

On this page
The rise of Large Language Models (LLMs) has transformed the landscape of software development, introducing capabilities that we haven’t seen before– from crafting human-like conversations to generating creative content and extracting insights from vast amounts of text.
But this also means that the deterministic outputs and clear-cut test cases that we have been used to, so far, won’t apply anymore since generation is now involved.
The truth is, working with LLMs feels a bit like trying to tame a smart but unpredictable power. Personally, I’ve had my moments of frustration trying to get my LLMs to follow the instructions I give, consistently. One moment it’s solving complex problems with remarkable accuracy, and the next it’s confidently performing actions you explicitly instructed it not to. This unpredictability creates a unique challenge: how do we ensure these powerful models are actually doing what we want them to do?
This is where LLM evaluation becomes not just important, but crucial.
Why Evaluation Matters Now More Than Ever
In LLM systems, evaluation involves the following:
- Ensuring Reliability: Can your users trust the outputs your LLM-powered application produces?
- Managing Risks: From hallucinations to biased responses, LLMs can go wrong in ways traditional software never could
- Measuring Progress: Without proper evaluation, updating your prompts or switching models feels like shooting in the dark
- Building Trust: In a world where AI safety is increasingly under scrutiny, being able to demonstrate responsible AI usage is becoming a business imperative
The Current Landscape
Today, we’re seeing many ways in how organizations approach LLM evaluation:
- Hyperscalers (AWS, Azure, GCP) have integrated evaluation in their MLOps/LLMOps platform offerings and advocate for a progressive approach: start small with manual evaluation, then gradually build automated pipelines for production.
- Specialized Platforms (LangSmith, Langfuse, Evidently, Braintrust and more) offer libraries (and Dashboards) designed specifically for LLM evaluation, with their own set of metrics and templates to ease usage.
- In-house Solutions where organizations build custom evaluation frameworks tailored to their specific needs. These could be as simple as some scripts you run before deploying to automated CI/CD pipelines built around your product.
This fragmentation in approaches and tools makes it crucial for teams to understand their options and make informed decisions about their evaluation strategy.
Understanding LLM Evaluation
LLM evaluation, at its core, involves the following three concepts, and every tool and library offers variations of the same.
- Dataset: This is the data you run your evaluations against. Entries in the dataset that you create can have an input (which corresponds to the test prompt), and an output (if you have a ground truth to compare against). The way this Dataset is designed varies from tool to tool.
- An LLM function: This is the function that takes your dataset as input and produces inferences and is typically backed by an LLM call.
- Evaluators: These are a set of metrics (some tools call them scorers) that your evaluations are based on. Common scorers could be correctness, PII, and others that you can find in the section above.
To make things clearer, here is an example of how LangSmith does evaluations through their SDK:
from langsmith.evaluation import evaluate
results = evaluate(
lambda inputs: label_text(inputs["text"]), # your input function
data=dataset_name, # the dataset
evaluators=[correct_label], # the evaluators or scorers
experiment_prefix="Toxic Queries",
description="Testing the baseline system.",
)You will notice that the evaluate function takes in
- an input function that is usually your LLM call
- a set of evaluators, or scorers that are used to evaluate outputs
- a dataset that contains examples to run evaluations for.
Types of Evaluations

Before diving into what metrics are commonly used to evaluate LLMs, it helps to build a mental image of how they are grouped.
- Model-based evaluations: All evaluations that are backed by an LLM. These could involve checking sentiment, toxicity, correctness based on ground truth, and any other custom “LLM-as-judge” use cases you want to build for your dataset.
- Other traditional evaluation techniques: These involve tests like length of produced output, pattern recognition in text and other metrics based on statistics (BLEU, ROUGE) and heuristics (Levenshtein distance and so on).
In general, your evaluations should have a mix of these scorers along with some human oversight at crucial points of your pipeline. Almost all tools offer these metrics as templates that you can use straight away without worrying about the evaluation logic yourself. The sections below that compare these tools will talk about the options you get from them, in detail. Some common themes are as follows:
- Response quality and relevance
- Factual accuracy (correctness)
- Bias and fairness
- Personally Identifiable Information (PII)
- Safety and ethical considerations
- Performance and consistency
Challenges in Evaluating LLMs
Evaluation of LLMs begins right when you start using them. Anyone who has worked with building apps with LLMs is familiar with manually running some important prompts after every change you do, to test if your outputs still make sense. This approach works well on the outset but there are some problems:
- Non-deterministic performance: Running some evals manually and testing outputs can feel like guesswork as you can’t quantifiably say if things got better or worse. Maybe there are some use cases that are now performing worse than before.
- Tracking changes: Manual testing only goes so far. It would help if you had a track of what changes lead to what outputs and how your performance has fared over time.
- Automated pipelines are not easy to build: Even when you move to automate your evaluation process to counter the problems above, you are faced with uncertainty about how best to design your pipelines, what tools to use, and where to run them. Different providers have different approaches and there’s always a fear of getting locked into vendors.
The Evolution of Evaluation Approaches
There are many tools in the industry now that enable you to start with simple manual testing– eyeballing outputs for accuracy and also help you progress to more sophisticated evaluation pipelines that can automatically assess thousands of interactions across multiple dimensions.
From the AWS blog post on operationalizing LLM evaluations at scale:
While the experimentation phase may involve a straightforward process, transitioning to production requires customers to automate the process and enhance the robustness of the solution. Therefore, we need to deep dive on how to automate evaluation…
The key takeaway is to design solutions that use the best tools and libraries on the market and integrate them with a pipeline that automates as much work as possible (preferably from Day 1). You should also take care to make your pipeline modular so you can switch between providers and tools without much friction— this is crucial when you are experimenting and also because this space is evolving so fast, and you might feel like switching somewhere down the line.
Now let’s dive into all the available tooling options in the industry that you can leverage for your projects. We will start with the specialized LLM evaluation platforms and then see how the hyper-scalers (AWS, GCP, Azure) are handling this important part of an LLM application’s lifecycle.
