

On this page
The tech industry is experiencing a seismic shift with the rise of Large Language Models (LLMs) and other GenAI applications. While demos and proofs of concept paint pictures of limitless possibilities, the reality of deploying these models in production environments tells a more nuanced story. Drawing from the LLMOps Database—a comprehensive collection of over 300 real-world case studies from the past two years—we’ve uncovered valuable patterns and insights about what actually works when putting LLMs into production.
This isn’t just another theoretical exploration. The LLMOps Database serves as a compass of sorts, offering concise, practical summaries of videos, blogs, websites, research papers, and PDFs. It focuses on what matters most: architectural decisions, technical challenges, and hard-won lessons from the field. As we navigate through this analysis, we’ll cut through the hype to examine what’s actually working in production deployments.
All our posts in this series will include NotebookLM podcast ‘summaries’ that capture the main themes of each focus. Today’s blog is about the grand summary, the overview of the entirety of the database, so that’s what the hosts discuss in this audio snapshot.
The Agent Paradox: When Ambition Meets Reality
The concept of autonomous AI agents has captured the collective imagination of many, promising to revolutionize how we approach complex tasks. Companies like Devin Kearns and Factory.ai are pushing boundaries in building AI agent teams, while others like Kentauros AI tackle fundamental reasoning challenges. The excitement is palpable, with startups like Parcha and Unify exploring increasingly sophisticated agent-based solutions.
Yet, there’s a striking disconnect between the promise of fully autonomous agents and their presence in customer-facing deployments. This gap isn’t surprising when we examine the complexities involved. The reality is that successful deployments tend to favor a more constrained approach, and the reasons are illuminating. (For more on this, do give Langchain’s State of AI Agents report a read.)
Take Lindy.ai’s journey: they began with open-ended prompts, dreaming of fully autonomous agents. However, they discovered that reliability improved dramatically when they shifted to structured workflows. Similarly, Rexera found success by implementing decision trees for quality control, effectively constraining their agents’ decision space to improve predictability and reliability.
