.
- Versioning complexity: Without systematic tracking mechanisms, teams may unknowingly use outdated models or different departments may rely on varying versions of the same model.
- Audit requirements: Regulated industries require comprehensive audit trails that can trace every prediction back to its training data, code, and validation processes—something most manual workflows can't support.
Enterprise Solutions: Powerful but Complex
The industry has responded with sophisticated model deployment platforms: tools like Seldon Core, BentoML, and hyperscaler solutions like SageMaker, Vertex AI, and Azure ML. These platforms offer powerful capabilities but introduce critical trade-offs:
- Specialized Expertise Requirements: Demands dedicated DevOps/MLOps skills beyond core data science teams.
- Infrastructure Complexity: Involves Kubernetes orchestration, security hardening, and networking configuration - or alternatively, hyperscaler ecosystem dependencies that limit multi-cloud flexibility.
- Learning Curve and Cost Considerations: Substantial setup time for Kubernetes-based solutions contrasts with managed platforms' rapid onboarding but hidden compliance complexities and ongoing expenses.
For many organizations, these enterprise solutions theoretically address deployment needs but create practical obstacles that impede the iterative development cycles essential to ML’s value proposition.
Finding a Practical Middle Ground in the MLOps Spectrum
What if you could avoid most of the infrastructure burden while still gaining benefits like reproducibility, automation, and traceable model behavior? This is where frameworks like ZenML can bridge the gap by offering structured, reproducible ML workflows without requiring a full DevOps overhaul.
The key is integration with existing deployment platforms through components that allow you to deploy models locally or in production, track services, and manage model servers via Python or CLI—all while maintaining consistent model tracking, versioning, and promotion logic regardless of where you deploy.
| Use Case | Integration Options |
|---|---|
| Deployment | MLflow, Seldon, BentoML, Databricks, ++ |
| Model Versioning & Registry | ZenML MCP, MLflow |
| Experiment Tracking | MLflow, W&B, VertexAI, Neptune, Comet |
| Promotion Logic | Custom @step logic + MCP |
| Artifact & Metadata Tracking | ZenML built-in, plus external loggers |
This flexible integration approach allows teams to leverage existing tools and platforms while maintaining a consistent workflow structure and artifact lineage.
Implementation Note
