On this page
In the rapidly evolving world of MLOps and LLMOps, most discussions focus on model performance, pipeline efficiency, or deployment strategies. Yet beneath these flashier concerns lies a fundamental challenge that quietly consumes engineer time and introduces security risks: credential management.
The Credential Management Quagmire in MLOps
Machine learning pipelines rarely exist in isolation. They interact with a diverse ecosystem of services - from cloud storage buckets and container registries to compute clusters and databases. Each of these touchpoints requires authentication, and the complexity compounds quickly:
- Your training pipeline needs to pull data from an S3 bucket
- Your model artifacts get pushed to a GCP Storage bucket
- Your deployment pipeline publishes containers to AWS ECR
- Your inference service runs on an Azure Kubernetes cluster
- Your monitoring dashboard queries data from Snowflake
For each of these interactions, engineering teams face the same question: “How do we securely provide the right credentials to the right components of our ML system?”

The Hidden Complexity of ML Authentication
The challenge is particularly acute in ML workflows because they span so many specialized services. A single end-to-end pipeline might interact with 5-10 different external systems, each with its own authentication mechanism. This creates a matrix of complexity that traditional software applications rarely encounter.
And there’s a fundamental tension at work: security requirements often directly conflict with developer velocity. The most secure approach (tightly scoped, short-lived credentials, rotated frequently) creates the most friction for data scientists and ML engineers who just want their pipelines to work reliably.
The Real-World Cost of Poor Credential Management
The costs of inadequate credential solutions manifest in multiple ways:
- Security vulnerabilities: Hardcoded API keys, overly permissive IAM roles, and leaked secrets create attack vectors that can compromise data or infrastructure
- Engineer time drain: Data scientists and ML engineers waste countless hours troubleshooting authentication issues instead of improving models
- Operational inconsistency: The gap between development, testing, and production environments widens when credential management is handled differently across environments
This problem is so pervasive that a 2023 survey by Run:ai found infrastructure-related challenges (54%) and compute-related challenges (43%) were the top concerns for companies in AI development, with 89% of respondents reporting they face compute resource allocation issues on a regular basis (weekly, daily, or bi-weekly). Additionally, a 2022 report by the Identity Defined Security Alliance revealed that 84% of identity and security professionals experienced an identity-related breach in the previous year, highlighting the significance of authentication and permission management in technical environments.
Common Approaches and Their Limitations
Most teams default to one of several imperfect approaches:
Environment variables or config files: Simple but insecure, these approaches often lead to credentials being committed to source control or exposed in logs. They also create configuration drift between environments and become unwieldy at scale.
Cloud-native IAM solutions: While powerful, these are cloud-specific, require deep expertise, and don’t address the multi-cloud reality many organizations face. Setting up cross-account IAM roles with the principle of least privilege is time-consuming and error-prone.
External secret managers: Tools like HashiCorp Vault or cloud provider secret managers improve security, but add operational complexity. They require additional infrastructure to manage and often create a new integration challenge for ML systems.
None of these approaches fully addresses the unique demands of modern ML workflows: security, simplicity, flexibility, and multi-cloud compatibility.
What’s needed is a more elegant solution - one designed specifically for the MLOps ecosystem. This is exactly what ZenML’s Service Connectors provide.
1: Service Connectors: A Technical Deep Dive
Having established the credential management challenge, let’s examine how ZenML’s Service Connectors provide a solution. This section explains what Service Connectors are, how they work under the hood, and the authentication methods they support across different platforms.
Architecture and Core Concepts
At its core, a Service Connector represents a first-class entity within ZenML that abstracts the authentication process between your ML workflows and external services. Rather than embedding authentication logic directly into your pipeline code, ZenML introduces a layer of indirection that centralizes and standardizes credential management.
The Service Connector Model
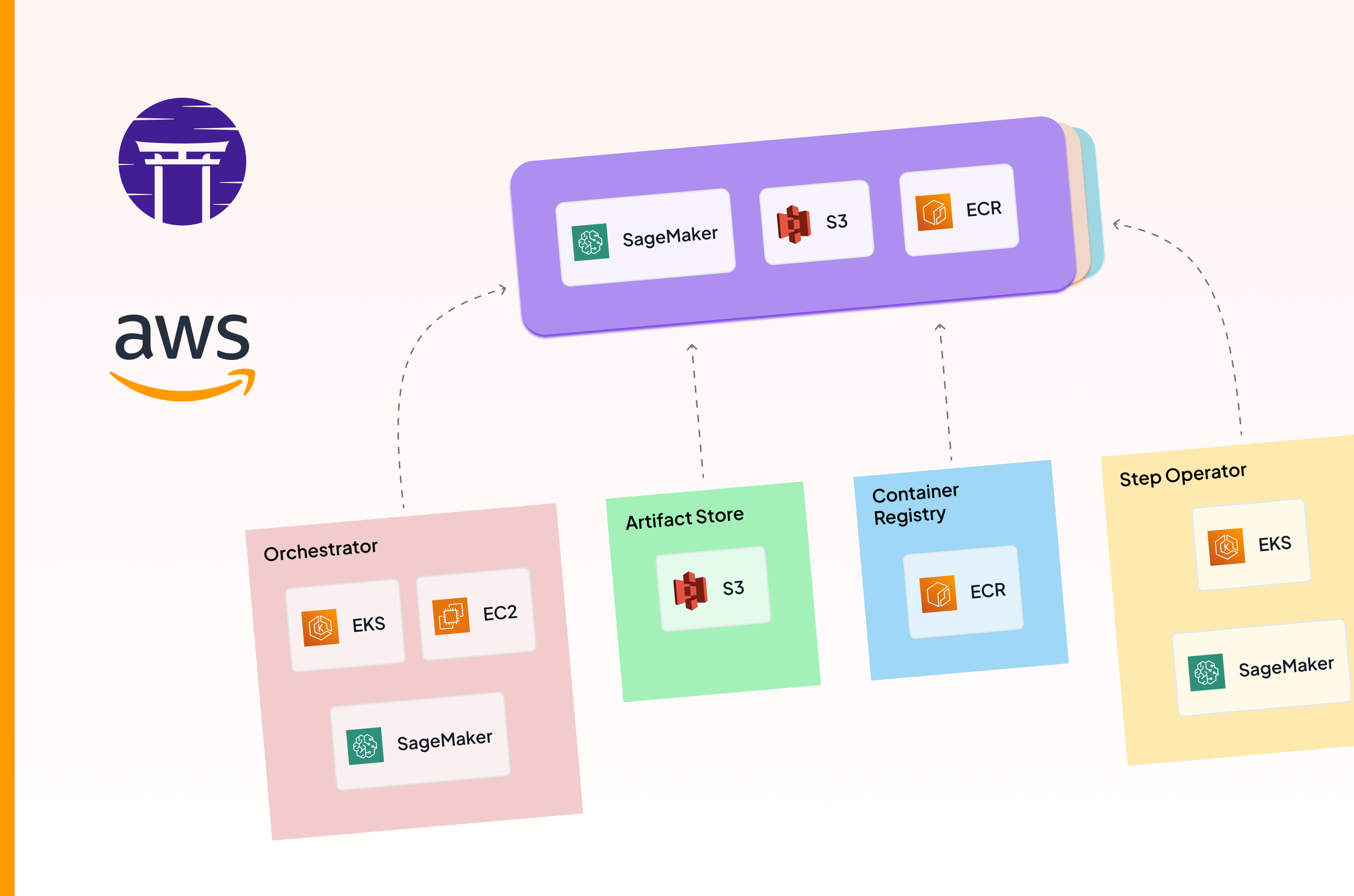
Each Service Connector belongs to a specific Service Connector Type - such as aws, gcp, azure, or kubernetes. These types define what the connector can authenticate to and how. Each connector type supports one or more Resource Types - standardized categories of external resources like s3-bucket, kubernetes-cluster, or docker-registry.