Specialized LLM Evaluation Platforms
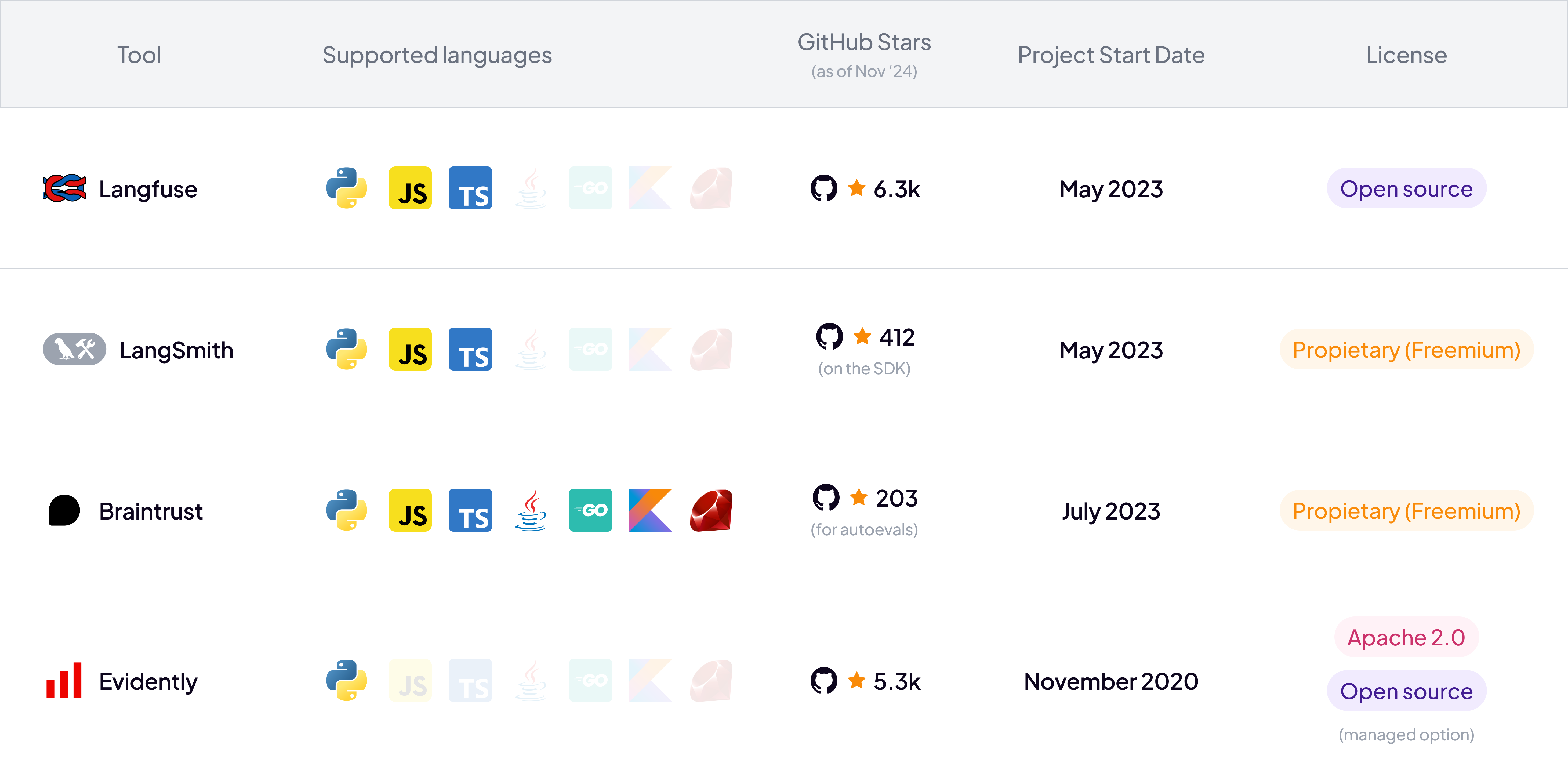
Langfuse
| Supported Languages | GitHub URL | GitHub stars (as of Nov ‘24) | Project Start Date | License |
|---|---|---|---|---|
| JS/TS, Python | 6.3k | May 2023 | Open source: |
From the Langfuse docs,
Langfuse is an open-source LLM engineering platform that helps teams collaboratively debug, analyze, and iterate on their LLM applications.
Key features
Langfuse offers
- observability through ingestion of logs (traces) from your LLM apps into their UI
- prompt management to effectively manage and version your prompts
- management of your datasets to run evaluations against.
- automated evaluations for your models with built-in and custom scorers
Evaluation methods
Langfuse supports the following evaluation methods:
- Model-based Evaluation (LLM-as-a-Judge): With this approach, an LLMs scores a particular session, trace, or LLM call in Langfuse based on factors such as accuracy, toxicity, or hallucinations.
- Manual Annotation / Data Labeling (in UI): With manual annotations, you can annotate a subset of traces and observations by hand. This allows you to collaborate with your team and add scores via the Langfuse UI.
- User Feedback: You can add explicit (thumbs up/down) and implicit (click rate, time spent on page) mechanisms to get feedback from users to serve as evaluation parameters.
- Custom scores: you can ingest custom evaluation metrics through their SDK/API.
Langfuse uses scores as a concept that evaluates your LLM outputs. You get some built-in scores by default (for example, in the LLM-as-a-judge use case, you get prompt templates for hallucinations, toxicity and more built-in) and you can also define your own methods. Read this page to learn how to do that.
Process
From what I’ve seen so far, Langfuse encourages a no-code approach to evaluation using the evaluations available in the Langfuse UI and there’s no support for running these built-in evals through other platforms like your own pipeline environments.
However, you can build external pipelines with your custom evaluation logic (for example, using other libraries like deepevals) and ingest traces and your scores into Langfuse to track them centrally. This essentially means using two libraries instead of one if you wish to custom build automated pipelines for your evaluation needs, but Langfuse offers more than just evaluation so it might make sense for some of you to take this route.
Pricing
Langfuse is open-source and can be run locally or use the self-hosted option (recommended for production).
If you don’t want to manage it yourself, there’s also the fully-managed platform that you can start using for Free and then pay as your usage increases. Check out the Pricing page for more details.