The approach in this project prioritizes simplicity, accessibility, and reduced infrastructure complexity. While it handles moderate traffic effectively, high-scale production environments may need additional orchestration. Organizations with strict latency needs (e.g., real-time processing) may require specialized serving platforms.
The solution proposed here strikes a pragmatic middle ground — more structured than ad lib deployment scripts but less complex than full enterprise MLOps platforms. For many organizations, this balance provides the most value while minimizing operational overhead.
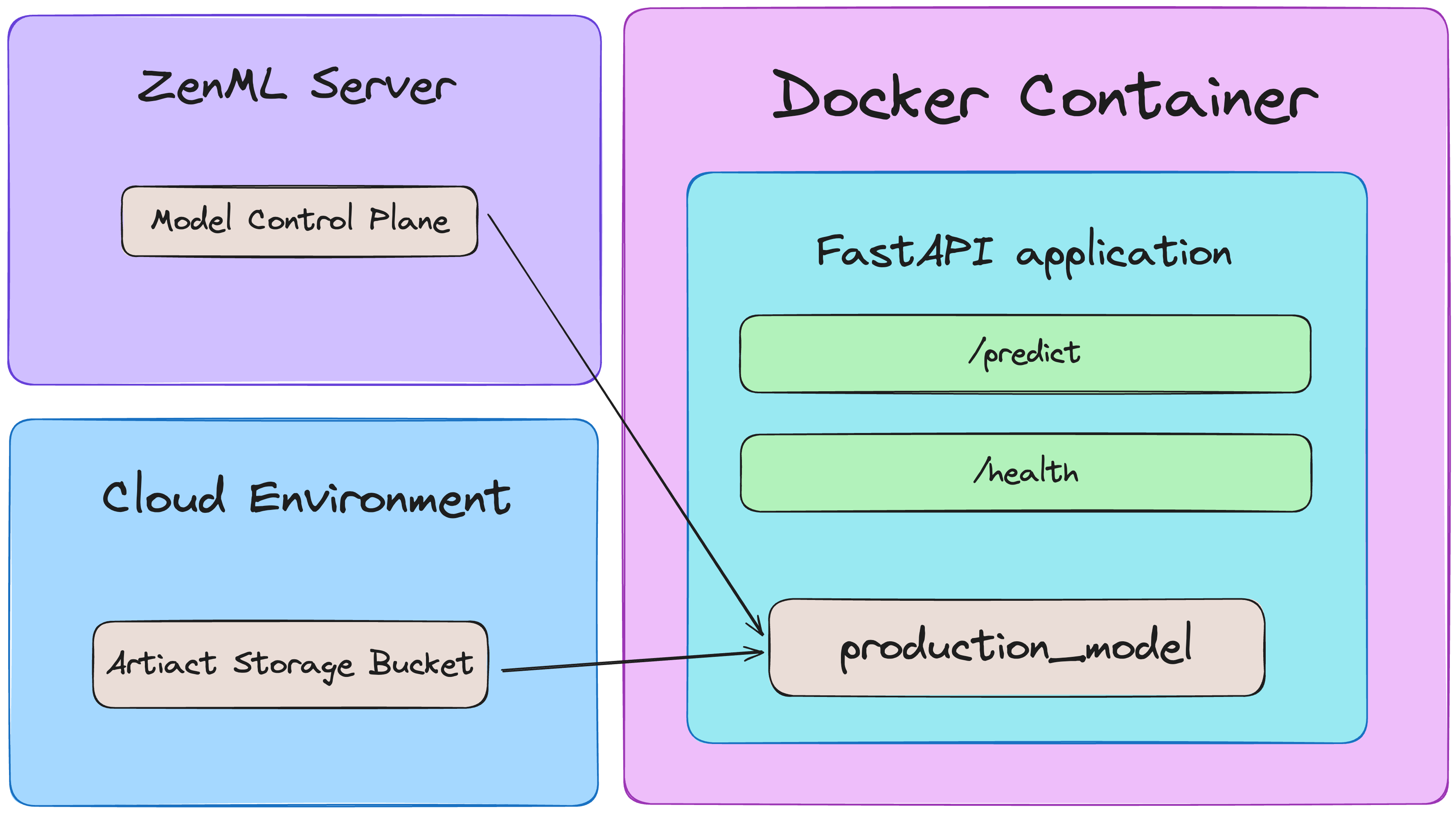
Model Handover to Production Service
A key decision in ML deployment is *how *your production service accesses the specific model version that your pipeline selected. ZenML orchestrates model selection, but your serving infrastructure *doesn’t *need ZenML access at runtime. This separation creates a clean boundary between environments. Here are two ways to achieve this decoupling:
Bake-In Approach: Embedding the Model in the Image
Best for: Smaller models where image size isn’t a major concern and updates don’t happen extremely frequently (as each model update requires a new image build).
In this approach, your deployment pipeline gets the approved model artifact as it builds the image and embeds it directly inside the Docker image. At runtime, your FastAPI service simply loads this pre-packaged model from a predefined local path (no ZenML connection required), which results in a completely self-contained deployment unit.
Volume-Mount Approach: Externalizing the Model
Best for: Large models (to keep image sizes down) or scenarios requiring frequent model updates without rebuilding the entire service image.
For larger models or scenarios requiring frequent updates, the volume-mount approach puts the model artifact on a host-accessible storage location. Your container then mounts this location at runtime and the service can access the model without embedding it in the image. This allows for model swapping without container rebuilds and works well for models too big to package in containers.
Choosing the Right Approach
Both approaches have the same benefits: they use ZenML for end-to-end versioning and artifact tracking during training, and maintain the same clean runtime separation from your development infrastructure. For many teams, starting with the bake-in pattern provides the simplest path to production while the volume-mount pattern is a natural evolution as model complexity grows.
Let’s now look at how to implement the deployment pipeline itself using ZenML steps. The following examples illustrate the core structure, which can be adapted to fit either the bake-in or volume-mount pattern depending on your chosen strategy.
