
![Why ML in production is (still) broken - [#MLOps2020]](https://assets.zenml.io/webflow/64a817a2e7e2208272d1ce30/79950cfa/65316d2bc051413294285f1e_mlopsworldthumbnail.png)
On this page
Last updated: November 3, 2022.
Just a few days ago, I was able to share my thoughts on the state of Machine Learning in production, and why it’s (still) broken, on the MLOps World 2020. Read on for a writeup of my presentation, or checkout the recording of the talk on Youtube.
From research to production
By now, chances are you’ve read the famous paper about hidden technical debt by Sculley et al. from 2015. As a field, we have accepted that the actual share of Machine Learning is only a fraction of the work going into successful ML projects. The resulting complexity, especially in the transition to “live” environments, lead to large amounts of failed ML projects never reaching production.
Figures on the scope of the problem vary. Forbes and Venturebeat talk about 87%, Gartner claims 85%. Less important than a precise figure is the fundamental fact behind them: Getting ML projects from research to production is hard.
A crucial factor for ML models crashing and burning in production is that ML systems are inherently more complex than more traditional applications. For the latter, code is the only thing that affects the behavior of a system. For the former, code and data combined affects how the system behaves. Unfortunately, data is notoriously hard to wrangle with, and can change in unexpected ways - leading to ML teams naturally accumulating dangerous technical debt as they solve short-term problems.
Managing technical debt is a well-understood paradigm of “traditional” software engineering. We manage dependencies and code through explicit versioning to ensure their impact on a system stays within a defined scope. Following established practises like writing tests and abstractions, continuous refactoring and documentation will always have an immediate positive impact on ML projects.
This is, in large, due to technical debt. However, it won’t solve the source of a large portion of technical debt of ML: Data directly affects the behavior of the system. When data changes, your models AND your architecture need to adapt.
Accumulation of technical debt
On the path from first explorations to production systems projects accumulate technical debt. Let’s take a look at an exemplary progression. Each step of your maturing project incentivizes you to solve a different problem.
- You start out explorative in jupyter notebooks, and eventually end up with a first well-performing model.
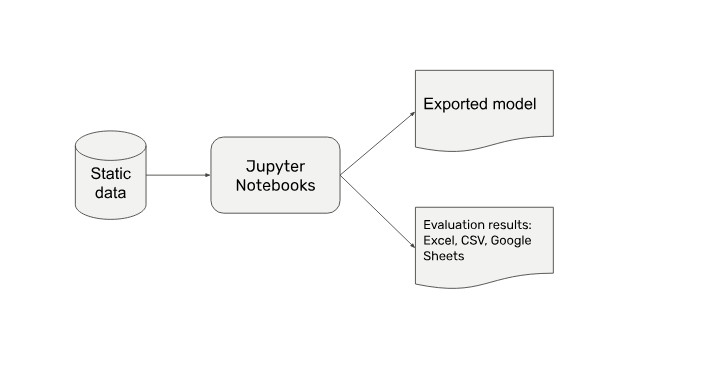
- That model needs to be deployed, right? To preserve speed and keep complexity low you wrap it in a Flask-based API container, pass on the API endpoint, done.
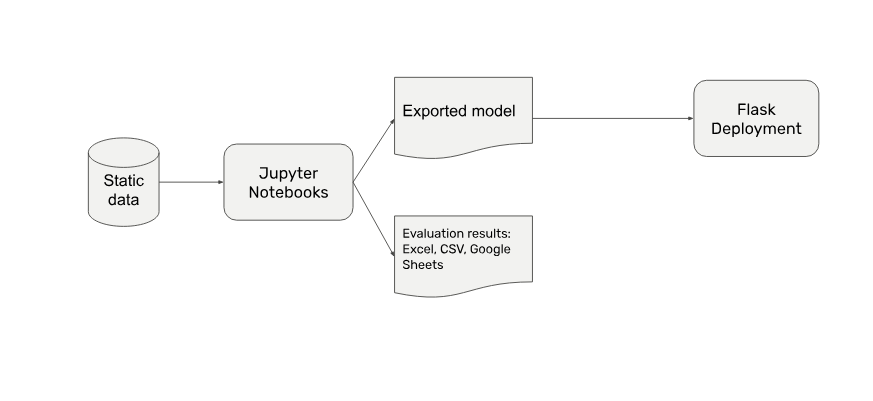
- But wait, actually your data will change over time. You’re not just doing a one-of batch inference, so your deployment needs to be connected to the newly incoming data. New data might change in its structure, so you’re also adding monitoring for input and output distributions.