LangSmith
| Supported Languages | GitHub URL | GitHub stars (as of Nov ‘24) | Project Start Date | License |
|---|---|---|---|---|
| JS/TS, Python | Not open source. SDK available: | 412 (on the SDK) | May 2023 | Proprietary (Freemium) |
From the LangSmith docs,
LangSmith is a platform for building production-grade LLM applications. It allows you to closely monitor and evaluate your application, so you can ship quickly and with confidence.
Key features
LangSmith offers a platform that allows you to:
- observe your LLM calls as traces and runs (spans within traces): it makes it easy to log your function calls through decorators that you can put in your code, alongside many other options.
- evaluate LLM outputs based on datasets and a set of evaluators.
- manage and track prompts through the use of PromptTemplates.
- run online evaluations (like adding user feedback to your traces, labelling of responses and more) that happen automatically and asynchronously as you ingest data (say logs from your production app).
Evaluation methods
LangSmith supports the following evaluation methods:
- LLM-as-judge: These evaluators use LLMs to score outputs. They work by defining grading rules through a prompt (either your own or through templates). They can be reference-free (for example, toxicity) or use references (for correctness)
- Heuristic: These are hard-coded functions that perform computations to calculate a score. You can define them as functions and these can also be reference-free (checking for attributes like size, valid JSONs) or use a reference (like pattern matching or exact matches).
- Pairwise: These evaluators pick the better of two task outputs based upon some criteria. They can either use a heuristic (a deterministic function), an LLM (with a pairwise prompt) or a human.
- Human: LangSmith makes it easy for humans to review LLM outputs and traces in the UI and give their feedback.
Process
With LangSmith, you can choose from a range of off-the-shelf evaluators that span across the LLM-as-judge and statistical domains. Check this page for more information.
The SDK offers a simple way to do this in code, which also means that you can run this in any environment you wish to deploy your apps or pipelines in. The following code shows you an example of using a QA Chain-of-thought evaluator for a question-answering use case. The Dataset in LangSmith comprises an “inputs” and “outputs” dictionary which can be used in the context of reference-free or reference-based evaluations.
from langchain_openai import ChatOpenAI
from langchain_core.prompts.prompt import PromptTemplate
from langsmith.evaluation import LangChainStringEvaluator
eval_llm = ChatOpenAI(temperature=0.0, model="gpt-3.5-turbo")
cot_qa_evaluator = LangChainStringEvaluator("cot_qa", config={"llm": eval_llm})
evaluate(
lambda input: "Hello " + input["input"], # input function, typically an LLM call
data=dataset_name, # the dataset to run evals for
evaluators=[cot_qa_evaluator], # the built-in evaluator
)You can also define custom evaluators and use them in your evaluation code. Check this guide that shows you how you can define functions and then use them in the evaluators parameter of the evaluate function.
Building an automated pipeline
You can use the langsmith library with ZenML to build an automated pipeline that you can trigger on schedule or when certain events happen, for example. Check out this section of the blog post to learn how a pipeline and a LangSmith evaluation step might look like.
Pricing
LangSmith is not open-source but you can start for free and pay as your usage scales. They have plans for hobbyists, startups and enterprises (which includes the self-hosted version).
Check out the Pricing page for more details.
Braintrust
| Supported Languages | GitHub URL | GitHub stars (as of Nov ‘24) | Project Start Date | License |
|---|---|---|---|---|
| JS/TS, Python, Java, Go, Kotlin, Ruby | Not open source. SDK available: | 203 (for autoevals) | July 2023 | Proprietary (Freemium) |
From the Braintrust docs,
Braintrust is an end-to-end platform for building AI applications. It makes software development with large language models (LLMs) robust and iterative.
Key features
Braintrust offers an end-to-end platform that allows you to
- log, monitor and take actions on your LLM interactions. The logs are made available as traces and spans within traces.
- prototype with different models and prompts in their playground.
- evaluate how models and prompts are performing in production.
- manage and review data coming in from sources like your execution environments’ logs, your custom data in files or from user feedback.
- manage prompts, datasets, tools and custom scorers from the Braintrust UI.
- run online evaluations that happen automatically and asynchronously as you ingest data (say logs from your production app).
- use a single API to access ~100 proprietary and open-source models with features like caching (to save costs) and monitoring through Braintrust. This is possible through the Braintrust AI Proxy.
- experiment with tool calling with supported models easily by defining and pushing tools to Braintrust, which can then make them available to the LLM, perform the function call in a sandboxed environment, and run the model again with the results.
Evaluation methods
Evaluation in Braintrust is done through scoring functions (similar to evaluators/scorers in other tools). You can either use scorers from an open-source library called autoevals that the Braintrust team maintains or write your own custom scorers (what most people using Braintrust do). The following evaluation methods are supported:
- LLM-as-a-Judge: LLM-based evaluations that include metrics like humor, factuality, moderation, security, summarization and more.
- Heuristic: Metrics based on hard-coded functions that perform computations to calculate a score, like Levenshtein distance, Jaccard distance and more.
- Human Review Scoring: Integration of human feedback from end-users and experts to evaluate/compare experiments.
- RAG: Evaluations for RAG applications like context precision, context relevancy, answer relevance, etc.
- Statistical: Metrics based on mathematical definitions that can be applied to your data like BLEU, ROUGE and METEOR.
Information on more methods in details is available in the README of the autoevals library.
Process
Similar to LangSmith, you have an SDK here that you can use to run evaluations on your data. This means that your Braintrust code can also run in your custom execution environments like in a pipeline step. You can choose from a list of built-in scorers from the autoevals library or define your own. The following example shows the Eval function from Braintrust being used to perform evaluations on a dataset with an input and an output (reference), using a scorer from the autoevals library and a custom scorer.
from braintrust import Eval
from autoevals import Factuality
def exact_match(input, expected, output):
return 1 if output == expected else 0
Eval(
"Say Hi Bot", # Replace with your project name
data=lambda: [
{
"input": "David",
"expected": "Hi David",
},
], # Replace with your eval dataset
task=lambda input: "Hi " + input, # Replace with your LLM call
scores=[Factuality, exact_match],
)Learn more about writing and running evals in the Braintrust documentation.