Deployment as a Pipeline: How It Works in Practice
At the heart of this approach is a deployment pipeline powered by automatic tracking infrastructure. Each deployment run is versioned, reproducible, and fully traceable with complete logs of inputs, outputs, environment variables, and pipeline context.
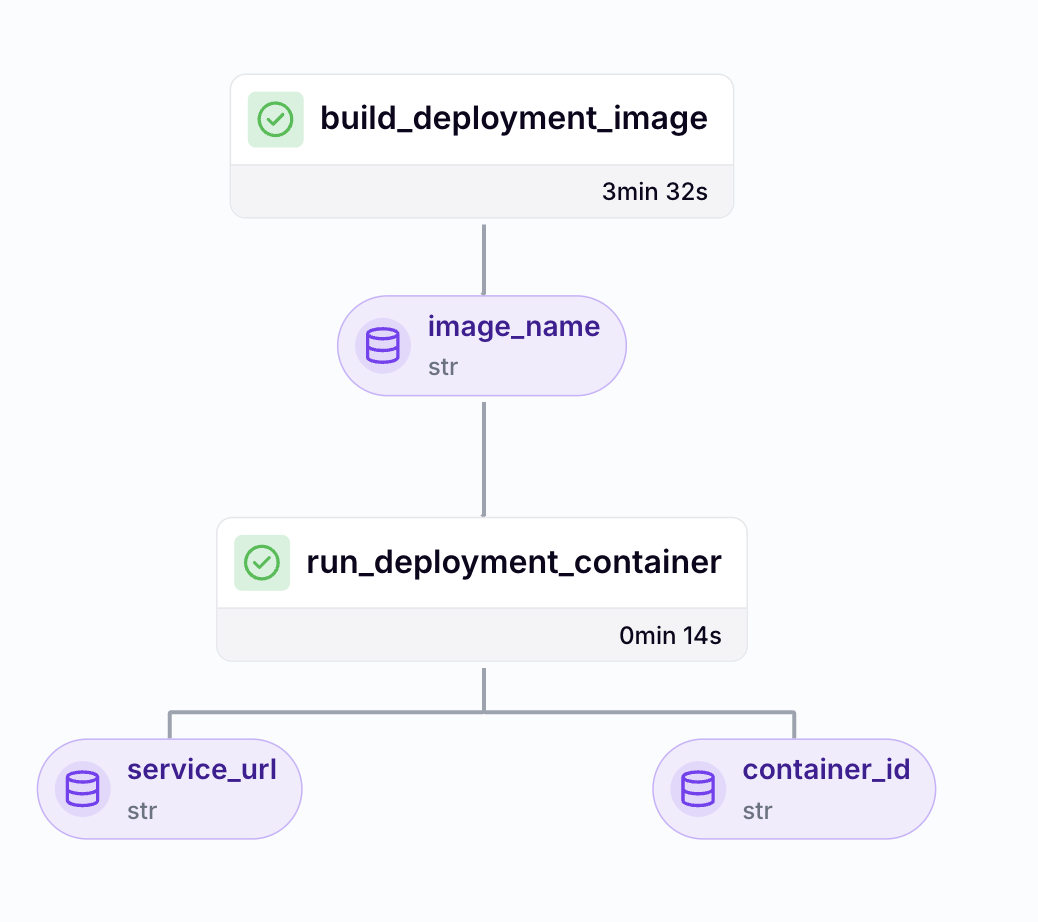
Let’s walk through a simplified deployment pipeline that builds a Docker image and runs a FastAPI service based on a promoted model:
Step 1: Building a Deployment Image
We define a pipeline step that packages our model, preprocessing logic, and service code into a self-contained Docker image:
@step(
enable_cache=False
) # Avoid caching image builds unless inputs are identical
def build_deployment_image(
model_name: str,
model_stage: str,
) -> Annotated[str, "image_name"]:
"""Builds a Docker image for the FastAPI deployment service."""
# Define image name based on model name and stage
image_name = f"local-deployment-{model_name}:{model_stage}"
docker_utils.build_image(
image_name=image_name,
dockerfile="/app/api/Dockerfile",
build_context_root="/app/api",
)
return image_nameThis step ensures the image is versioned and tied to the exact model and preprocessing artifacts used during training.