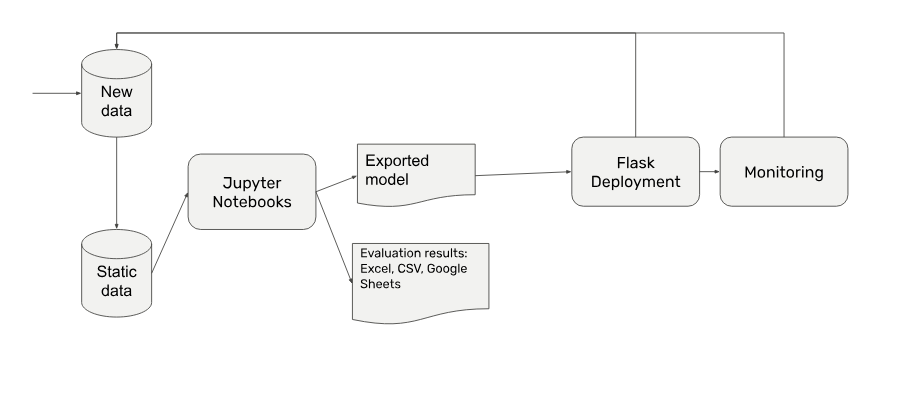
- The team, on top of that, will also start to refactor its codebase, because your needs have by far outgrown what you can do in Jupyter Notebooks.
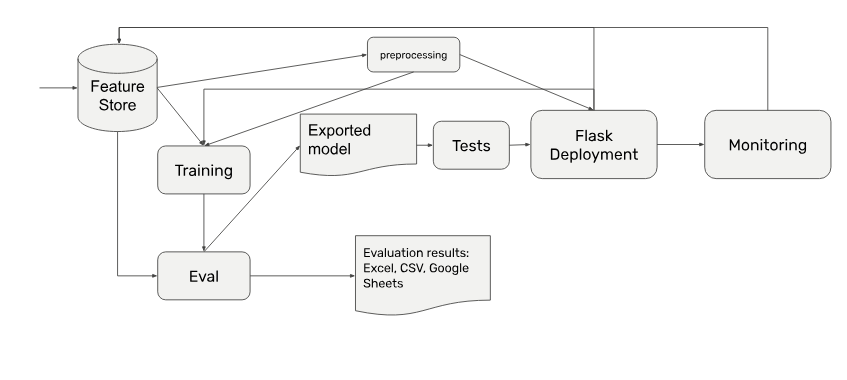
- By now you’re also facing the challenge to orchestrate all that preprocessing and training across resources. That beefy VM you were running your code on simply doesn’t cut it anymore.
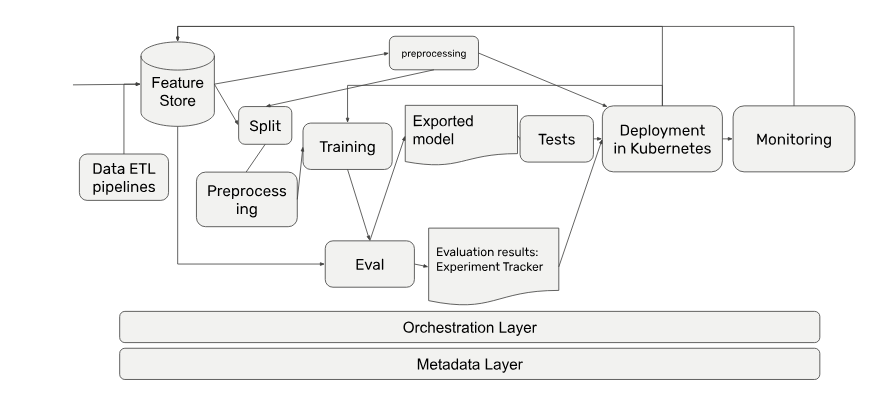
As you progress you’re further dividing your codebase in more granular functions - splitting and preprocessing is separated, eval becomes semi-automated, your ETLs become standardized, and metadata plays a decisive role for your architecture.