Building an automated pipeline
You can use the braintrust and autoevals library with ZenML to build an automated pipeline that you can trigger on schedule or when certain events happen, for example. Check out this section of the blog post to learn how a pipeline and a step with Braintrust might look like.
Pricing
There’s a free plan for everyone and an enterprise plan for companies. They also generously offer all features for free if you sign up with an .edu email or want to use it for an open source project. Learn more here.
Evidently
| Supported Languages | GitHub URL | GitHub stars (as of Nov ‘24) | Project Start Date | License |
|---|---|---|---|---|
| Python | 5.3K | November 2020 | Apache 2.0, Open source (Managed option) |
From the Evidently docs,
Evidently helps evaluate, test, and monitor data and ML-powered systems.
Key features
Evidently is a library that lets you:
- monitor inputs and outputs of your AI applications be it LLM based or traditional tabular/classification-based models.
- generate tests and reports for your data for metrics like data quality, data drift and more.
- instrument your AI applications to collect data and send them to the Evidently platform.
- run evaluation workflows using a code or no-code interface.
Evaluation Methods
Evidently offers the following evaluation methods:
- Traditional ML metrics. If you are using LLMs for classification, information extraction, ranking (as part of RAG), you can also use traditional ML metrics like accuracy, recall, Hit Rate, NDCG.
- Deterministic metrics like:
- Text statistics: how long is the response, how many words are in the output, and more.
- Text patterns: using regular expressions to identify patterns in text, or exact matches.
- LLM as a judge: For checks that require metrics like hallucinations, toxicity and more, Evidently lets you create evaluation prompts to assess your dataset or use built-in templates.
- Metadata Summaries: Your dataset in Evidently can include metadata columns like user upvotes and downvotes. You can then run summary metrics like
ColumnSummaryMetricto see a distribution of your metadata (upvotes vs downvotes, for example). - ML-based metrics. Evidently also allows running evaluations using built-in ML models (like sentiment evaluation) or models from HuggingFace.
- Using an embedding model: You can evaluate semantic similarity in two bodies of texts using an embeddings model.
Process
You have an open-source evidently library that allows you to run evals through code, allowing you the flexibility to choose your execution environment going forward.
When using the open-source library, the process for experimentation could look something like this:
- You prepare an evaluation dataset to test your LLM against.
- You run this data inputs against your LLM or your product API.
- Then, pass the resulting dataset to Evidently for LLM evaluation.
Evidently decouples the LLM API call from the evaluation call unlike other tools. The reasoning behind this is that in most production use cases, it is easier to test your API separately (you may have different deployment scenarios).
There are some metrics that are available out-of-the-box for every evaluation method, and you can also define your own custom metrics. The example below shows you how to use two built-in prompt templates for an LLM-as-a-judge evaluation. It is recommended to pass the OpenAI API key as an environment variable before you run this code.
from evidently.report import Report
from evidently.metric_preset import TextEvals
from evidently.descriptors import *
report = Report(metrics=[
TextEvals(column_name="response", descriptors=[
DeclineLLMEval(),
PIILLMEval(include_reasoning=True),
])
])
report.run(reference_data= None,
current_data= assistant_logs[:10],
column_mapping=column_mapping)
reportThe descriptors used are the DeclineLLMEval which checks if the response contains a denial, and the PIILLMEval which checks if the response contains personally identifiable information.
Learn more about running evaluations using Evidently in this guide.
Building an automated pipeline
You can use the evidently library with ZenML to build an automated pipeline that you can trigger on schedule or when certain events happen, for example. Check out this section of the blog post to learn how a pipeline and an Evidently step might look like. ZenML also integrates with Evidently to offer easy data validation for your pipelines. Check out this blog post on how ZenML and Evidently work great together.
Pricing
Evidently is open-source and you can use make use of the library in your apps as you wish. There also exists a managed platform that is free to begin with and has offers for different organization sizes. Check out the Pricing page for more information.
Cloud Provider Solutions

AWS (Sagemaker)
| Supported Languages | GitHub URL | GitHub stars (as of Nov ‘24) | Project Start Date | License |
|---|---|---|---|---|
| JS, Python, Java, Ruby, Go | Not open source. Python SDK: | 2.1K (Python SDK) | November 2017 | Proprietary (Pay-as-you-go) |
Key features
AWS offers Sagemaker as a one stop shop for everything MLOps and now (LLMOps). Sagemaker comes with a bunch of features:
- Model Building & Training: Built-in and custom algorithms, scalable training, hyperparameter tuning, AutoML, distributed training, debugging tools.
- Model Deployment & Inference: Managed endpoints, serverless inference, model monitoring, A/B testing, multi-model endpoints, real-time and batch inference.
- Data Management: Data labeling, feature store, data wrangling.
- Management & Collaboration: Centralized console, IAM integration, version control, experiment tracking, team collaboration.
- Integration & Support: AWS service integration, notebook instances, pre-built containers, open-source framework support.
- Evaluation: Detect bias and explain predictions for models
Evaluation Methods
Sagemaker uses the fmeval library (short for Foundation Model Evaluation Library) that it builds and maintains as a basis for evaluations that you run on your data. It is open-source and comes built-in with a range of algorithms for metrics like toxicity, accuracy, factual knowledge, summarization and more.
Through fmevals , Sagemaker offers the following evaluation methods:
- Statistical: metrics like ROUGE can be calculated for your LLM outputs in cases like text summarization. Read more about this on the Sagemaker docs.
- LLM based metrics like Factuality (based on some ground truth) and Toxicity.
- Semantic Robustness which evaluates how your model outputs change as the result of small perturbations like extra whitespaces, random upper cases, etc.
Process
You can run all of the different evaluation methods in Amazon Sagemaker either directly in the Sagemaker Studio by creating evaluation jobs or use the fmeval library to run your own automatic evaluations. Let’s talk about the fmevals library case as it offers more customizations and is flexible in terms of how you use it and where you run it.
The main steps that you need to use fmeval are:
- Create a
ModelRunnerwhich can perform invocation on your LLM.fmevalprovides built-in support for Amazon SageMaker Endpoints and JumpStart LLMs. You can also extend theModelRunnerinterface for any LLMs hosted anywhere. - Use any of the supported eval_algorithms.