Step 2: Running the Container
The next step spins up the containerized service:
@step(enable_cache=False) # Avoid caching container runs
def run_deployment_container(
zenml_server_url: str,
zenml_api_key: str,
model_name: str,
model_stage: str,
image_name: str,
model_artifact_name: str = "sklearn_classifier",
preprocess_pipeline_name: str = "preprocess_pipeline",
host_port: int = 8000,
container_port: int = 8000,
) -> Tuple[
Annotated[str, "container_id"],
Annotated[str, "service_url"],
]:
"""Runs the Docker container for the model deployment service and logs deployment metadata."""
# Define a unique container name based on model name and stage
container_name = (
f"zenml-deployment-{model_name}-{model_stage}".lower().replace(
"_", "-"
)
)
# Run the container
container = client.containers.run(
image=image_name,
name=container_name,
environment=env_vars,
ports={f"{container_port}/tcp": host_port},
detach=True, # Run in background
restart_policy={"Name": "unless-stopped"}, # Restart if it crashes
)
container_id = container.id
service_url = f"http://localhost:{host_port}"
# Log metadata
log_metadata(
metadata={
"deployment_info": {
"deployed_at": datetime.datetime.now().isoformat()
}
},
model_name=model_name,
model_version=model_stage,
)
return container_id, service_urlThis step logs deployment metadata (container ID, URL, timestamp) into ZenML, creating a traceable snapshot** **of what was deployed, when, and from where.
Tying It All Together in a Deployment Pipeline
@pipeline(enable_cache=False) # Deployment operations shouldn't be cached
def local_deployment(
model_name: str,
model_stage: str = "production",
# ...
):
"""Deploy a model as a containerized FastAPI service."""
# step 1: Build the deployment image
image_name = build_deployment_image(
model_name=model_name,
model_stage=model_stage,
)
# step 2: Deploy the container
container_id, service_url = run_deployment_container(
# ...
)Implementing Model Promotion Systems
While deploying models is critical, equally important is determining which models should reach production in the first place. In traditional ML workflows, this decision often relies on informal team discussions or manual comparisons—introducing unnecessary risk for critical applications.
An automated model promotion system applies objective criteria to determine which models reach production. A Model Control Plane can serve as a model registry, version manager, and lifecycle tracker, enabling:
- Versioning: Tracking all promoted models within a pipeline with full lineage and metadata
- Promotion Logic: Enabling models to be promoted to staging, production, or custom stages based on objective criteria
- Deployment Integration: Defining deployments declaratively, ensuring reproducibility and auditability
Models vs. Model Control Plane: When we refer to a “Model” in the context of a Model Control Plane, we’re talking about a unifying business concept that tracks all components related to solving a particular problem — not just the technical model file (weights and parameters) produced by training algorithms. A Model Control Plane organizes pipelines, artifacts, metadata, and configurations that together represent the full lifecycle of addressing a specific use case.
Here’s an example step that handles promotion by evaluating a new model’s metrics against the current production baseline:
@step
def model_promoter(accuracy: float, stage: "production" = "production") -> bool:
"""Conditionally promote a model to production."""
is_promoted = False
if accuracy < 0.8:
logger.info(f"Model accuracy {accuracy*100:.2f}% is below 80%! Not promoting model.")
else:
# Get the model in the current context
current_model = get_step_context().model
# Compare with existing production model if any
client = Client()
try:
stage_model = client.get_model_version(current_model.name, stage)
prod_accuracy = stage_model.get_artifact("sklearn_classifier").run_metadata["test_accuracy"]
if accuracy > prod_accuracy:
# If current model has better metrics, promote it
current_model.set_stage(stage, force=True)
is_promoted = True
except KeyError:
# If no model exists in production, promote current one
current_model.set_stage(stage, force=True)
is_promoted = True
return is_promotedThe power of this approach lies in the automatic tracking and versioning of every model and pipeline run behind the scenes. This translates informal practices (“this model seems good enough”) into codified quality standards that align with organizational expectations for evidence-based decision making.