This doesn’t mean the dream of autonomous agents is dead—far from it. The field is evolving rapidly, with promising developments like Arcade AI’s tool-calling platform pushing the boundaries of what’s possible. Replit’s integration of LangSmith for advanced monitoring shows how we’re developing better ways to understand and control agent behavior. The path forward appears to be one of careful constraint rather than unbounded autonomy, at least for now.
From POC to Production: A Journey of Careful Steps
The transition from proof-of-concept to production remains one of the most challenging aspects of LLM deployment, and our database reveals fascinating patterns in how organizations navigate this journey. Many case studies—from Thomson Reuters’ LLM playground to BNY Mellon’s virtual assistant and Alaska Airlines’ NLP search pilot—reveal a landscape dominated by internal tools and limited deployments.
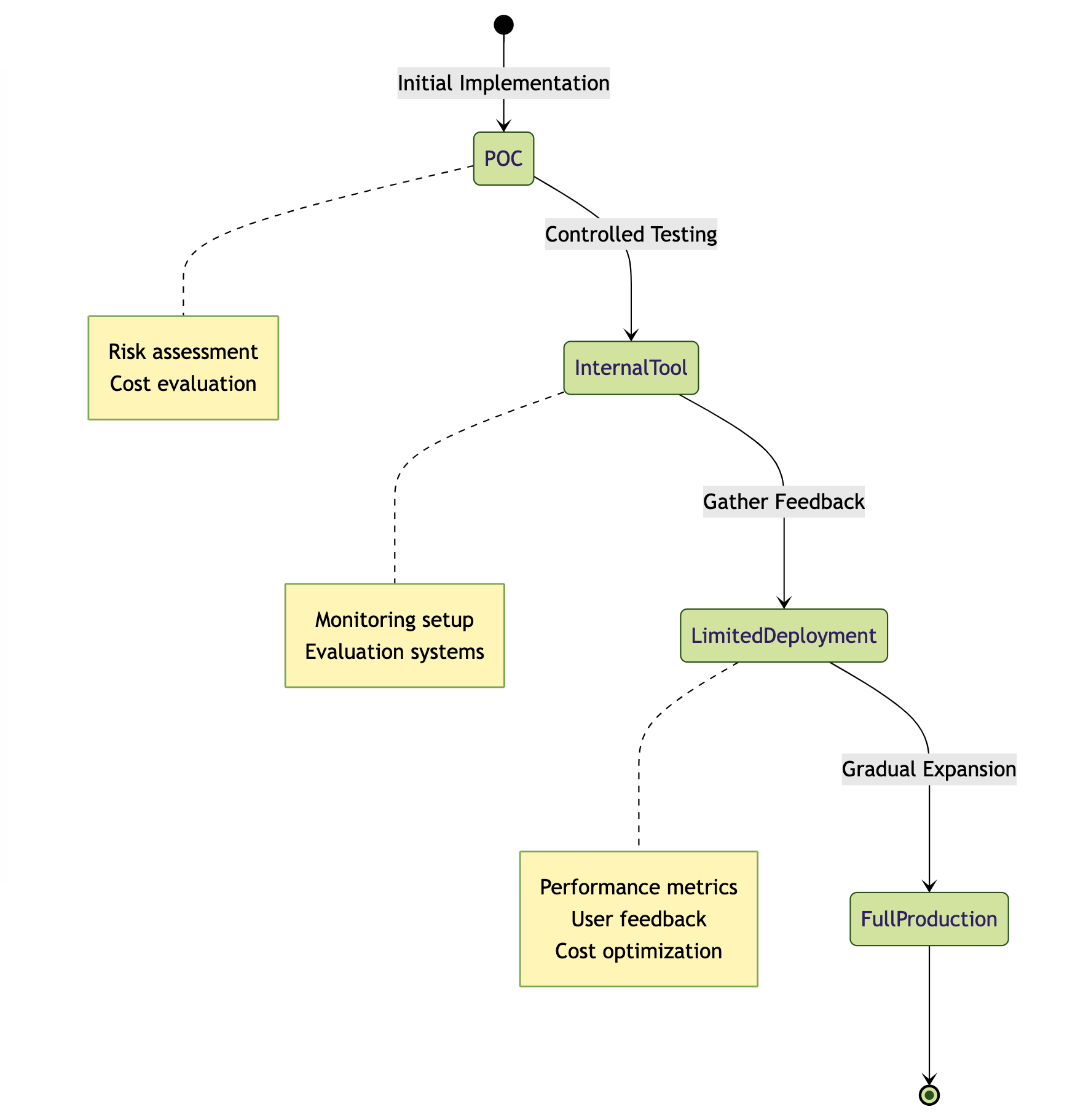
This pattern isn’t a shortcoming but rather reflects the prudent approach organizations are taking with this transformative technology. The reasons for this careful approach are multifaceted: risk aversion (especially pronounced in regulated sectors), the need for robust evaluation and monitoring systems, and the unpredictable nature of scaling costs.
Success stories like Klarna’s AI customer service assistant, Doordash’s Dasher support system, and GitHub’s Copilot didn’t emerge overnight. They’re the result of careful, phased rollouts that prioritized learning and iteration over speed to market. These organizations started small, gathered feedback meticulously, and expanded gradually—a strategy that has proven particularly crucial in regulated sectors where the stakes of deployment are significantly higher.
The Data Renaissance in LLMOps
While LLMs have introduced novel challenges, the fundamental importance of data quality and infrastructure has only grown stronger. The field builds upon established DevOps and MLOps principles, as evidenced by Barclays’ MLOps evolution case study, but with unique twists that reflect the specialized needs of language models.
The role of data engineering has expanded significantly in the LLMOps ecosystem. Take Notion’s implementation of their data lake or Grab’s sophisticated data classification system—these examples highlight how traditional data engineering roles have evolved to meet the demands of LLM deployments. QuantumBlack’s detailed discussion of data engineering challenges reveals how the field is grappling with new complexities while maintaining robust engineering principles.