The example below shows you how to define your data and run an evaluation algorithm on it.
# 1. Create a DataConfig
config = DataConfig(
dataset_name="custom_dataset",
dataset_uri="./custom_dataset.jsonl",
dataset_mime_type="application/jsonlines",
model_input_location="question",
target_output_location="answer",
)
# 2. Use an eval algorithm
from fmeval.eval_algorithms.toxicity import Toxicity, ToxicityConfig
eval_algo = Toxicity(ToxicityConfig())
# 3. Run your evaluation
eval_output = eval_algo.evaluate(model=model_runner, dataset_config=config)Building an automated pipeline
You have two options when it comes to running evaluations in an automated pipeline setup:
- Create an automatic model evaluation job in the Sagemaker Studio: this can be done in a no-code fashion by selecting the model in test, the dataset, the evaluators and their config all from the Studio and triggering a job. You can then reuse the job to run more evaluations.
- Create your own pipelines (using Sagemaker Pipelines or other tools like ZenML) and add the
fmevalevaluation logic as a step in this pipeline.
Below is an example of how an evaluation step can look like inside a Sagemaker pipeline, taken from AWS’ blog post on operationalizing LLM evaluations at scale, and annotated with my comments.
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
# S3 code to download your dataset
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
# Creating a DataConfig like the one we created before
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
# Defining an evaluation config based on the YAML config file passed to the pipeline
evaluation_config = model_config["evaluation_config"]
# Defining your input and inference parameters
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
# Defining a ModelRunner that the evaluations will be run against
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
# Running all algorithms passed as config to the pipeline
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
# getting the eval algorithm class from the config name
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
# running the evaluation using the fmeval library
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
# writing results back to S3
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultAs you can see, it’s a fairly complex process that involves:
- calls to your artifact storage option (S3 in this case) to download data and upload your evaluation results.
- writing logic that parses your configs and translates them to objects in code.
- a lot of configurations for the model you want to test.
Some of this can be made easier by using a ZenML pipeline. Look at this section of the post where I show how this step would look like with ZenML. Alternatively, also check out how other tools are used with ZenML, and maybe you can find an easier approach to take.
Pricing
The fmeval library is open-source and free to use. However, you might use it with the Sagemaker platform and that comes with a cost. Running pipelines on Sagemaker costs you money based on the instance type you use. Check out this page to learn more about the available options and their pricing.
In addition to it, if you also use JumpStart and inference endpoints from Sagemaker, those come with their own costs. Check out the AWS SageMaker pricing page for more details.
Google Cloud Platform (Vertex AI)
| Supported Languages | GitHub URL | GitHub stars (as of Nov ‘24) | Project Start Date | License |
|---|---|---|---|---|
| Python, Node, Java, Go | Not open source. Python SDK: | 636 (Python SDK) | May 2021 | Proprietary (Pay-as-you-go) |
GCP offers Vertex AI, a fully managed solution for all your MLOps and LLMOps needs. Everything from model training, evaluation, and deployment can be done through this single service. Vertex AI also has a GenAI evaluation service that provides you with metrics, and tools to run evaluations on your model outputs.
Key features
The Gen AI evaluation service can help you with the following tasks:
- Model Selection: The service simplifies choosing the best pre-trained model for your needs, comparing performance across benchmarks and your own data.
- Parameter Optimization: Easily adjust model parameters (e.g., temperature) to fine-tune output quality and style.
- Prompt Engineering Assistance: Get guidance on crafting effective prompts and templates to achieve desired model behavior.
- Safe & Effective Fine-tuning: Improve model performance for your specific use case while mitigating bias and unwanted outputs.
- RAG Architecture Optimization: Select the most efficient Retrieval Augmented Generation (RAG) architecture for your application.
- Continuous Model Improvement: The service facilitates migrating to newer, superior models as they become available, ensuring optimal performance.
Evaluation Methods
You have access to the following classses of evaluation methods:
- Autoraters: they use LLMs as a judge. Here, an LLM is specifically tailored to perform the tasks of evaluation and doesn’t need ground truth. The judgments that the autoraters provide also come with explanations and a confidence score.
- Computation: These methods use mathematical formulas to compute results based on common computation metrics (see the next section). There are also metric bundles available out-of-the-box for ease of use.
- Human: Vertex AI makes it easy for humans to review outputs and submit feedback.
Process
With the Vertex AI SDK, you can define:
- criteria: which are single or multiple dimensions to run evaluations upon, for example, correctness, relevance and more.
- metrics: these are scores that measure the LLM outputs against your criteria.
In many tools so far, you’ve seen these two concepts merged into the idea of evaluators or scorers, sometimes using a separate config class to define the metric values to use. Google makes this separation explicit.
Metrics
When it comes to metrics, the Gen AI Evaluation Service provides two major types:
- Model-based metrics: Use a proprietary Google model as a judge. You can measure model-based metrics pairwise or pointwise:
- Pointwise metrics: Let the judge model assess the candidate model's output based on the evaluation criteria.
- Pairwise metrics: Let the judge model compare the responses of two models and pick the better one. This is often used when comparing a candidate model with the baseline model.
- Computation-based metrics: These metrics are computed using mathematical formulas to compare the model's output against a ground truth or reference. Commonly used computation-based metrics include ROUGE and BLEU.
Running an evaluation
To run an evaluation, you can use the EvalTask object from the Vertex AI SDK to first define your dataset and the metrics you want to use and then run evaluation on it using the .evaluate() function.
The following example shows you how to run an evaluation using built-in prompt templates and also custom metrics built using these built-in templates.
