



In the fast-paced world of AI, the ability to efficiently fine-tune Large Language Models (LLMs) for specific tasks is becoming a critical competitive advantage. This post dives into how combining Lightning AI Studios with ZenML can streamline and automate your LLM fine-tuning process, enabling rapid iteration and deployment of task-specific models.
The LLM Fine Tuning Challenge
As LLMs like GPT-4o, Llama 3.1, Mistral, etc. become more accessible, companies are increasingly looking to adapt these models for specialized tasks. This could range from customer service chatbots and content generation to specialized data analysis and decision support systems.
One of the most exciting developments in LLM fine-tuning is the ability to create and serve multiple fine-tuned variants of a model efficiently. With LoRA (Low-Rank Adaptation) and its many variants [1][2], you can generate small adapter weights that modify the behavior of the base model without changing its core parameters. This allows you to service each use case with its own fine-tuned model variant.
This approach has tremendous benefits:
- Fine-tune models with minimal computational resources
- Store and distribute only the adapter weights (typically a few MB) instead of entire models
- Serve thousands of fine-tuned variants from a single base model (see LoRAX)
Generating A Fine Tuning LLM Flywheel
However, as organizations seek to leverage these models for specific use cases, a new challenge has emerged: the need to efficiently fine-tune and manage numerous LLM variants. The challenge lies in scaling this process. Fine-tuning a single LLM is manageable (in fact it’s easier than ever with tools like axolotl), but what happens when you need to maintain and update dozens or even hundreds of fine-tuned models? Some key issues include:
- Resource Management: LLM fine-tuning is computationally intensive, often requiring specialized hardware like GPUs or TPUs.
- Data Preparation: Each fine-tuning task may require its own dataset, which needs to be collected, cleaned, and formatted appropriately.
- Hyperparameter Optimization: Finding the right hyperparameters for each fine-tuning task can be a time-consuming process.
- Version Control: Keeping track of different model versions, their training data, and performance metrics becomes increasingly complex.
- Deployment and Serving: Getting fine-tuned models into production efficiently and managing their lifecycle presents another set of challenges.
- Cost Management: With the computational resources required, costs can quickly spiral if not managed carefully.
Setting up infrastructure is hard
As organizations scale up their LLM usage, these challenges compound. What's needed is not just a way to fine-tune models, but a comprehensive, automated pipeline for managing the entire process. These projects also face challenges in setting up and managing infrastructure. This process can be time-consuming and complex, especially when dealing with distributed training or scaling workloads. Data scientists working on the models shouldn’t have to worry about spinning up and maintaining compute instances or managing credentials for them. This is where ZenML and Lightning AI can help you! This blog post explores the growing complexity of LLM fine-tuning at scale and introduces a solution that combines the flexibility of Lightning Studios with the automation capabilities of ZenML.
Lightning Studios: Your New ML Playground
.png)
Lightning AI, the brainchild of the PyTorch Lightning crew, has dropped a bomb on the ML world with their Studios concept. Think of it as your personal, scalable ML lab in the cloud. Need to switch from CPU to multi-GPU setups on the fly? Lightning's got you covered.
Studios provide modular, cloud-based environments pre-configured with essential ML libraries. The key advantage is flexibility - you can easily scale from CPU-only setups to multi-GPU, multi-node configurations as your needs evolve. For LLM fine-tuning, this means you can:
- Prototype and debug your data preperation scripts on CPU instances
- Seamlessly switch to GPU instances for the actual training
- Scale up to multi-GPU setups for larger models or datasets
ZenML: Structuring and Automating ML Workflows
While Lightning Studios provide the environment, ZenML brings structure and automation to your ML pipelines. As an open-source MLOps framework, ZenML integrates seamlessly with Lightning AI, allowing you to define reproducible, scalable workflows for your fine-tuning tasks.
ZenML offers several key benefits when combined with Lightning AI:
- Faster Execution: Automatic packaging and upload of code to Lightning AI Studio.
- Reproducible Training: Consistent results by encapsulating Lightning AI configurations within ZenML pipelines.
- Quick Experimentation: Run experiments with different parameters and on different machines quickly using ZenML's configurable pipelines.
- Seamless Tracking: Track and compare model metrics, hyperparameters, and artifacts using ZenML's experiment tracking features.
- Managed Infrastructure: Access to Lightning AI's infrastructure, including GPUs, for running your pipelines.
- Built-in Distributed Training: Leverage Lightning AI's support for distributed training out of the box.
To prepare your environment for LLM fine-tuning with ZenML and Lightning Studios:
- Install ZenML and the Lightning integration:
- Clone the sample project:
- Initialize and connect to a deployed ZenML server:
These steps install necessary tools, set up your project, and prepare ZenML for use with Lightning Studios. This foundation enables you to create reproducible ML pipelines, easily switch between local and cloud environments, and effectively track your experiments.
