

On this page
Last updated: November 3, 2022.
Data is the lifeblood that feeds machine learning models. The process of developing those models requires data in different forms. During the early lifecycle stages of any particular model, particularly when experimenting with different approaches, this data will get used repeatedly.
Machine learning model development is extremely iterative in this way. Data scientists are constantly repeating steps in slightly different combinations. Given that data often is imported or transformed in the course of these steps, it would be good to find a way to minimize wasted work. Luckily, we can use caching to save the day.

If we organize the steps of our model training smartly, we can ensure that the data outputs and inputs along the way are cached. A good way to think about splitting up the steps is to use the image of pipelines and the steps that are executed. For each step, data is passed in, and (potentially) gets returned. We can cache the data at these entry and exit points. If we rerun the pipeline we will only rerun an individual step if something has changed in the implementation, otherwise we can just use the cached output value.
Benefits of Caching
I hope some of the benefits of caching are clear to you now.
- 🔁 Iteration Efficiency - When experimenting, it really pays to have a high frequency of iteration. You learn when and how to course correct earlier and more often. Caching brings you closer to that by making the costs of frequent iteration much lower.
- 💪 Increased Productivity - The speed-up in iteration frequency will help you solve problems faster, making stakeholders happier and giving you a greater feeling of agency in your machine learning work.
- 🌳 Environmental Friendliness - Caching saves you the needless repeated computation steps which mean you use up and waste less energy. It all adds up!
- $ Reduced Costs - Your bottom-line will thank you! Not only do you save the planet, but your monthly cloud bills might be lower on account of your skipping those repeated steps.
Get caching for free with ZenML pipelines