# 1. Use the pre-defined model-based metrics directly
# Fluency is a criteria available for this metric
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[MetricPromptTemplateExamples.Pointwise.FLUENCY],
)
eval_result = eval_task.evaluate(
model=MODEL,
)
# 2. Define a custom pointwise metric with two custom criteria
custom_text_quality = PointwiseMetric(
metric="custom_text_quality",
metric_prompt_template=PointwiseMetricPromptTemplate(
criteria={
"fluency": "Sentences flow smoothly and are easy to read, avoiding awkward phrasing or run-on sentences. Ideas and sentences connect logically, using transitions effectively where needed.",
"entertaining": "Short, amusing text that incorporates emojis, exclamations and questions to convey quick and spontaneous communication and diversion.",
},
rating_rubric={
"1": "The response performs well on both criteria.",
"0": "The response is somewhat aligned with both criteria",
"-1": "The response falls short on both criteria",
},
input_variables=["prompt"],
),
)
# Run evaluation using the custom_text_quality metric
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[custom_text_quality],
)
eval_result = eval_task.evaluate(
model=MODEL,
)There are other ways to define and run evaluations too. Learn more about them in the Vertex AI GenAI evaluation service docs.
Building an automated pipeline
Like in AWS, it is important to learn how to build an automated evaluation pipeline for production use-cases. The Gen AI Evaluation Service provides pre-built pipeline components for running evaluation and monitoring in production using Vertex AI Pipelines.
The AutoSxS (Automatic side-by-side) is a pairwise model-based evaluation tool that runs through the evaluation pipeline service. It comes with an autorater and can evaluate performances of models in the Vertex Model Registry in a pairwise fashion. This is a pre-built pipeline and you can configure your datasets, the tasks and criteria for you evaluation and other configuration.
You can also define your own pipelines in Vertex AI that use the EvalTask class to run model-based or computation-based evaluations, offering greater flexbility over the AutoSxS pipeline.
Pricing
The pricing for the Gen AI Evaluation Service is here. It charges differently for pairwise and pointwise metrics and also for model-based and computation-based metrics, as expected.
That aside, if you run your evaluations in Vertex AI pipelines (either your own or the AutoSxS pipelines), you have to pay for it too.
In order to use the EvalTask object you need to host your models on the Vertex AI Model Registry which comes at a price too. Check out the Vertex AI Model Registry pricing page for more details.
Azure (Azure AI Studio)
| Supported Languages | GitHub URL | GitHub stars (as of Nov ‘24) | Project Start Date | License |
|---|---|---|---|---|
| C#, C++, Go, Java, JavaScript, Objective-C, Python, Ruby, Swift | Not open source. Python SDK: | 4.6K (Python SDK) | November 2023 | Proprietary (Pay-as-you-go) |
Azure offers the Azure AI Studio as a managed service that lets you train, monitor, evaluate and deploy models.
Key features
Azure AI Studio offers a host of features:
- Model catalog: A library of pre-trained AI models for different functionalities, including computer vision, natural language processing, speech services, and generative AI
- Prompt flow: A visual graph for orchestrating prompts, with integrations for open-source frameworks
- Azure AI Content Safety: A tool to detect offensive or inappropriate content in text and images
- Enterprise-grade production: The ability to deploy AI innovations to Azure's managed infrastructure with continuous monitoring and governance
- Serverless API deployments: Some models can be deployed as a serverless API with pay-as-you-go billing
- Model comparison: The ability to compare models by task using open-source datasets
- Model evaluation: The ability to evaluate models with your own test data
- Prompt templates: Templates to avoid prompt injection attacks
Evaluation Methods
Azure supports two main methods for automated evaluations of generative AI applications:
- Traditional machine learning measurements: used to quantify the accuracy of generated outputs compared to expected answers.
- AI-assisted evaluations: in this method, we use LLMs to judge the outputs based on metrics like quality of answers, safety, and more.
Process
For evaluation, Azure offers three paths:
- Playground: In this path, you can manually evaluate your application by configuring your dataset, choosing the model and the metrics in the Playground itself.
- Evaluating “Flows”: Flows allow you to link together LLMs, prompts and other python tools. You can do this in the Studio or through the SDK/CLI. Evaluation of flows can also be triggered by either of those two ways and this helps you evaluate across a great number of metrics and data in an automated way.
- Direct dataset evaluation: In this path, you submit a dataset that you have collected (say from the logs of your application) to the evaluation wizard, and run evaluations on it using the SDK/CLI or the Studio.
You can use built-in evaluators or create your own custom evaluators. You can find a list of all built-in evaluators on the docs page here.
To run evaluations, you have two options:
- run evaluators on a single row of data: this can be used to test your metrics and polish your evaluator config.
import os
# Initialize Azure OpenAI Connection with your environment variables
model_config = {
"azure_endpoint": os.environ.get("AZURE_OPENAI_ENDPOINT"),
"api_key": os.environ.get("AZURE_OPENAI_API_KEY"),
"azure_deployment": os.environ.get("AZURE_OPENAI_DEPLOYMENT"),
"api_version": os.environ.get("AZURE_OPENAI_API_VERSION"),
}
from azure.ai.evaluation import RelevanceEvaluator
# Initialzing Relevance Evaluator
relevance_eval = RelevanceEvaluator(model_config)
# Running Relevance Evaluator on single input row
relevance_score = relevance_eval(
response="The Alpine Explorer Tent is the most waterproof.",
context="From the our product list,"
" the alpine explorer tent is the most waterproof."
" The Adventure Dining Table has higher weight.",
query="Which tent is the most waterproof?",
)
print(relevance_score)run evaluations on a dataset using evaluate()
from azure.ai.evaluation import evaluate
result = evaluate(
data="data.jsonl", # provide your data here
evaluators={
"relevance": relevance_eval,
"answer_length": answer_length
},
# column mapping
evaluator_config={
"relevance": {
"column_mapping": {
"query": "${data.queries}"
"ground_truth": "${data.ground_truth}"
"response": "${outputs.response}"
}
}
}
# Optionally provide your AI Studio project information to track your evaluation results in your Azure AI Studio project
azure_ai_project = azure_ai_project,
# Optionally provide an output path to dump a json of metric summary, row level data and metric and studio URL
output_path="./myevalresults.json"
)Learn more about how to set this up, what the requirements for your dataset are, and what configurations are available for the evaluators in this guide on Microsoft Learn.
Building an automated pipeline
You can define “flows” using Prompt Flow in Azure AI Studio that represent a pipeline comprising your LLMs, prompts and other Python tools in a graph view. You can run flows from the Azure AI Studio or through the SDK/CLI and this acts like a way to automate some processes around your LLM development workflow.