You can view available connector types with a simple CLI command:
zenml service-connector list-types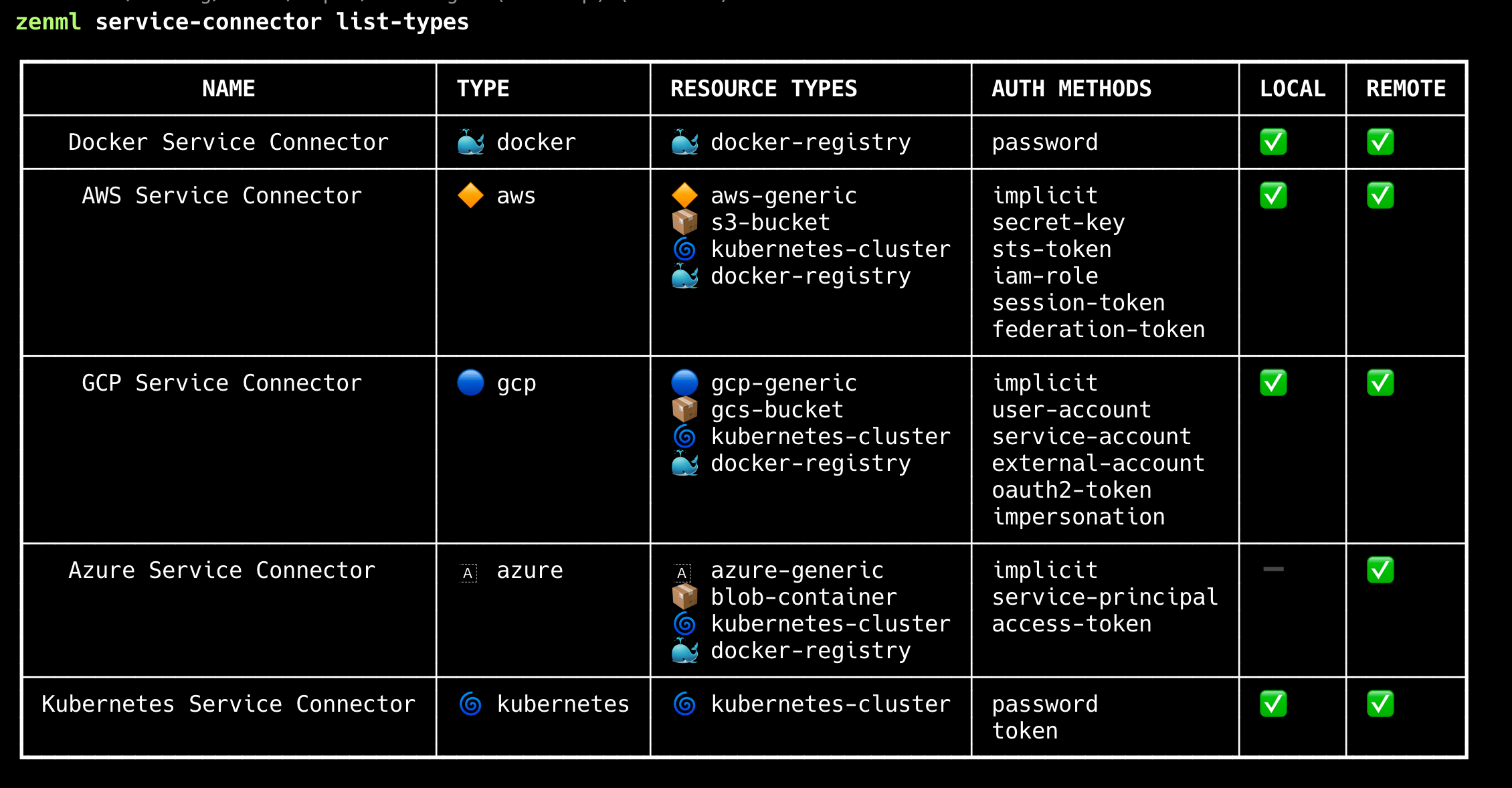
This design creates a unified language across cloud providers. Instead of dealing with the specifics of each provider’s authentication mechanisms, you work with consistent abstractions. For instance, kubernetes-cluster represents any Kubernetes implementation, whether it’s Amazon EKS, Google GKE, Azure AKS, or a self-hosted cluster.