The resulting architecture is grown into a state of complexity that can’t be deployed by new team members. Changes impact your entire codebase. Your deploys get less frequent by the day. Eventually, you’re facing either costly rewrites or disproportionate efforts of maintenance.
Worst of it all? You did everything right at each step of the way. Ad-hoc necessities and spontaneous fires dictated the incentives for your engineering decisions. Unfortunately, these incentives are misaligned with the actual incentive of building a production-ready system.
There is hope
The picture is not as bleak as it was a few years ago. There are solutions popping up everywhere. The FAANGs (plus Uber) of the world are sharing their experiences openly.
The industry is quickly converging on agreed upon components that are integral to a production ML system. A state-of-the-art high level architectural diagram for a production ML system can be pictured now clearly below:
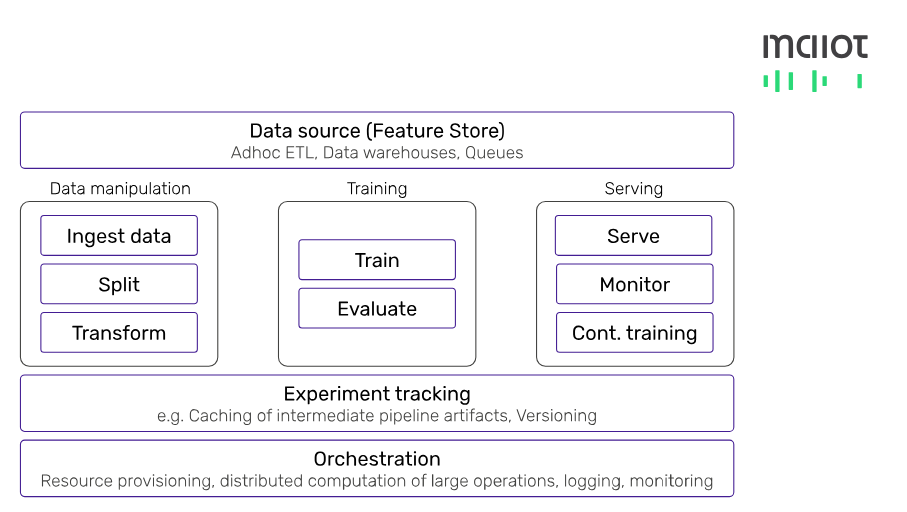
To avoid train-serve drift, ML companies increasingly centralize their data in feature stores. Next to classical database systems (MySQL, Postgres, DynamoDB) and key-value stores (HiveDB) there are also a number of proprietary systems are entering the market with powerful feature level automations. The people behind Uber’s Michaelangelo now raised $20 million for Tecton, and Logical Clocks is doubling down on their feature store.
In the middle layers there are more tools than ever before. Some range from solving individual steps like distributed data manipulation (Apache Beam, Spark), training (see spaCy, Ray) and monitoring (see Prometheus).
At the orchestration layer, the industry is now looking to solutions such as Airflow and Kubeflow, which gain steam every year. Individual pain points like complex model deployments now have solutions such as Seldon and Cortex. Finally, there are many great metadata tracking tools from easy-to-use ones like Weights&Biases or Comet ML to more complex ones like the TensorFlow ML Metadata project.
ZenML
Despite the ever growing MLOps landscape, there is still plenty of room for improvement. In particular, it is still challenging to comprehend, interconnect and maintain relevant tooling in a reliable production environment.
This is where ZenML comes in. Built as an end-to-end MLOps framework, it provides developers easy interfaces to production-ready data manipulation, training, serving, experiment tracking and orchestration layers. In addition, we put a focus on standardization, automation and comparability of ML pipelines.
To read more about ZenML head over to our website for more details. If you want to start using ZenML for your own ML production environment, contact us!