To run automated evaluations, you can create evaluation flows in Prompt Flow that can be used to evaluate other flows. You can choose from a range of built-in evaluation flows and can customize them to suit your needs. Evaluation flows run after the flow they are evaluating and take their outputs as inputs. They can also take in other datasets like a ground truth dataset.
Learn more about how you can define these flows and run them in the evaluation flow guide.
Comparison Matrix

Building an automated evaluation pipeline with ZenML
ZenML allows you to build pipelines that are composable and can help you experiment with multiple tools very easily. It also abstracts away responsibilities like managing your data artifacts, making them available across steps so you don’t have to write custom S3 code, for example, in your step code.

To get a taste of how ZenML would let you try out all the tools above, I have sample step code for some of them below. The idea is that you can build a pipeline, say a finetuning pipeline that loads your data, finetunes a model, and then evaluates it with the tool of your choice. This means that evaluation is just a step in this pipeline and the implementation of it can be switched based on the tool you use.
Or you can also run evaluations across all tools in the same pipeline to see how they fare against each other.
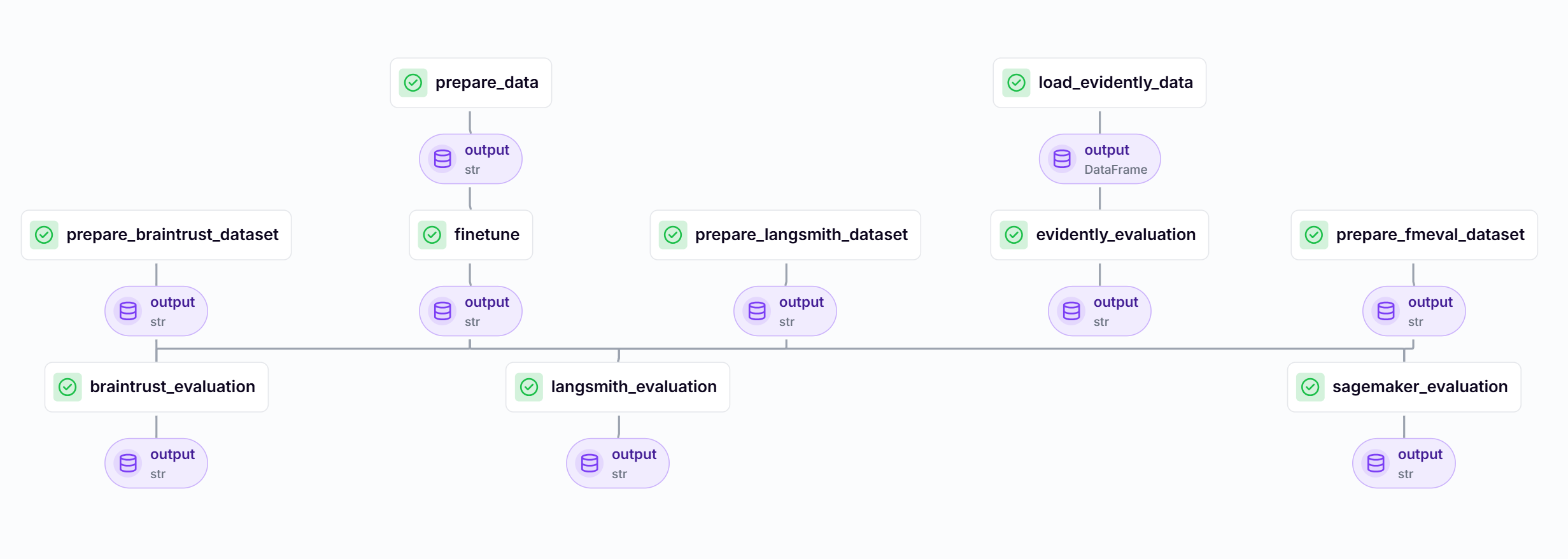
Sample Pipeline
from zenml import pipeline
from steps.prepare_data import prepare_data
from steps.finetune import finetune
from steps.load_evaluation_dataset import load_evaluation_dataset
from steps.braintrust_evaluation import braintrust_evaluation
@pipeline
def finetuning_pipeline(base_model_id:str):
tokenized_dataset = prepare_data(base_model_id)
model_id = finetune(base_model_id, tokenized_dataset)
evaluation_dataset = load_evaluation_dataset()
braintrust_evaluation(model_id, evaluation_dataset)As you can see, defining pipelines in ZenML is as easy as adding a pipeline decorator to your Python function that links step functions together. In this pipeline, we first prepare our dataset to use for finetuning a model, then we run the finetuning and finally we prepare the evaluation dataset and run the evaluation based on a tool implementation. Here, we are importing the evaluation step we wrote using Braintrust.
Evaluation Steps
Let’s now see how the evaluations would look like in a ZenML step. You will notice a common theme across these functions:
- The inputs to the functions are usually models you want to run evaluations for. These models are produced by the finetuning step and are made available to your evaluation step code by ZenML automatically. No more writing manual data operations code.
- To track an artifact with ZenML, all you have to do is return that object in the step function. ZenML would then automatically track and version this artifact(s) in your artifact store.
- You can also use the Artifact Store API to perform backend-agnostic operations on your artifact store. For example, to write a file to your store, you can just ZenML’s
fileio.open()function which works across all storage backends like S3, GCS, Azure, and more!
Braintrust
from zenml import step
@step
def braintrust_evaluation(model_id:str, dataset: Dataset):
from braintrust import Eval
from autoevals import Factuality
def exact_match(input, expected, output):
return 1 if output == expected else 0
def generate_prediction(input: str):
model = load_model(model_id)
...
Eval(
"ZenML Braintrust",
data=dataset,
task=generate_prediction,
scores=[Factuality, exact_match],
)In this code, we
- use the
datasetand themodel_idfrom previous steps - have a helper function to load and generate predictions from our finetuned model which takes one input parameter, as the
Evalfunction expects. - perform evaluations on our model using the
Evalfunction from Braintrust - define a custom metric and use one built-in metric from the
autoevalslibrary.