Multi-type and Multi-instance Scoping Strategies
Service Connectors support flexible scoping strategies to match your team’s needs:
Multi-type connectors: A single connector can provide access to different resource types within the same cloud provider. For example, one AWS connector can authenticate to S3, EKS, and ECR, simplifying configuration when a single identity has permissions across services.
# Register a multi-type AWS connector
zenml service-connector register aws-multi --type aws --auth-method iam-role --region=eu-central-1 --role_arn="arn:aws:iam::123456789012:role/MLOpsRole" --aws_access_key_id=<access-key-id> --aws_secret_access_key=<secret-acces-key></secret-acces-key></access-key-id>Multi-instance connectors: A connector can be configured to access multiple instances of the same resource type - like multiple S3 buckets or Kubernetes clusters.
Single-type/Single-instance connectors: For maximum security isolation, connectors can be narrowly scoped to just one resource type or even a single specific resource.
# Register a single-instance connector for a specific S3 bucket
zenml service-connector register s3-data-connector --type aws --auth-method iam-role --region=eu-central-1 --role_arn="arn:aws:iam::123456789012:role/S3DataRole" --aws_access_key_id=<access-key-id> --aws_secret_access_key=<secret-acces-key> --resource-type s3-bucket --resource-id="s3://ml-training-data"</secret-acces-key></access-key-id>This flexibility allows teams to implement credential isolation that matches their security posture - from highly isolated environments with separate credentials per resource to simplified configurations with shared authentication.
Under the Hood: How Connectors Work
Let’s peek beneath the abstraction to understand what makes Service Connectors powerful.
Integration with ZenML’s Secret Store
Service Connectors don’t reinvent the wheel for secret storage. They build on ZenML’s existing Secret Store, meaning any long-lived credentials (like API keys or service account tokens) are securely stored and never exposed directly to pipeline code.
This integration leverages all the security features of the underlying Secret Store, including encryption at rest and the ability to use external secret managers like AWS Secrets Manager or GCP Secret Manager as backends.
Generation of Short-lived, Scoped Tokens
The real magic happens at runtime. When a ZenML stack component needs to access an external resource, the Service Connector:
- Retrieves the necessary credentials from the secret store
- Uses those credentials to obtain short-lived, scoped access tokens or sessions
- Provides authentication to the stack component (not directly to pipeline steps)
For example, with AWS, the connector might use a stored AWS secret access key to generate temporary AWS STS tokens scoped down to just the specific S3 bucket that a stack component needs. This follows the principle of least privilege - your stack component receives only the minimal permissions necessary for its tasks, and those permissions automatically expire after a short time.
The beauty of this approach is that pipeline code doesn’t need to be aware of authentication at all. When you run a pipeline using a stack with properly connected components, the authentication happens transparently behind the scenes.
Explicit Linking to Stack Components
One of the most important aspects of Service Connectors is how they integrate with ZenML’s component model. When registering stack components that need external authentication (like Artifact Stores, Orchestrators, or Model Deployers), you explicitly link them to a Service Connector:
# Register an S3 Artifact Store using a Service Connector
zenml artifact-store register s3-store --flavor=s3 --path=s3://my-bucket --connector=aws-connectorThis explicit association creates a formal, traceable dependency within ZenML’s configuration model. Unlike implicit authentication methods where determining the source of credentials requires inspecting environment variables or cloud configuration, ZenML makes the authentication intent explicit and centrally managed.
The separation between the component (what we want to use) and the connector (how we authenticate to it) enables powerful workflows, like switching authentication methods without changing your pipeline code or stack components.
Supported Platforms and Authentication Methods
ZenML Service Connectors provide comprehensive support for major cloud providers and common infrastructure services. Let’s look at the authentication methods available for key platforms.
AWS Connector
The AWS Service Connector is particularly versatile, supporting:
- Explicit long-lived keys: AWS access key ID and secret access key pairs
- IAM roles: Assuming roles via
role_arnparameter - STS tokens: Short-term Security Token Service credentials
- Implicit credentials: Auto-discovery of credentials from environment variables, AWS CLI configuration, or EC2 instance profiles
Here’s a simple example of registering an AWS connector with implicit authentication:
# Use credentials implicitly available in the local environment
zenml service-connector register aws-dev --type aws --auth-method implicitFor production use, the recommended approach is role-based:
# Use a specific IAM role
zenml service-connector register aws-prod --type aws --auth-method iam-role --region=eu-central-1 --aws_access_key_id=<access-key-id> --aws_secret_access_key=<secret-acces-key> --role_arn="arn:aws:iam::123456789012:role/MLOpsProd"</secret-acces-key></access-key-id>GCP Connector
The Google Cloud connector supports:
- Service accounts: Via JSON key files or Google's Application Default Credentials
- OAuth tokens: Short-lived tokens for user or service account identity
- Implicit authentication: Leveraging gcloud CLI configuration or GCE instance service accounts
# Register using a service account
zenml service-connector register gcp-prod --type gcp --auth-method service-account --project_id=<gcp-project> --service_account_json=@/path/to/key.json</gcp-project>Azure and Other Connectors
ZenML also provides connectors for:
- Azure: Supporting service principals, managed identities, and access tokens
- Kubernetes: Direct cluster authentication via kubeconfig files or service account tokens
- Docker: authenticating to and granting access to a Docker/OCI container registry.
- Specialized services: Connectors for services like HyperAI with SSH-based authentication
Each connector provides authenticated clients appropriate to the resource type - boto3 sessions for AWS, Google auth credentials for GCP, Kubernetes API clients for clusters, and so on.
This standardized yet comprehensive approach means your team can use the authentication method that best fits each environment and security requirement, while maintaining a consistent interface for your ML workflows.
(This is getting somewhat technical, so feel free to skip ahead if you’re just interested in the high-level benefits of Service Connectors rather than the implementation details.)interested in the high-level benefits of Service Connectors rather than theimplementation details.)
2. How ZenML Transforms the Authentication Landscape
With the technical foundation covered, let’s examine the practical impact Service Connectors have on ML workflows. This section explores how this approach greatly improves the developer experience, enhances security, and improves operational efficiency for ML teams.