The emergence of specialized infrastructure, particularly vector databases like Pinecone, Weaviate, Faiss, ChromaDB, and Qdrant, shows how the field is adapting to new requirements. These tools aren’t just nice-to-have additions; they’re becoming fundamental components of production LLM systems, enabling efficient storage and retrieval of the massive embedding spaces that modern language models require.
Architectural Patterns: Pragmatic Solutions Emerge
As organizations move beyond experimentation, clear patterns have emerged in successful LLM deployments. Retrieval-Augmented Generation (RAG) has established itself as a foundational approach, seen in implementations from Amazon’s Pharmacy Chatbot to various banking applications. While RAG helps ground responses and reduce hallucinations, it’s not without its challenges, particularly around context windows and retrieval quality.
Fine-tuning, despite its costs, has found its niche in specific use cases. Digits’ question generation system and Swiggy’s food search demonstrate how targeted fine-tuning can deliver value when applied judiciously. Airtrain’s cost reduction case study provides valuable insights into when fine-tuning smaller models can actually be more cost-effective than using larger, general-purpose models.
However, the most successful implementations often combine approaches. Walmart’s product categorization system and eBay’s three-track approach show how hybrid architectures can leverage the strengths of different techniques while mitigating their individual weaknesses. The emergence of microservices architectures, as seen in PagerDuty’s LLM service and Dust.tt’s agent platform, demonstrates how organizations are building for scalability and flexibility.
Honeycomb’s query assistant provides an excellent example of how microservices architecture enables independent scaling and easier maintenance. These modular approaches allow organizations to evolve different components of their LLM systems independently, crucial for maintaining agility in a rapidly evolving field.
Tackling Technical Challenges Head-On
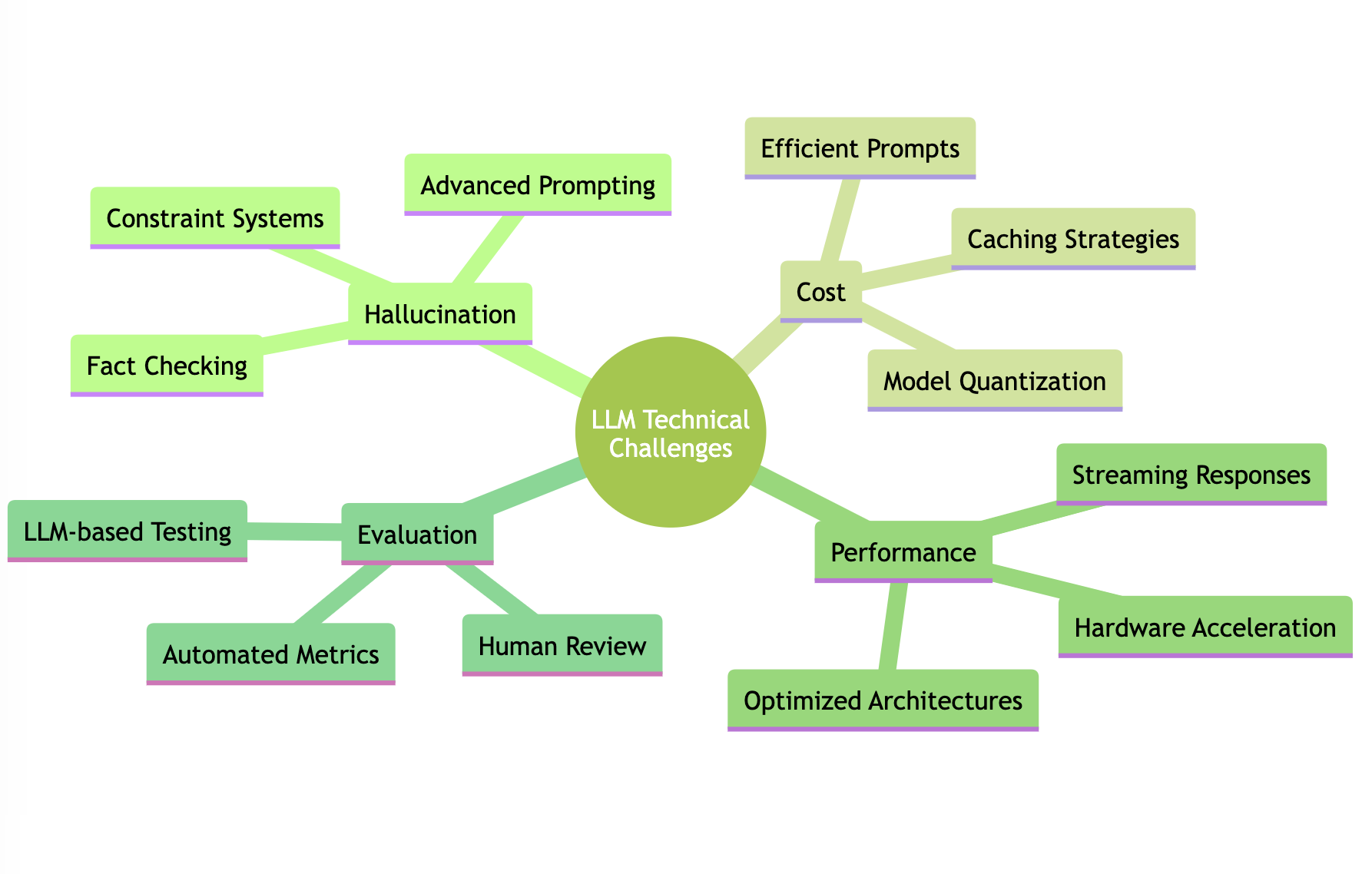
The path to production LLMs is marked by several persistent technical challenges, each requiring sophisticated solutions. Hallucination remains a primary concern, but companies have developed increasingly sophisticated mitigation strategies. Instacart and Canva have shown success with advanced prompt engineering, while others like Anzen and Lemonade implement robust constraint systems. The key insight here is that hallucination isn’t a single problem but rather a hydra requiring multiple coordinated approaches to address effectively.