With this setup, you're ready to define your LLM fine-tuning pipeline and leverage the scalability of Lightning Studios for your training tasks.
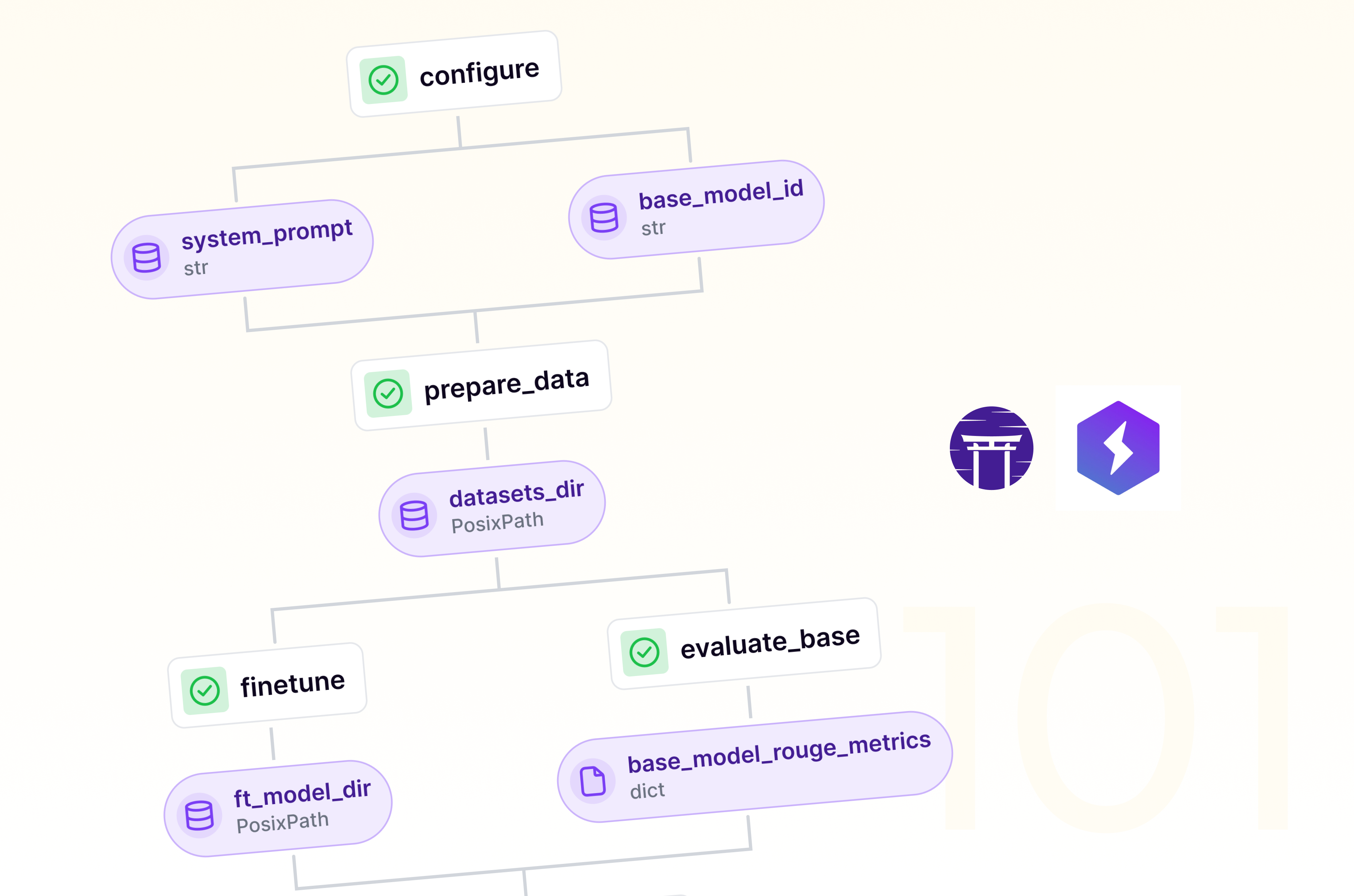
Fine-tuning LLMs in 60 lines of code
While LLM fine-tuning can seem daunting, we can distill the core process into a concise, yet powerful script. Here's a condensed ZenML pipeline that captures the essence of LLM fine-tuning in just about 60 lines of code:
<aside>You can see all the code from this blog in this GitHub repository.</aside>
This script encapsulates the core components of LLM fine-tuning:
- Data Preparation: The
prepare_datastep loads and tokenizes the dataset, preparing it for training. - Fine-tuning: The
finetunestep sets up the model, training arguments, and executes the fine-tuning process. - Pipeline Definition: The
llm_finetune_pipelineties these steps together into a cohesive workflow.