A Breath of Fresh Air for Developer Experience
For data scientists and ML engineers, Service Connectors remove significant friction from the development process, letting them focus on what matters: building effective ML systems.
Reduced Boilerplate: No Credential Handling Code in Pipeline Components
Without Service Connectors, working with cloud resources in an ML workflow typically requires extensive credential handling, either in pipeline code directly or in the stack component configuration:
# Traditional approach - messy credential handling
# In a file configuring your artifact store
from zenml.artifact_stores import S3ArtifactStore
# Need to handle credentials directly in code or environment variables
aws_access_key = os.environ.get("AWS_ACCESS_KEY_ID")
aws_secret_key = os.environ.get("AWS_SECRET_ACCESS_KEY")
# Configure store with explicit credential handling
artifact_store = S3ArtifactStore(
path="s3://my-bucket",
key=aws_access_key,
secret=aws_secret_key
)This credential handling code creates dependencies on specific environment variables and cloud providers. It requires securely passing credentials across environments and keeping them in sync.
With Service Connectors, all of this goes away:
# Register a connector once with proper authentication
zenml service-connector register aws-dev --type aws --auto-configure
# Connect it to your stack component
zenml artifact-store register s3-store --flavor=s3 --path=s3://my-bucket --connector=aws-dev
# Then your pipeline code remains completely clean
@step
def train_model():
# Just focus on the ML task
model = train()
return model
The service connector handles all authentication behind the scenes. Developers no longer need to worry about credential sources, environment variables, or cloud-specific authentication methods. The pipeline code becomes cleaner, more focused, and cloud-agnostic.
Reduced Dependencies: No Need for CLI Tools and Authentication Setup
One often overlooked advantage of Service Connectors is the elimination of both CLI tools and their associated authentication processes across your ML environments. Traditionally, interacting with different cloud services requires:
- Installing CLI tools on every environment:
# Installing multiple CLI tools on each environment
sudo apt-get install -y apt-transport-https ca-certificates gnupg
echo "deb [signed-by=/usr/share/keyrings/cloud.google.gpg] https://packages.cloud.google.com/apt cloud-sdk main" | sudo tee -a /etc/apt/sources.list.d/google-cloud-sdk.list
curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key --keyring /usr/share/keyrings/cloud.google.gpg add -
sudo apt-get update && sudo apt-get install -y google-cloud-cli kubectl
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
unzip awscliv2.zip && sudo ./aws/install2.** Performing interactive authentication** on each environment:
# Interactive authentication processes
gcloud auth login # Launches browser auth flow
aws configure # Prompts for access keys
az login # Launches browser auth flow
kubectl config use-context my-cluster # Requires pre-configured kubeconfigThis creates significant challenges:
- Environment Setup Complexity: Each environment requires both tool installation and authentication
- Non-Automatable Flows: Browser-based authentication is difficult to automate in CI/CD
- Credential Synchronization: Keeping authenticated sessions valid across environments
- Security Risks: Long-lived credentials often stored in plain text configuration files
- Maintenance Burden: CLI tools need regular updates and re-authentication
ZenML Service Connectors eliminate these problems entirely. With Service Connectors:
- No CLI tools needed: Authentication happens through ZenML's built-in client libraries
- No interactive login flows: Authentication is configured once via Service Connectors
- No local credential files: Credentials are securely stored in the ZenML backend
- No environment-specific setup: Authentication works consistently across all environments
# No CLI installation or authentication needed
@step
def process_cloud_data():
# ZenML handles authentication behind the scenes
# No 'gcloud auth login' or 'aws configure' required
...This dramatically simplifies your ML workflow setup. Your Docker images become smaller, your CI/CD pipelines more reliable, and your development onboarding process streamlined. The only exceptions are services like Docker that require client software for functionality beyond authentication.
For teams managing multiple environments across development, testing, and production, eliminating these CLI dependencies and authentication steps represents a significant reduction in operational overhead and security risk.
Auto-configuration for Quick Local Development Setup
Getting started with cloud resources traditionally requires navigating complex console UIs or CLI commands to set up credentials. Service Connectors simplify this with auto-configuration:
zenml service-connector register aws-dev --type aws --auto-configure --interactiveThis command detects and imports credentials from your local environment, significantly lowering the barrier to entry. A developer with the AWS CLI already configured can immediately connect ZenML to their cloud resources without manually copying keys or setting environment variables.
Auto-configuration works across development environments, making the transition from laptops to CI/CD systems smoother and reducing setup time from hours to minutes.
Simplified Multi-cloud Workflows
Perhaps most impressively, Service Connectors make multi-cloud ML workflows practical rather than just theoretical. Developers can build stacks that combine components authenticated to different cloud providers, without dealing with the complexity of different credential types:
# Register connectors for multiple clouds
zenml service-connector register aws-dev --type aws --auto-configure
zenml service-connector register gcp-dev --type gcp --auto-configure
# Use them with different stack components
zenml artifact-store register aws-store --flavor=s3 --path=s3://my-bucket --connector=aws-dev
zenml container-registry register gcr-registry --flavor=gcp --connector=gcp-dev
# Create a multi-cloud stack
zenml stack register hybrid-stack --artifact-store=aws-store --container-registry=gcr-registryBehind the scenes, ZenML handles the different authentication mechanisms required by each cloud provider. Pipeline code remains completely agnostic to where resources are located. This enables teams to:
- Use the best service from each cloud provider in a single pipeline
- Transition gradually from one cloud to another
- Implement disaster recovery across clouds
- Avoid cloud lock-in by keeping code provider-agnostic
Enhanced Security Posture
Beyond developer experience, Service Connectors significantly improve the security of ML workflows.
Credentials Decoupled from Code and Pipeline Configuration
The Service Connector approach enforces a clean separation between authentication and application logic. Credentials are never embedded in code, configuration files, or Docker images, eliminating a common source of secret leakage.
This decoupling also means credentials can be rotated or replaced without changing pipeline code. If a key is compromised, you update the connector configuration, not dozens of pipeline files.