One key advantage of using a dedicated Model Control Plane over traditional model registries is the decoupling from experiment tracking systems. This means you can log and manage models even if they weren’t trained via a specific pipeline—perfect for integrating pre-trained or externally produced models.
| Feature | Traditional Model Registry | ZenML Model Control Plane |
|---|---|---|
| Model versioning & staging | ✅ | ✅ |
| Requires experiment tracker | ✅ | ❌ (fully decoupled) |
| Centralized UI & dashboard | ❌ (often external) | ✅ built-in ZenML UI (Pro users) |
| Manual model logging | ❌ | ✅ (supports CLI and programmatic) |
| Pipeline + registry integration | Limited | ✅ tightly integrated |
The API Interface: Where ML Meets Real-World Applications
Once models are deployed and promoted, they need to be accessible to end users through a reliable API. Here’s how a well-designed FastAPI service ensures consistent preprocessing, proper error handling, and comprehensive logging:
@app.post("/predict", response_model=PredictionResponse)
async def predict(payload: FeaturesPayload):
"""Make predictions using the loaded model with preprocessing."""
model = app_state.get("model")
preprocess_pipeline = app_state.get("preprocess_pipeline")
if model is None:
logger.error("Model not loaded.")
raise HTTPException(status_code=503, detail="Model not loaded.")
try:
# Convert input and apply preprocessing if available
data_to_predict = [payload.features]
if preprocess_pipeline is not None:
try:
data_to_predict = preprocess_pipeline.transform(data_to_predict)
except Exception as e:
logger.warning(f"Preprocessing failed: {e}. Using raw input.")
# Make prediction
prediction_result = model.predict(data_to_predict)
prediction_value = prediction_result[0] if isinstance(prediction_result, (list, np.ndarray)) else prediction_result
# Log prediction metadata
try:
log_metadata(
metadata={{
"prediction_info": {{
"timestamp": datetime.now().isoformat(),
"input": convert_to_serializable(payload.features),
"prediction": convert_to_serializable(prediction_value),
}}
}},
model_name=MODEL_NAME,
model_version=MODEL_STAGE,
)
except Exception as log_error:
logger.warning(f"Failed to log prediction metadata: {log_error}")
return PredictionResponse(prediction=convert_to_serializable(prediction_value))
except Exception as e:
logger.error(f"Prediction failed: {e}", exc_info=True)
raise HTTPException(status_code=500, detail=f"Prediction error: {str(e)}")This endpoint showcases several critical best practices:
- Bundled preprocessing: The service automatically applies the same transformations used during training
- Graceful degradation: If preprocessing fails, the service falls back to using raw input
- Type conversion: Handling the conversion of ML outputs to properly serializable types
- Comprehensive logging: Each prediction is logged with inputs, outputs, and metadata
The Real Value Proposition
What does this technical implementation mean for business stakeholders? Consider a domain expert using a deployed ML system in practice:
When they submit data for classification or prediction, they’re interacting with a system where every component—from data preprocessing to model selection to prediction logging—has been systematically verified. The model they’re using has been automatically vetted against minimum performance thresholds and compared to previous versions to ensure improvement.
Perhaps most importantly, if a prediction later needs review, the system provides complete traceability from that specific prediction back through the model version, its training data, validation metrics, and development code. This comprehensive lineage builds the foundation of trust that’s essential for adoption.
Scaling Beyond Local Implementation
While we’ve focused on a relatively simple local deployment scenario, these principles transfer readily to more complex enterprise environments. The same patterns can be extended to target Kubernetes clusters or cloud-managed ML services. The model promotion system can incorporate additional domain-specific metrics like fairness assessments or robustness measures. The prediction API can be enhanced with explainability features.
The core insight remains consistent: treating deployment with the same systematic rigor applied to model development creates a foundation for reliable, traceable machine learning in production.
Next Steps
The journey from promising algorithm to trusted production tool is challenging, but with systematic deployment pipelines and evidence-based promotion systems, it’s a journey that more ML projects can successfully complete.
Try It Yourself!
We built this ML deployment project to showcase practical, accessible MLOps and it’s available in the zenml-projects repo on our GitHub. The instructions to try it out are in the README. We plan to add more deployment patterns going forward, so keep an eye out.