While this script provides a solid foundation, in practice, you'll likely want to add more sophisticated error handling, logging, and potentially additional steps for evaluation and model deployment.
Leveraging PyTorch Lightning Checkpoints
ZenML's flexibility extends to integrating with popular deep learning frameworks like PyTorch Lightning. One powerful feature is the ability to link externally produced data as ZenML artifacts. This is particularly useful for managing model checkpoints produced during training.
Here's how we can modify our existing fine-tuning step to incorporate this feature:
This approach allows you to leverage the Hugging Face Trainer's checkpoint saving capabilities while seamlessly integrating with ZenML's artifact management system. By using link_folder_as_artifact, you can treat the saved model and checkpoints as ZenML artifacts, making them easily accessible for future use, versioning, and tracking.
Streamlining Parameter Management with YAML
Rather than cluttering our command line with numerous parameters, we can leverage a YAML configuration file to manage our fine-tuning settings. Here's an example small_model.yaml:
This YAML file allows us to easily adjust parameters like the base model, dataset size, and training epochs without modifying our core script. To run the fine-tuning process with these parameters, we simply execute:
Visualizing Results with ZenML
One of the key advantages of using ZenML is the ability to track and visualize your experiments. After running your fine-tuning pipeline, you can view the results in the ZenML dashboard:
.png)
This dashboard provides an overview of your pipeline runs, allowing you to compare different experiments and track your progress over time.
For ZenML Pro users, the Model section offers even more detailed metrics:
.png)
These visualizations can be invaluable for understanding the performance of your fine-tuned models and making data-driven decisions about further improvements.
Leveraging Lightning AI Studios + ZenML
To take full advantage of Lightning AI Studios' scalable compute resources, we can configure our ZenML stack to use Lightning as our orchestrator. Here's how to set it up:
- First, register a Lightning orchestrator:
- Next, set up a remote artifact store (in this case, using AWS S3).
- Finally, create and set your ZenML stack:
With this configuration, you can now leverage Lightning AI Studios' resources for your fine-tuning tasks. To make the most of this setup, you can create a more detailed YAML configuration file that specifies different compute resources for different steps of your pipeline:
This configuration allows you to use CPU instances for data preparation and potentially evaluation steps, while leveraging powerful GPU instances (in this case, an A10G) for the compute-intensive fine-tuning step.
We can run it with:
This will set off a run in the ZenML Dashboard using Lightning AI Studio as the orchestrator.
.png)
You will now see a new studio spin up on your lightning studio account, which will execute the pipeline and then exit when the task finishes.
Why This Matters: The Future of AI is Task-Specific
While general-purpose models like GPT-4 and Claude Opus are undoubtedly impressive, they often represent overkill for many specific tasks. These models come with significant computational and financial costs, making them impractical for many organizations to deploy at scale.
The future of AI lies not just in these massive, general-purpose models, but in the ability to rapidly create and deploy task-specific models that are more efficient and cost-effective. As highlighted in a recent TechCrunch article, ZenML is betting on a future where companies build their own AI stacks using smaller, more efficient models tailored to their specific needs.
This approach offers several key advantages:
- Cost-Effectiveness: Smaller, task-specific models require less computational resources to run, reducing operational costs.
- Improved Performance: Models fine-tuned on domain-specific data often outperform general-purpose models on specialized tasks.
- Faster Iteration: Smaller models allow for quicker experimentation and iteration cycles, speeding up development.
- Data Privacy: By fine-tuning your own models, you maintain control over your training data, which is crucial for many industries with strict privacy requirements.
The combination of Lightning Studios and ZenML provides a powerful toolkit for automating LLM fine-tuning pipelines, positioning you to ride this wave of task-specific AI. This approach enables teams to:
- Rapidly prototype and experiment with different fine-tuning strategies
- Efficiently allocate computational resources across the pipeline
- Maintain reproducibility and scalability in ML workflows
- Easily manage and deploy multiple fine-tuned model variants
As we move towards more specialized AI applications, the ability to quickly fine-tune and deploy task-specific models becomes increasingly valuable. Whether you're building a specialized chatbot, a domain-specific text analyzer, or exploring novel AI applications, this automated pipeline approach provides the flexibility and efficiency needed to stay competitive in the rapidly evolving world of AI.
The future of AI isn't just about having the biggest model - it's about having the right model for the job. With Lightning AI Studios and ZenML, you can build and deploy those models faster and more efficiently than ever.