Principle of Least Privilege through Short-lived, Scoped Tokens
Service Connectors implement security best practices by default:
- Temporary credentials: Instead of long-lived API keys, connectors generate short-lived tokens (like AWS STS tokens) that automatically expire
- Minimal scope: Permissions can be limited to exactly what's needed for a specific resource, following the principle of least privilege
- Context-specific access: Each component receives only the credentials it needs, preventing access sprawl
For example, the AWS connector can generate temporary STS tokens scoped to a specific S3 bucket with read-only permissions, even if the underlying IAM role has broader access.
Centralized Management Reduces Credential Sprawl
Without centralization, credentials tend to proliferate across environments, configuration files, CI/CD systems, and team members’ machines. This “credential sprawl” increases the attack surface and complicates audit and compliance efforts.
Service Connectors establish a single source of truth for all authentication configurations. This centralization enables:
- Complete visibility into which credentials exist and where they're used
- Simplified credential rotation and management
- Consistent enforcement of security policies
- Easier compliance with regulatory requirements
Operational Efficiency for Teams
Beyond individual developers, Service Connectors transform how entire ML teams work together.
Clear Separation of Responsibilities
In mature ML organizations, platform teams are responsible for infrastructure and security, while ML teams focus on model development. Service Connectors formalize this separation of concerns:
- Platform engineers configure and manage connectors with appropriate security settings
- ML engineers consume these connectors in their workflows, without needing to understand the underlying authentication mechanisms
This clear division of responsibilities improves both security and productivity. Platform teams maintain control over credentials, while ML teams get frictionless access to the resources they need.
RBAC Controls for Connector Usage
In ZenML Pro, Role-Based Access Control (RBAC) adds another layer of security and governance:
- Administrators can control who can create, update, or use specific connectors
- Teams can be restricted to connectors appropriate for their projects
- Production connectors can be protected from unauthorized use
These permissions ensure that development teams can’t accidentally use production credentials, and that credential access is limited to authorized users.
Simplified Credential Rotation and Management
Managing credential lifecycles - from creation to rotation to revocation - is a critical but often neglected operational task. Service Connectors simplify this process by providing a centralized interface for credential management.
When credentials need rotation, operators update a single connector configuration rather than chasing down credentials scattered across multiple systems. This makes regular rotation practical rather than aspirational, significantly improving the security posture.
Additionally, connectors can be tagged and labeled to track their purpose, ownership, and expiration, making credential management more systematic and less error-prone.
In combination, these transformations fundamentally change how ML teams work with external resources. Instead of authentication being a persistent source of friction and security risk, Service Connectors turn it into a seamless, secure, and manageable aspect of the ML development lifecycle.
3. Comparative Analysis: Service Connectors vs. Alternative Approaches
To fully appreciate the value of ZenML’s Service Connectors, it’s helpful to compare them with alternative approaches to authentication in ML systems. This section examines how Service Connectors stack up against other MLOps platforms and traditional methods.
ZenML vs. Kubernetes-Native Solutions (KFP, Flyte)
Kubernetes-native ML platforms like Kubeflow Pipelines (KFP v2) and Flyte have become popular choices for orchestrating ML workflows. Let’s examine their approach to authentication and credential management.
KFP: Kubernetes Primitives for Authentication
Kubeflow Pipelines relies heavily on standard Kubernetes primitives for authentication:
- Kubernetes Service Accounts: Pipeline steps execute as pods that use a Kubernetes Service Account identity
- Kubernetes Secrets: Credentials are stored as K8s Secrets and mounted into pods as files or environment variables
- Cloud IAM Integration: On cloud providers, K8s Service Accounts can be linked to cloud IAM roles (AWS IRSA, GCP Workload Identity)
For example, KFP provides helpers to mount secrets into tasks:
# KFP example - using secrets for AWS credentials
import kfp
from kfp.kubernetes import use_secret_as_env
@kfp.dsl.component
def process_s3_data():
# Function implementation...
pass
# In pipeline definition
task = process_s3_data()
use_secret_as_env(
task,
secret_name='aws-secret',
env_vars=[
('AWS_ACCESS_KEY_ID', 'access_key'),
('AWS_SECRET_ACCESS_KEY', 'secret_key')
]
)For artifact storage, KFP v2 introduced configuration in the launcher ConfigMap to specify storage provider credentials, but this is limited to artifact storage, not a general credential solution. This config mechanism allows defining storage providers (Minio, S3, GCS) with either a secret reference or a flag to use ambient credentials but doesn’t extend beyond artifact storage to other services.
Flyte: Secret Management with K8s Foundation
Flyte provides a slightly higher-level abstraction through its Secrets system:
- Flyte Secret API: A built-in API to request secrets in tasks via the
@taskdecorator - Kubernetes Secrets Backend: By default, secrets are stored in K8s Secrets (other backends are configurable)
- Runtime Injection: Secrets are injected into task containers as environment variables or files
# Flyte example - requesting secrets in a task
import flytekit as fl
@fl.task(secret_requests=[fl.Secret(group="database", key="password")])
def connect_to_database():
password = fl.current_context().secrets.get("database", "password")
# Use password for database connectionFlyte’s approach is more structured than raw Kubernetes secrets, but the abstraction remains generic rather than ML-specific. It’s essentially a mechanism for securely injecting credentials at runtime, integrated with Flyte’s task execution model.
Both KFP and Flyte approaches have limitations:
- No Unified Connector Abstraction: Neither offers a unified "connector" concept for external services - authentication is handled separately for each service
- Pod-Centric Authentication: Authentication is tied to pod execution, making local development and testing complicated
- Platform-Specific Configuration: Each Kubernetes platform requires different configuration (EKS vs. GKE vs. AKS)
- ML-Specific Resource Types Missing: There's no concept of ML-specific resource types with associated authentication methods
Data scientists must understand Kubernetes Service Accounts, secrets, and cloud-specific configurations. This knowledge barrier creates friction and often leads to over-permissioning for simplicity.
As of 2025, neither KFP v2 nor Flyte has introduced a higher-level credential abstraction that provides unified management across services. They continue to rely primarily on Kubernetes primitives (secrets, service accounts) with some convenience wrappers.