LangSmith
from typing import Dict
from langchain_openai import ChatOpenAI
from langsmith.evaluation import LangChainStringEvaluator
from zenml import step
@step
def langsmith_evaluate(dataset_name: str, model_id: str):
eval_llm = ChatOpenAI(temperature=0.0, model="gpt-3.5-turbo")
cot_qa_evaluator = LangChainStringEvaluator("cot_qa", config={"llm": eval_llm})
def generate_prediction(inputs: Dict[str, str]):
model = load_model(model_id)
...
evaluate(
generate_prediction,
data=dataset_name,
evaluators=[cot_qa_evaluator],
)In this code, we:
- get the
dataset_nameand themodel_idfrom previous steps (prepare evaluation dataset and finetune model). - have a helper function that takes in a dictionary of inputs (as required by the
evaluatefunction), loads the model and generate predictions. - use the
evaluatefunction to run evaluations on our data and model with a set of evaluators. - define a chain of thought QA evaluator that uses an LLM as a judge.
AWS’ FMEval
from zenml import step, load_artifact
from zenml.io import fileio
from zenml.types import HTMLString
@step
def sagemaker_evaluation(dataset_path: str, endpoint_name, data_config, model_config, algorithm_config):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
# copy the dataset from the artifact store to the local file system
fileio.copy(dataset_path, "dataset.jsonl")
# Creating a DataConfig
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
# Defining an evaluation config based on the YAML config file passed to the pipeline
evaluation_config = model_config["evaluation_config"]
# Defining your input and inference parameters
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
# Defining a ModelRunner that the evaluations will be run against
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
eval_output_all_html = []
# Running all algorithms passed as config to the pipeline
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
# getting the eval algorithm class from the config name
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
# running the evaluation using the fmeval library
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
html_zenml = HTMLString(html)
eval_output_all_html.append(html_zenml)
eval_result = {"model_config": model_config, "eval_output": eval_output_all, "eval_output_html": eval_output_all_html}
print(f"eval_result: {eval_result}")
# ZenML will autosave the eval_result to your artifact store
return eval_resultIn this code, we:
- copy the JSONL file containing our evaluation dataset into the current filesystem, from our artifact store.
- create a
DataConfig, an evaluation config, input parameters and choose our model through theJumpStart. - loop over all algorithms that we want to evaluate against and run them.
- create
HTMLStringobjects from the HTML string in the evaluation results. This enables ZenML to show you evaluations on the ZenML Dashboard. - return the results for them to be tracked and versioned automatically by ZenML.
Evidently
import pandas as pd
from typing import Tuple
from zenml import step
from zenml.types import HTMLString
from evidently import ColumnMapping
from evidently.report import Report
from evidently.metric_preset import TextEvals
from evidently.metrics import ColumnSummaryMetric
from evidently.descriptors import TextLength, Sentiment, IncludesWords
@step
def create_evidently_report(
data: pd.DataFrame,
) -> Tuple[HTMLString, HTMLString]:
"""Create Evidently Report and TestSuite for LLM evaluation.
Returns:
Tuple containing HTML reports for both the metrics report and test suite
"""
# Define column mapping
column_mapping = ColumnMapping(
datetime=Config.DATETIME_COLUMN,
text_features=[Config.TEXT_COLUMN, Config.REFERENCE_COLUMN],
categorical_features=Config.METADATA_COLUMNS,
)
# Create Report
metrics_report = Report(
metrics=[
TextEvals(
column_name=Config.TEXT_COLUMN,
descriptors=[
Sentiment(),
TextLength(),
IncludesWords(
words_list=Config.COMPENSATION_KEYWORDS,
display_name="Mention Compensation",
),
],
),
*[
ColumnSummaryMetric(column_name=col)
for col in Config.METADATA_COLUMNS
],
]
)
# Run evaluations
metrics_report.run(
reference_data=None, current_data=data, column_mapping=column_mapping
)
# Convert reports to HTML strings for visualization
metrics_html = HTMLString(metrics_report.show(mode="inline").data)
return metrics_htmlIn this code, we:
- get data from previous steps
- define a
Reportobject in Evidently where we specify what column we want to choose and the set of pre-built or custom descriptors (scorers) we want to run against. - generate evaluation results and create an
HTMLStringobject that lets ZenML visualize these results in the Dashboard.
Conclusion
LLM evaluation is not just a nice-to-have – it’s an essential practice given the inherent unreliability of language models. A robust evaluation framework gives you the confidence to experiment with different models and architectures, knowing that if they pass your custom evaluations, you’re likely on solid ground.
The evaluation landscape consists of three main categories: custom evaluations (the most crucial but requiring significant effort), specialized platforms (like Langfuse), and cloud provider solutions (such as Amazon SageMaker FMEval). These tools differ primarily in their ease of use, cost structure, scalability, and most importantly, the actual value they bring to your evaluation process.When choosing your evaluation toolkit, the decision often comes down to your existing infrastructure and specific needs. If you’re already invested in a cloud platform, their native solutions might be the most pragmatic choice. For more specialized requirements, platforms like Langsmith, Braintrust and more could be worth exploring.

I recommend taking a phased approach to LLM evaluation. Start with manual checks to establish baseline performance, then gradually transition to automated pipelines. This automation is inevitable and valuable – it enables evaluation against larger datasets and allows for scheduled testing of your production applications. Tools with well-designed libraries and SDKs are particularly valuable here, as they enable independent evaluation runs that can be seamlessly integrated into your pipelines.We saw this in practice with the SageMaker example, where adding an evaluation step using the fmeval library enhanced the pipeline. This pattern can be replicated with other libraries that match your requirements. The key is ensuring your chosen solution is fast, easy to debug, and reliable. When selecting pipeline tools, prioritize those that offer flexibility in tool integration and enable rapid pipeline development without unnecessary complexity.
The big picture is clear: start small with custom evaluations, automate them as part of your pipeline, and then consider incorporating additional frameworks as needed. While this might seem like a significant investment, you won’t regret building solid evaluation practices into your LLM workflows. It’s an investment that pays dividends in reliability, confidence, and the ability to evolve your LLM applications with assurance.


