Integrate the powerful XGBoost library seamlessly into your ZenML pipelines for efficient and effective gradient boosting. This integration enables you to leverage XGBoost's algorithms within your ML workflows, making it easier to train, tune, and deploy highly accurate models.
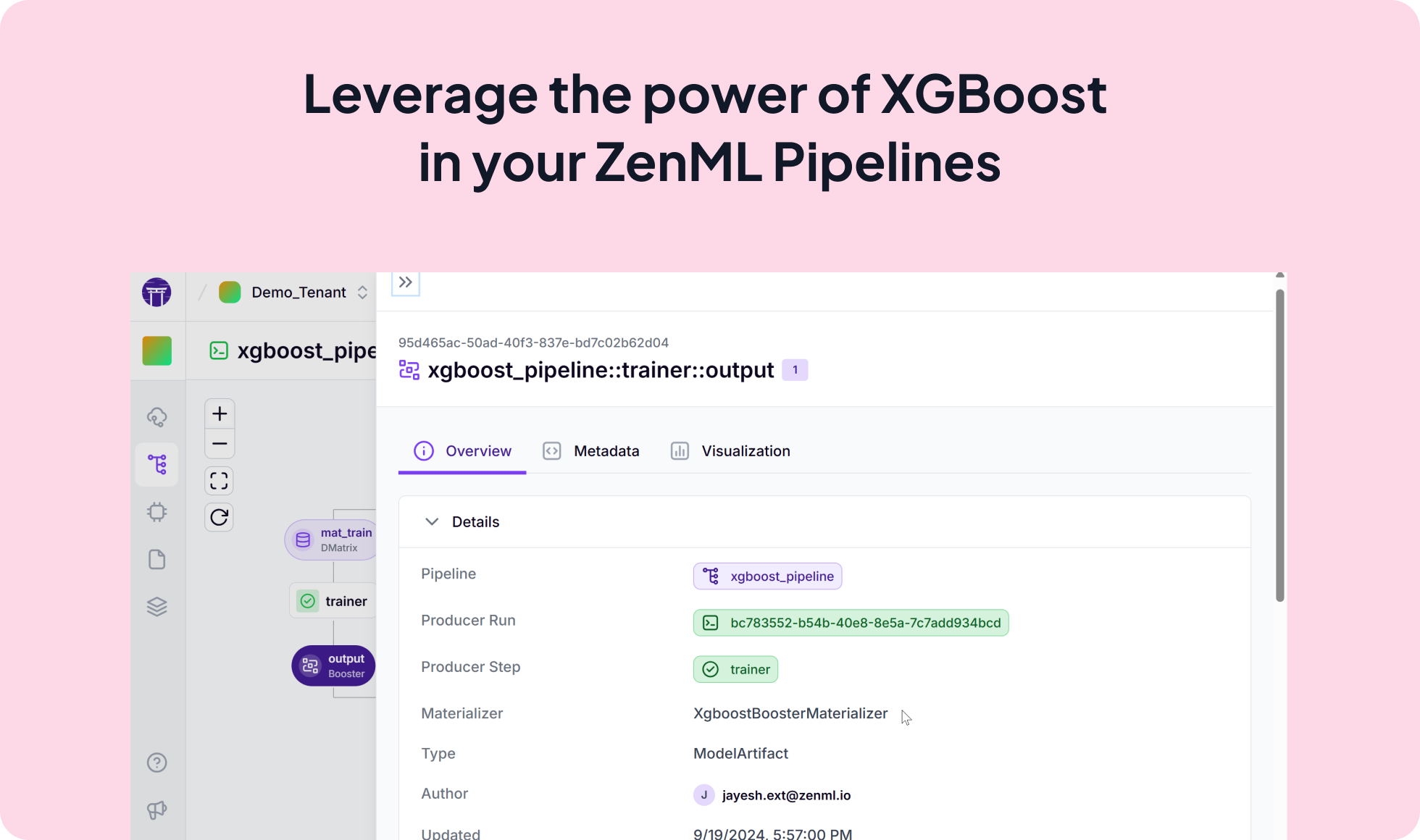
from zenml import pipeline, step
import xgboost as xgb
@step
def trainer(
mat_train: xgb.DMatrix,
...
) -> xgb.Booster:
"""Trains a XGBoost model on the data."""
params = {
"max_depth": max_depth,
"eta": eta,
"objective": objective,
}
return xgb.train(params, mat_train, num_round)
@pipeline(enable_cache=True)
def xgboost_pipeline():
"""Links all the steps together in a pipeline."""
mat_train, mat_test = data_loader()
model = trainer(mat_train)
predictor(model, mat_test)
if __name__ == "__main__":
# Run the pipeline
xgboost_pipeline()
Expand your ML pipelines with more than 50 ZenML Integrations