In contrast, ZenML’s Service Connectors provide a higher-level API that abstracts away Kubernetes complexity:
# ZenML approach - no Kubernetes expertise needed
zenml service-connector register aws-conn --type aws --auth-method iam-role \\
--role_arn=arn:aws:iam::123456789012:role/my-role
zenml artifact-store register s3-store --flavor=s3 --path=s3://my-bucket \\
--connector=aws-connThis higher-level abstraction makes authentication accessible to ML practitioners without requiring Kubernetes expertise, while still leveraging secure authentication mechanisms under the hood.
ZenML vs. Other MLOps Orchestrators (Airflow, Prefect, Metaflow)
General-purpose workflow orchestrators take varied approaches to credential management. Let’s examine how ZenML compares to several popular options.
Airflow Connections: Generic Credential Store
Apache Airflow handles external authentication through Connections, which store endpoint and credential information for various services:
# Airflow connection defined via environment variable
# AIRFLOW_CONN_MY_AWS_CONN='{"conn_type": "aws", "login": "AKIAIOSFODNN7EXAMPLE",
# "password": "wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY", "extra": {"region_name": "us-west-2"}}'
# Use in DAG
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
def process_data(**context):
s3_hook = S3Hook(aws_conn_id='my_aws_conn')
s3_client = s3_hook.get_conn()
# Use s3_client...While Connections serve a similar purpose to ZenML’s Service Connectors, there are key differences:
- Generic Interface: Airflow Connections are general-purpose, not specifically designed for ML workflows
- Limited Schema: Connections primarily have host/login/password/extra fields with the "type" determining how fields are interpreted
- Operator/Hook-Centric: Users must select the appropriate hook (e.g., S3Hook, GCSHook) for each service and pass the connection ID
- No Resource Typing: There's no concept of resource types - a connection just stores credentials that hooks interpret
- No Cross-Service Abstraction: Each service requires its own connection setup and hook usage pattern
Airflow Connections can be stored in the Airflow database or fetched from external secret backends (HashiCorp Vault, AWS Secrets Manager, etc.), providing secure credential storage. However, they lack the ML-specific abstractions and multi-service unification that ZenML Service Connectors provide. This remains true in the latest Airflow 2.x versions as of 2025. While Airflow has expanded its provider ecosystem with more integrations, the underlying Connections system still follows the same model - a generic credential store without ML-specific abstractions or a unified cross-service interface.
Prefect Blocks: Similar Concept but Different Implementation
Prefect (v2 and v3) uses Blocks - typed, schema-defined objects that store credentials and other configuration. Blocks are conceptually similar to ZenML’s Service Connectors but differ in important ways:
- Python-First Definition: Blocks are defined as Python classes rather than CLI commands
- Generic Configuration Store: Blocks can store any configuration, not just authentication
- Service-Focused, Not ML-Specific: Each Block typically wraps a single service (AWS, GCP, etc.) without ML-specific resource typing
- Helper Methods Included: Blocks often include methods to interact with the target service
Prefect example:
from prefect_aws import S3Bucket, AwsCredentials
from prefect.blocks.system import Secret
# Register in UI or code
aws_credentials = AwsCredentials(
aws_access_key_id="access_key",
aws_secret_access_key="secret_key"
)
aws_credentials.save("prod-credentials")
# Use in flow
@flow
def process_data():
credentials = AwsCredentials.load("prod-credentials")
s3_bucket = S3Bucket(bucket_name="my-bucket", credentials=credentials)
# Use s3_bucket methods like .download_object() or .upload_from_path()While Prefect Blocks provide a secure way to store and use credentials, there are key differences from ZenML Service Connectors:
- No unified cross-service credential abstraction - you manage each Block separately
- No ML-specific resource typing built into the system
- Each Block is used directly in your flow code, rather than being connected to stack components
Prefect 3 maintains the same Blocks system as Prefect 2, with technical improvements to the underlying implementation (such as using Pydantic v2 for schemas). These changes don’t fundamentally alter how credential management works in Prefect - it remains a typed but generic configuration system rather than an ML-specific abstraction layer.
ZenML’s approach offers more ML-specific abstractions, stronger connections to ML stack components, and a unified interface for credential management across different services.
Metaflow’s Approach: Environment Inheritance with @secrets
Metaflow takes a different approach to authentication, with both implicit and explicit credential handling:
- Environment Inheritance: Metaflow steps inherit cloud credentials from the execution environment (EC2, Batch, etc.). Historically, this was Metaflow's primary authentication mechanism, emphasizing cloud-native design where IAM roles or environment credentials are automatically used.
- @secrets Decorator: For non-IAM secrets, Metaflow introduced the
@secretsdecorator in 2023 that can fetch credentials from AWS, GCP, or Azure secret managers at runtime
Metaflow example:
from metaflow import FlowSpec, step, secrets
class TrainingFlow(FlowSpec):
@step
@secrets(sources=['database-credentials'])
def load_data(self):
# Database password is available as an environment variable
# AWS credentials come from the execution environment
import boto3
s3 = boto3.client('s3') # Uses IAM role of the execution environment
# Process data...The @secrets decorator securely pulls credentials at runtime from a cloud secrets manager, without requiring credentials to be present in code or configuration files. This addition addresses a significant limitation in earlier Metaflow versions, where non-IAM credentials required manual handling. However, this approach still has constraints:
- The execution environment must have permission to access the secrets manager
- You must manually store credentials in the configured secrets manager beforehand
- There is no unified "connector" abstraction across different services
- The system is designed around a single cloud provider per deployment
While Metaflow’s approach is elegant for single-cloud deployments and the @secrets decorator improves security for third-party services, ZenML Service Connectors provide more flexibility with explicit authentication methods, resource-specific scoping, and unified multi-cloud credential management. ZenML’s connector abstraction offers resource typing and cross-service credential management that Metaflow’s approach doesn’t address.
ZenML vs. Cloud-Native ML Platforms
Cloud providers offer their own ML platforms (AWS SageMaker, GCP Vertex AI, Azure ML) with tightly integrated authentication systems, each locked into their respective cloud’s identity framework.
