
On this page
The Hidden Costs of MLOps Non-Standardization: A Data Team’s Journey
In the fast-paced world of machine learning operations, one of the most overlooked challenges isn’t technical complexity or computational resources - it’s the seemingly simple matter of standardization. As ML teams grow and projects multiply, the lack of standardized practices can create unexpected bottlenecks and communication challenges that ripple throughout an organization.
The Standardization Paradox
When data science teams are small and projects are few, ad-hoc approaches to ML development seem perfectly adequate. Each data scientist can work in their preferred way, using their favorite tools and methodologies. However, this flexibility comes with a hidden cost that becomes apparent as teams scale and projects multiply.
Consider these common scenarios:
- Different projects using completely different code structures
- Varying deployment methodologies across teams
- Inconsistent artifact storage and versioning approaches
- Platform teams struggling to provide consistent support
The Platform Team’s Dilemma

One of the most challenging aspects of MLOps is the relationship between platform teams and embedded data scientists. Platform teams often find themselves in a difficult position: they need to provide infrastructure support and operational guidance, but without standardization, each project requires a unique approach. This creates several issues:
- Knowledge Transfer Barriers: Platform engineers must learn multiple project structures
- Reduced Efficiency: Support becomes increasingly time-consuming
- Technical Debt: Different approaches lead to maintaining multiple systems
- Slower Innovation: Time spent understanding different setups could be used for improvements
The Data Movement Challenge
Modern ML operations often involve complex data workflows, particularly when dealing with data warehouses like Snowflake, BigQuery, or Redshift. A common challenge is optimizing data movement between storage systems while maintaining performance and cost efficiency.
Best practices for handling data movement include:
- Minimizing unnecessary data transfers between systems
- Utilizing native computing capabilities of data warehouses
- Implementing consistent artifact storage strategies
- Maintaining clear lineage and versioning
Building a Path Forward
1. Start with New Projects
Rather than attempting to standardize everything at once, focus on new projects as opportunities to implement better practices. New projects have several advantages:
- No legacy technical debt
- Team members are more open to new approaches
- Easier to demonstrate value
- Lower risk of disrupting existing workflows
2. Focus on Infrastructure Abstraction
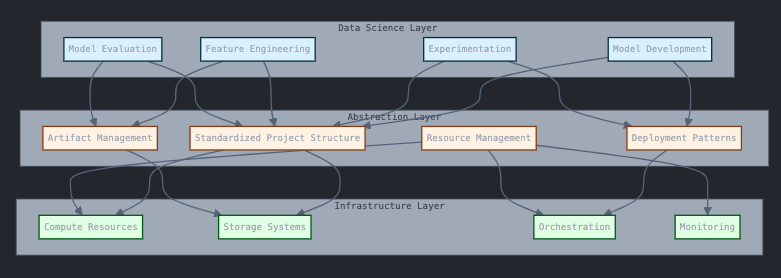
The goal should be to create an abstraction layer that allows data scientists to focus on their core work while maintaining operational excellence. This includes:
- Standardized project structures
- Consistent deployment patterns
- Unified artifact management
- Clear interface between data science and infrastructure
3. Secure Organizational Buy-in
For standardization efforts to succeed, you need:
- Leadership support
- Clear demonstration of value
- Measurable improvements in efficiency
- Gradual implementation strategy
Looking Ahead
The journey toward MLOps standardization is rarely straightforward. It requires patience, strategic thinking, and often a cultural shift within the organization. However, the benefits of standardization become increasingly apparent as teams scale and projects multiply.
Success in MLOps standardization isn’t about enforcing rigid rules - it’s about creating a framework that makes it easier for teams to collaborate, innovate, and deliver value. By focusing on gradual implementation, starting with new projects, and securing proper organizational support, teams can build a more sustainable and efficient ML development environment.
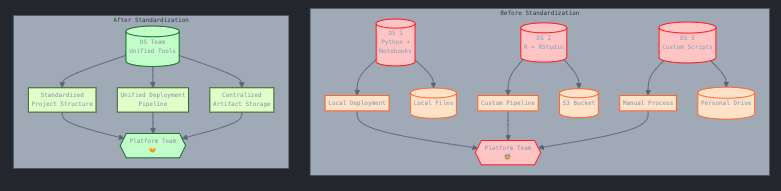
Remember: The goal isn’t to restrict creativity but to channel it more effectively through established patterns that benefit the entire organization. The time invested in standardization today pays dividends in reduced complexity, better collaboration, and faster delivery tomorrow.


