Enhance your machine learning workflows by integrating Prodigy, a modern annotation tool, with ZenML. This powerful combination enables efficient data labeling, data inspection, and error analysis, streamlining your ML pipeline and improving model performance.
# zenml annotator register prodigy --flavor prodigy
# optionally also pass in --custom_config_path="&alt;PATH_TO_CUSTOM_CONFIG_FILE>"
# zenml stack register prodigy -o default -a default -an prodigy --set
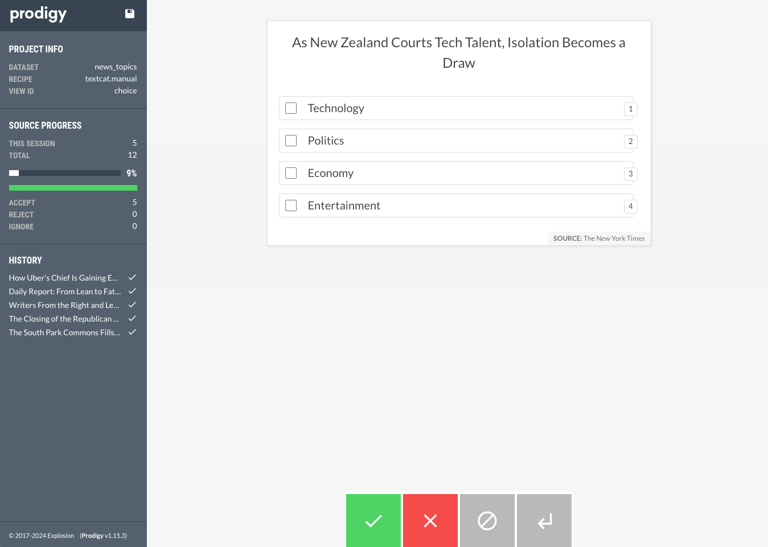
# wget https://raw.githubusercontent.com/explosion/prodigy-recipes/master/example-datasets/news_headlines.jsonl
# Now annotate your data
# zenml annotator dataset annotate your_dataset --command="textcat.manual news_topics ./news_headlines.jsonl --label Technology,Politics,Economy,Entertainment"
# access the data later on using Python in your pipelines
from zenml import step
from zenml.client import Client
@step
def import_annotations() -> List[Dict[str, Any]]:
zenml_client = Client()
annotations = zenml_client.active_stack.annotator.get_labeled_data(dataset_name="your_dataset")
# Do something with the annotations
return annotations
Expand your ML pipelines with more than 50 ZenML Integrations