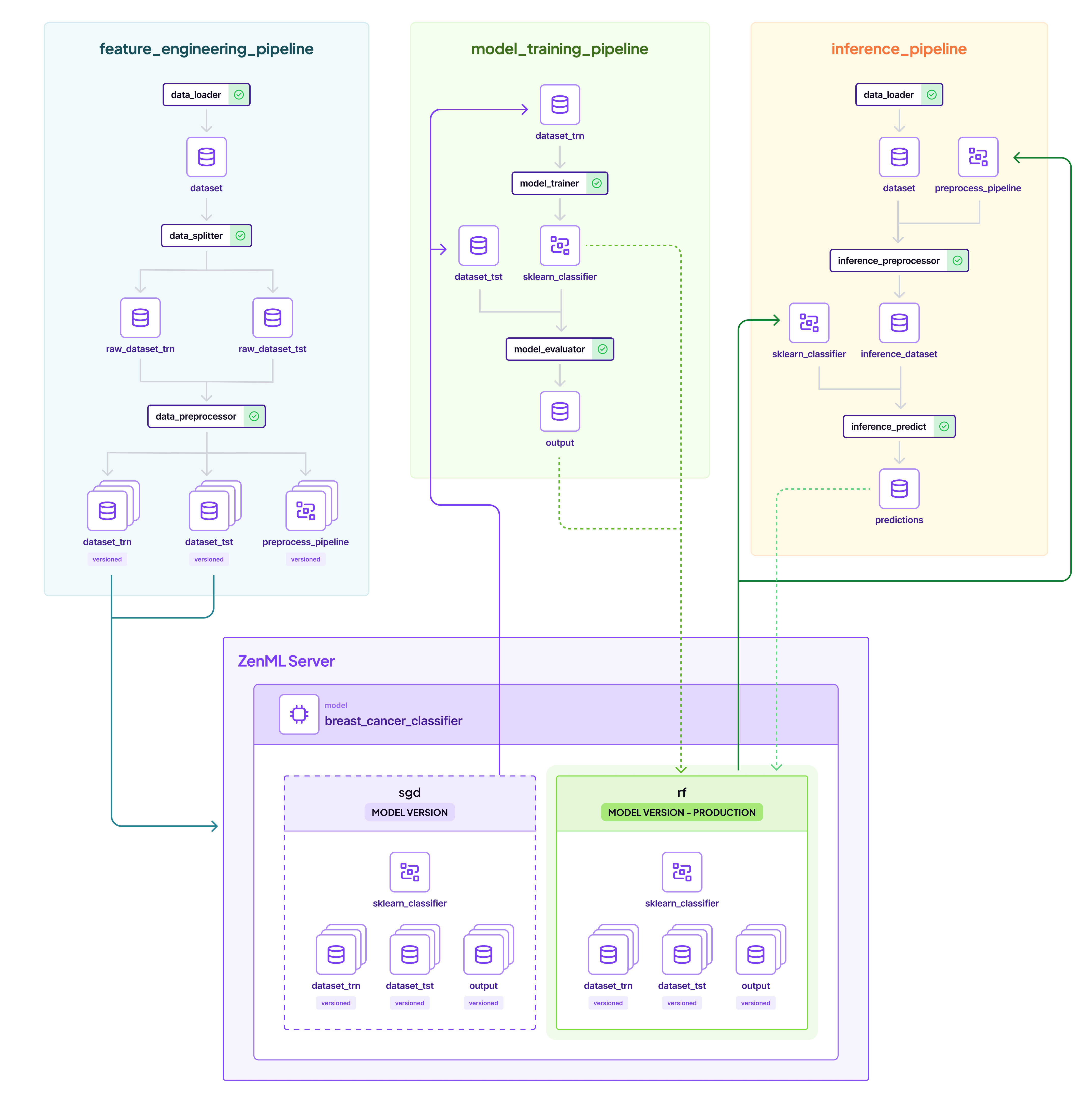
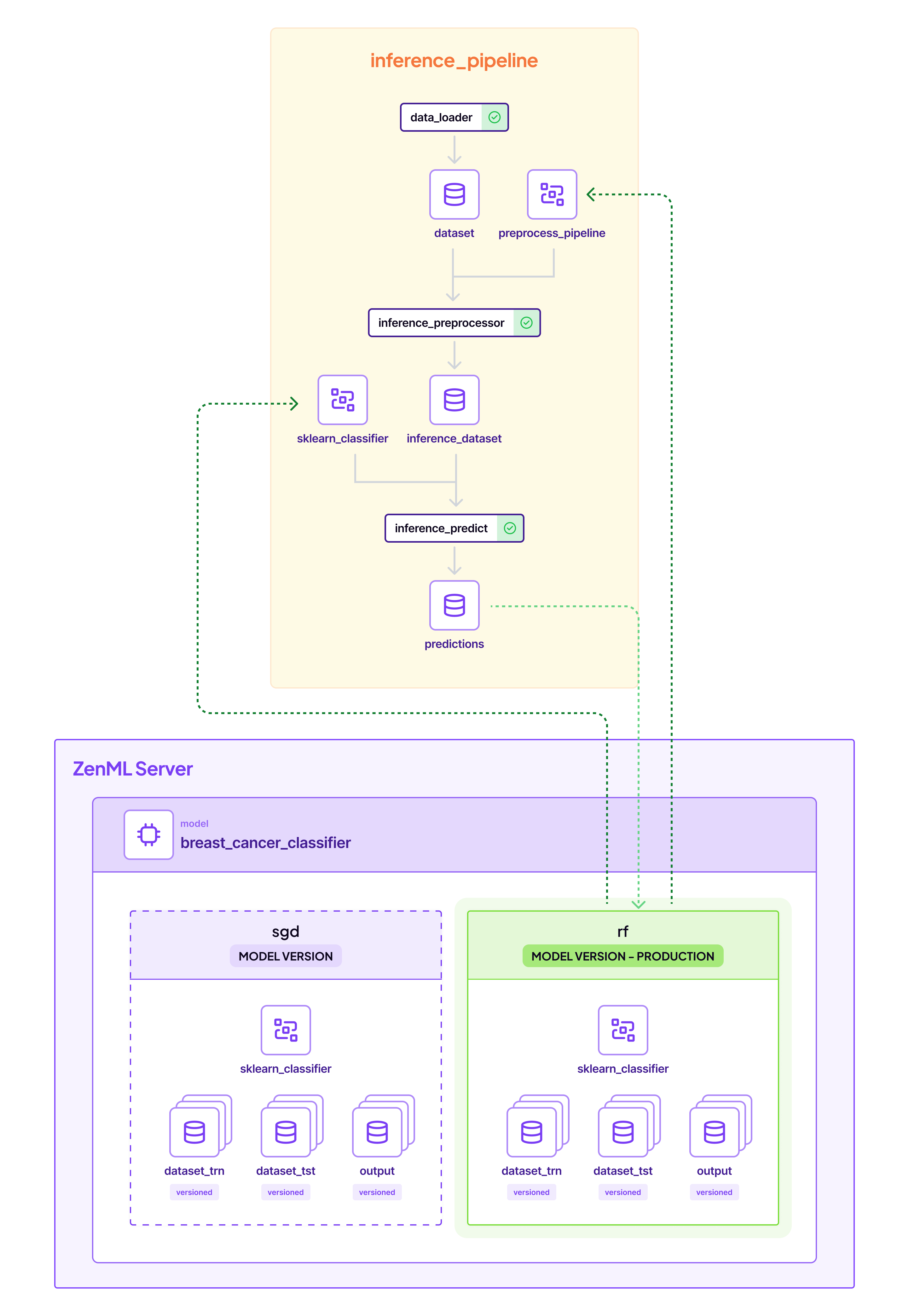
With ZenML, all of the pipelines are tracked in the dashboard. The pipeline overview shown in the screenshot above demonstrates how feature engineering, model training, and inference pipelines connect through the ZenML Server, with clear visibility of model versions and their promotion status. You can see how the entire ML lifecycle is automatically documented, giving you full traceability from data preparation through training to deployment.