Cloud-Native Platforms: Deep Integration but Cloud-Specific
Each cloud ML platform uses its proprietary identity system for authentication, with no support for cross-cloud credential management:
AWS SageMaker
SageMaker is deeply integrated with AWS IAM. Any operation requires IAM roles that grant SageMaker permission to access AWS resources:
# SageMaker approach - tightly coupled to AWS IAM
estimator = sagemaker.estimator.Estimator(
image_uri='...',
role='arn:aws:iam::123456789012:role/SageMakerExecutionRole',
# Other parameters...
)The IAM execution role is assumed by SageMaker to access S3 data, write logs, and manage resources. This provides a secure, AWS-native approach to authentication, but for any non-AWS services, you would need to manually handle credentials in your code or use AWS Secrets Manager, which is just another AWS service. SageMaker has no concept of managing credentials for non-AWS resources through a unified interface.
Google Cloud Vertex AI
Vertex AI relies entirely on Google Cloud IAM and service accounts:
# Vertex AI example - uses GCP service accounts
from google.cloud import aiplatform
# Implicit authentication via Application Default Credentials
# (from service account attached to compute resource)
aiplatform.init(project='my-project', location='us-central1')
# Run training job with specific service account
job = aiplatform.CustomTrainingJob(
display_name='my-training-job',
script_path='train.py'
)
job.run(service_account='[email protected]')Vertex AI uses the service account attached to the compute resource or an explicitly specified service account for all its authentication needs. The documentation explicitly recommends using the service account attached to the compute resource running the code. For non-GCP services, you’d need to implement your own credential management solution within your code.
Azure Machine Learning
Azure ML uses Azure Active Directory (AAD) (aka Entra ID) identities and managed identities:
# Azure ML example - uses managed identities
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# Authenticate using the Azure compute's managed identity
credential = DefaultAzureCredential()
ml_client = MLClient(
credential=credential,
subscription_id="...",
resource_group_name="...",
workspace_name="..."
)
# The compute clusters and endpoints also use managed identitiesWhen an Azure ML Workspace is created, a system-assigned managed identity is enabled by default. This identity is used to access Azure resources like storage accounts and Key Vault. For non-Azure resources, you would need to store credentials in Azure Key Vault and retrieve them in your code.
Common limitations across all cloud-native ML platforms:
- Cloud-Specific Authentication: Each uses only its own identity system (IAM, GCP IAM, Azure AD) with no built-in abstractions for other cloud providers
- No Cross-Cloud Abstraction: There's no built-in way to authenticate to other clouds' services through a unified interface
- ML Platform Lock-in: Authentication is coupled to the ML platform, making migration difficult
- No Resource-Type Concept: These platforms don't have a general abstraction for resource types across clouds
As of 2025, none of these cloud platforms has introduced cross-cloud credential management capabilities. They remain tightly integrated with their own cloud’s identity systems, with no support for a unified credential abstraction.
Multi-Cloud with ZenML: A Unified Approach
ZenML’s Service Connectors provide a cloud-agnostic alternative that works across environments:
# Register connectors for multiple clouds
zenml service-connector register aws-conn --type aws --auth-method iam-role \\
--role_arn=arn:aws:iam::123456789012:role/my-role
zenml service-connector register gcp-conn --type gcp --auth-method service-account \\
--service_account_json=@path/to/service-account.json
# Use them interchangeably in your ML stack
zenml artifact-store register aws-store --flavor=s3 --connector=aws-conn \\
--path=s3://my-bucket
zenml model-deployer register gcp-deployer --flavor=vertex --connector=gcp-connThis abstraction provides several advantages:
- Unified Interface: One consistent way to handle credentials across all clouds
- Reduced Lock-in: ML code is decoupled from authentication mechanisms
- Simplified Migration: Switch clouds by updating connector configurations, not code
- Multi-Cloud Capability: Use services from multiple clouds in a single workflow
While cloud-native ML platforms optimize for their own ecosystems, ZenML’s Service Connectors are designed for the modern multi-cloud reality that many organizations face.
ZenML vs. Manual Methods
Finally, let’s compare Service Connectors to the manual approaches many teams default to when starting their ML journey.
Direct SDK Usage: Flexible but Repetitive and Error-Prone
Directly using cloud SDKs gives maximum flexibility but creates significant challenges:
# Manual AWS SDK usage
import boto3
import os
# Credential boilerplate repeated in each component
aws_access_key = os.environ.get('AWS_ACCESS_KEY_ID')
aws_secret_key = os.environ.get('AWS_SECRET_ACCESS_KEY')
s3 = boto3.client(
's3',
aws_access_key_id=aws_access_key,
aws_secret_access_key=aws_secret_key
)
# Use s3 client...This approach leads to:
- Credential Duplication: The same credential logic is repeated across multiple files
- No Abstraction Layer: Code is tightly coupled to specific cloud providers
- Security Risks: Credentials often end up hardcoded or in environment variables that can be leaked
Environment Variables: Simple but Insecure and Difficult to Manage at Scale
Environment variables are the default approach for many teams:
# Setting environment variables manually
export AWS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE
export AWS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
export S3_BUCKET=my-training-data
# Then in Python
import boto3
import os
s3 = boto3.client('s3') # Uses environment variables automatically
bucket_name = os.environ.get('S3_BUCKET')This method has critical flaws:
- Security Issues: Environment variables can be logged, exposed in error messages, or leaked through child processes
- Management Overhead: Coordinating variables across environments becomes a manual task
- No Access Control: Anyone with access to the environment can see all credentials
How ZenML Avoids These Pitfalls While Maintaining Flexibility
ZenML Service Connectors address these challenges without sacrificing flexibility:
- Centralized Management: Credentials are stored and managed in one place
- Secure Handling: Sensitive information is stored in the Secret Store, not environment variables
- Flexible Authentication: Support for various authentication methods, from API keys to IAM roles
- Simplified Interface: A consistent API across clouds and services
The result is a solution that combines the security of enterprise secret management with the simplicity needed for productive ML development.