ZenML takes care of caching the artifacts that either come in or are output from the steps of your machine learning pipeline. ZenML builds on the concept of a Metadata Store and currently we use MLMetadataStore to power this functionality. This foundational practice of building pipelines made up of steps - with some kind of way to track the metadata around these steps - is necessary for caching to work.
These things are often made clearer with an actual example, so let’s jump into the MNIST dataset. (Follow the steps in our examples directory to get this running on your local machine.)
On the first run, we can visualize the steps of the pipeline as having all completed. None are cached yet, as you would expect.
# Initialize a pipeline run
run_1 = mnist_pipeline(
importer=importer_mnist(),
normalizer=normalizer(),
trainer=tf_trainer(config=TrainerConfig(epochs=1)),
evaluator=tf_evaluator(),
)
# Run the pipeline
run_1.run()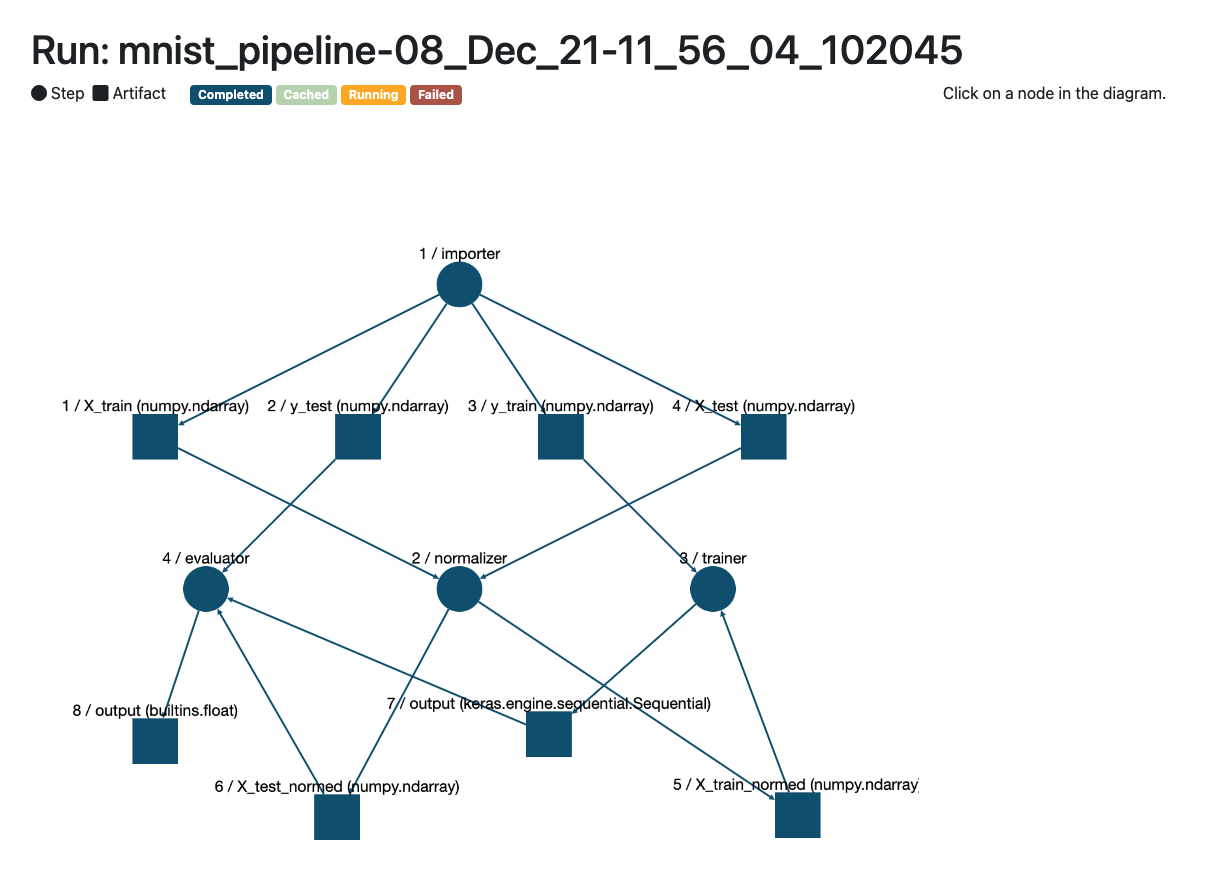
Here’s what the pipeline lineage tracking visualizer looks like
When we run the pipeline again, you can see that most of the steps have been cached, aside from the trainer step which is different because we change the code slightly so that it will run for two epochs:
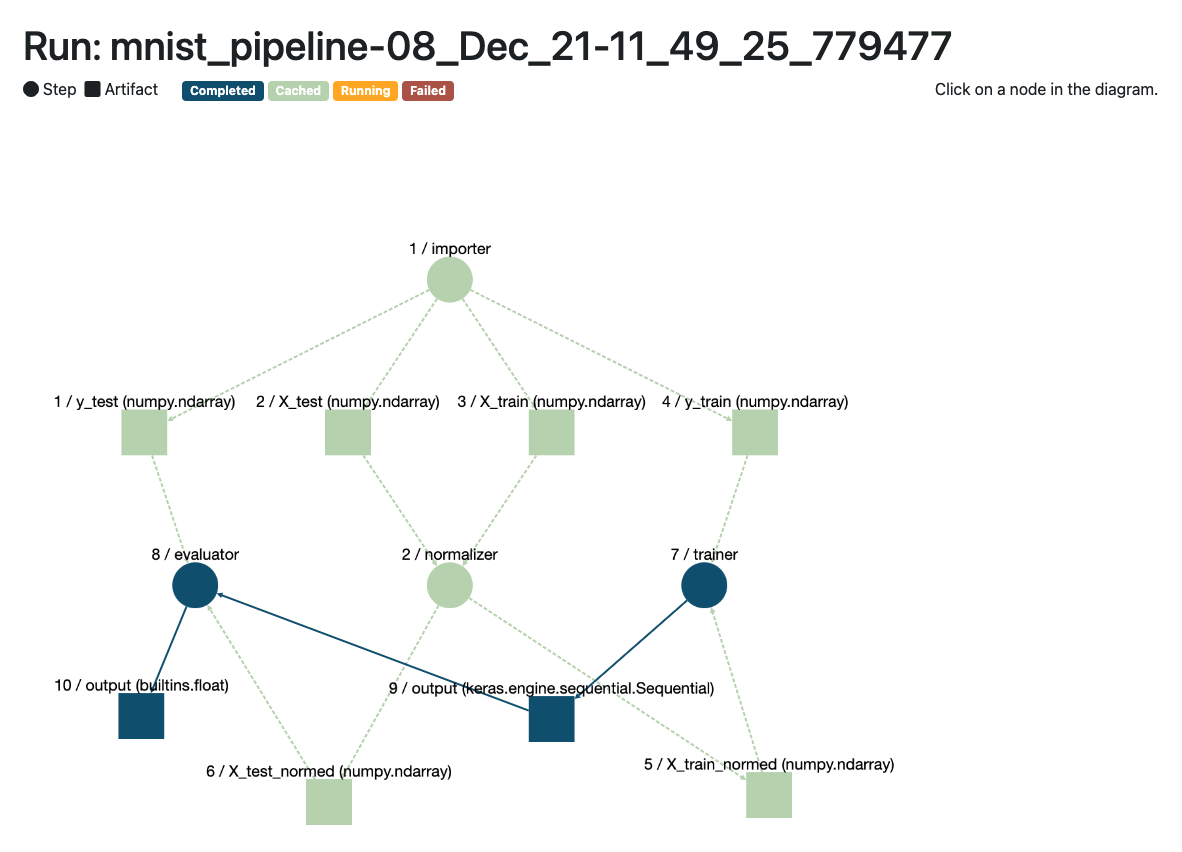
Here’s what the pipeline lineage tracking visualizer looks like
In this case, caching does save us some time even though the steps weren’t extraordinarily compute-intensive to start with.
Step Run1 Execution (s) Run2 Execution (s) Speed Increase importer_mnist 1.165 0.018 **64x **normalizer 1.581 0.018 87x
Think how much time it will save you in your complex feature engineering pipelines!
Caching is turned on by default. The cache for that particular step’s artifact is then invalidated whenever the code signature for the step changes, or when caching is manually disabled by setting the @step decorator’s enable_cache parameter to False. We compare the two steps with a simple hashing function to see whether any changes have taken place.
Plug
If you like the thoughts here, we’d love to hear your feedback on ZenML. It is open-source and we are looking for early adopters and contributors! And if you find it is the right order of abstraction for you/your data scientists, then let us know as well via our Slack — looking forward to hearing from you!
[Photo by Juliana Kozoski on Unsplash]