Cost optimization has emerged as a critical focus area, particularly as organizations scale their LLM deployments. The strategies here are multifaceted: efficient prompts, smaller models, quantization, and intelligent caching strategies all play crucial roles. Companies like Bito demonstrate how thoughtful architecture decisions around API usage versus self-hosting can significantly impact the bottom line. The “Cost Optimization Panel” sessions in our database reveal how organizations like Faire are developing sophisticated approaches to balancing cost and performance.
Performance considerations, particularly around latency, have driven innovation in model optimization and deployment strategies. Perplexity and RealChar showcase the effectiveness of streaming approaches, while Uber’s DragonCrawl implementation highlights the benefits of hardware acceleration through GPUs and TPUs, as well as AWS Trainium for specialized workloads.
Evaluation and monitoring have emerged as crucial components of successful LLM deployments. Companies like Weights & Biases and Fiddler are pioneering new approaches to LLM evaluation, while Slack’s implementation demonstrates the importance of continuous feedback loops. The “LLM Evaluation Panel” discussions in our database reveal a growing sophistication in how organizations approach quality assessment, combining automated metrics with human evaluation and LLM-based testing approaches.
The Path Forward
The LLMOps landscape continues to evolve rapidly, but clear patterns have emerged to guide organizations in their deployment journey. Success lies not in chasing the latest trends but in building on solid foundations: robust data infrastructure, careful monitoring, and pragmatic architecture choices.
The experiences captured in the LLMOps Database reveal that successful deployments share common characteristics: they start with well-defined use cases, maintain a strong focus on measurable value, and implement robust monitoring and evaluation systems. The field’s rapid evolution demands continuous learning and adaptation, but the fundamental principles of solid engineering, strong data foundations, and careful, iterative development remain constant.
As we continue to navigate this evolving landscape, these practical insights from real-world implementations provide a valuable roadmap for organizations looking to move beyond the hype and create sustainable, production-grade LLM systems. The wild west of LLMOps is gradually being tamed, not through revolutionary breakthroughs, but through the careful, systematic application of engineering principles adapted to the unique challenges of language models.