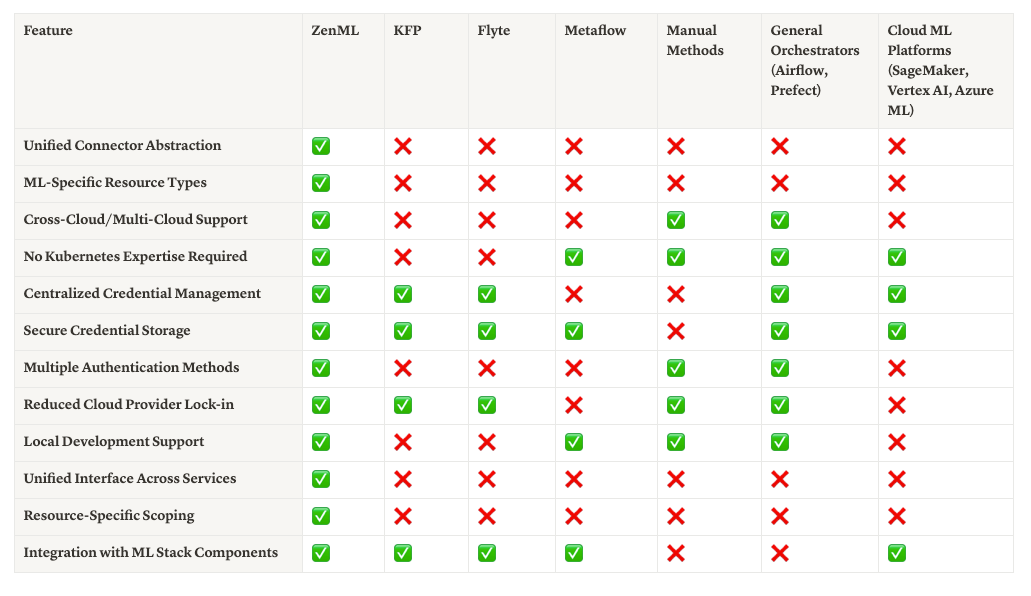
While every approach has its place, ZenML Service Connectors stand out by providing a balance of security, usability, and flexibility that’s specifically tailored to ML workflows. They abstract authentication complexity without limiting capabilities, creating a foundation for scalable, secure ML pipelines across any environment.
4. The Connector Advantage
We’ve covered significant ground in this exploration of ZenML’s Service Connectors from the credential management challenges that plague ML teams to the technical architecture and practical implementations that address these challenges. As we conclude, let’s reflect on the key advantages and consider how to get started with Service Connectors in your own ML workflows.
Recapping the Key Benefits
Service Connectors fundamentally transform how ML teams interact with external resources by striking a careful balance between competing priorities:
Balancing Security and Developer Experience
The traditional tradeoff between security and developer experience is a false dichotomy. Proper abstraction can deliver both, and that’s exactly what Service Connectors achieve:
- For Security Teams: Centralized credential management, implementation of least privilege, audit trails, and support for secure authentication methods like IAM roles and short-lived tokens
- For Developers: Abstracted authentication complexity, no credential handling code, auto-configuration for quick setup, and consistent interfaces across environments
This balance is particularly important in ML, where security requirements often conflict with the exploratory, iterative nature of model development. Service Connectors let security teams define guardrails while giving data scientists and ML engineers the flexibility they need to innovate.
Operational Efficiency from Standardization
Beyond individual benefits, Service Connectors drive organizational efficiency through standardization:
- Reduced Duplication: Centralized configuration eliminates redundant credential handling across teams and projects
- Simplified Onboarding: New team members can access resources without deep knowledge of cloud-specific authentication mechanisms
- Streamlined Troubleshooting: Authentication issues become easier to diagnose and resolve when there's a single point of configuration
- Consistent Security Practices: Security policies can be implemented consistently across teams through the connector abstraction
This standardization compounds over time. As the number of ML pipelines, team members, and external services grows, the operational savings from a unified approach to authentication increase dramatically.
Getting Started Today
If you’re convinced of the value of Service Connectors, here’s how to start incorporating them into your ML workflows:
Resources for Learning More
The ZenML documentation provides comprehensive resources for implementing Service Connectors:
- Service Connectors Guide: A complete reference for Service Connector concepts, commands, and configurations
- Cloud Provider Guides: Specific guidance for AWS, GCP, Azure and other providers
- Best Security Practices: Recommendations for implementing Service Connectors securely
Additionally, the ZenML GitHub repository includes examples and integration tests that demonstrate Service Connectors in action. These resources can help you understand how Service Connectors fit within larger ML workflows.
Call to Action: Try ZenML Pro with Service Connectors
The fastest way to experience the benefits of Service Connectors is to try them with ZenML Pro:
1. Sign up for ZenML Pro at cloud.zenml.io
2. Register your first Service Connector using auto-configuration:
zenml service-connector register aws-dev --type aws -i3. Connect a stack component to your cloud resources:
zenml artifact-store register s3-store \\
--flavor=s3 \\
--path=s3://my-bucket \\
--connector=aws-dev4. Run a pipeline that uses the authenticated component:
@step
def train_model():
# No credential handling needed!
model = train()
return model
@pipeline
def training_pipeline():
train_model()
# Run the pipeline using a stack with authenticated components
training_pipeline()Within minutes, you can experience ML workflows without the credential headaches. As your needs grow, ZenML Cloud provides team management features, audit logs, and enhanced security controls to support production ML operations.
The Unsexy Hero of MLOps
Authentication and credential management may not be the most exciting topics in ML. They lack the glamour of cutting-edge architectures or state-of-the-art performance metrics. But they’re essential underpinnings of any robust ML system.

Service Connectors may be the unsung hero of the MLOps landscape, quietly solving a pervasive, frustrating problem that consumes engineer time and creates security risks. By abstracting authentication complexity, they let ML teams focus on what matters: delivering value through machine learning.
Whether you’re a solo practitioner building your first ML pipelines or a platform engineer supporting hundreds of data scientists, Service Connectors provide a foundation for secure, efficient, and flexible ML workflows. They’re a small concept with outsized impact and that’s the hallmark of great design.
We invite you to experience this impact firsthand by incorporating Service Connectors into your ML workflows. Your security team, your developers, and your future self will thank you.