

On this page
The hype around large language model (LLM) agents has reached a fever pitch, with companies like Anthropic, OpenAI, and Microsoft touting their potential to revolutionize enterprise automation. Proponents argue that these AI-powered systems can autonomously plan, reason, and interact to complete complex tasks—a tantalizing vision of “autocomplete for everything.”
But is this exuberance warranted? A closer look at real-world case studies from the LLMOps database reveals a more nuanced picture. While LLM agents undoubtedly represent an exciting frontier in AI capabilities, significant challenges remain in reliably deploying them to production. Let’s dive into the key architectures, practical obstacles, and open questions surfaced by organizations at the vanguard of this technology.
All our posts in this series will include NotebookLM podcast ‘summaries’ that capture the main themes of each focus. Today’s blog is about agents in production so this podcast focuses on some of the core case studies and how specific companies developed and deployed agent(ic) application(s).“
To learn more about the database and how it was constructed read this launch blog. Read this post if you’re interested in an overview of the key themes that come out of the database as a whole. To see all the other posts in the series, click here. What follows is a slice around how agents were found in the production applications of the database.
I. Architectures and Frameworks: Deconstructing the Agent ‘Brain’ 🧠
At the core of any LLM agent lies the language model itself—the “brain” that powers its natural language processing and generation capabilities. Models like GPT-4, Claude, and LLaMA allow agents to understand complex prompts, reason about potential actions, and produce human-like responses.
Surrounding this central model is an ecosystem of components that give agents the ability to interact with the world and persist knowledge over time. These typically include:
- Tools: External APIs, databases, and services that agents can call to retrieve information or execute actions. Companies like Dust.tt have built enterprise-grade agent platforms with robust tooling for integrating with CRMs, project management systems, and other business-critical applications.
- Memory: Companies may employ various memory storage solutions, such as vector databases or document stores, to provide context. A system like Unify's, leveraging LangGraph, could potentially use a technology like Redis for efficient memory management.
- Planner: An optional higher-level component that generates multi-step action sequences to guide the agent towards a goal. Frameworks like LangChain provide abstractions for implementing planners, though many agent architectures rely on the LLM's implicit planning capabilities.
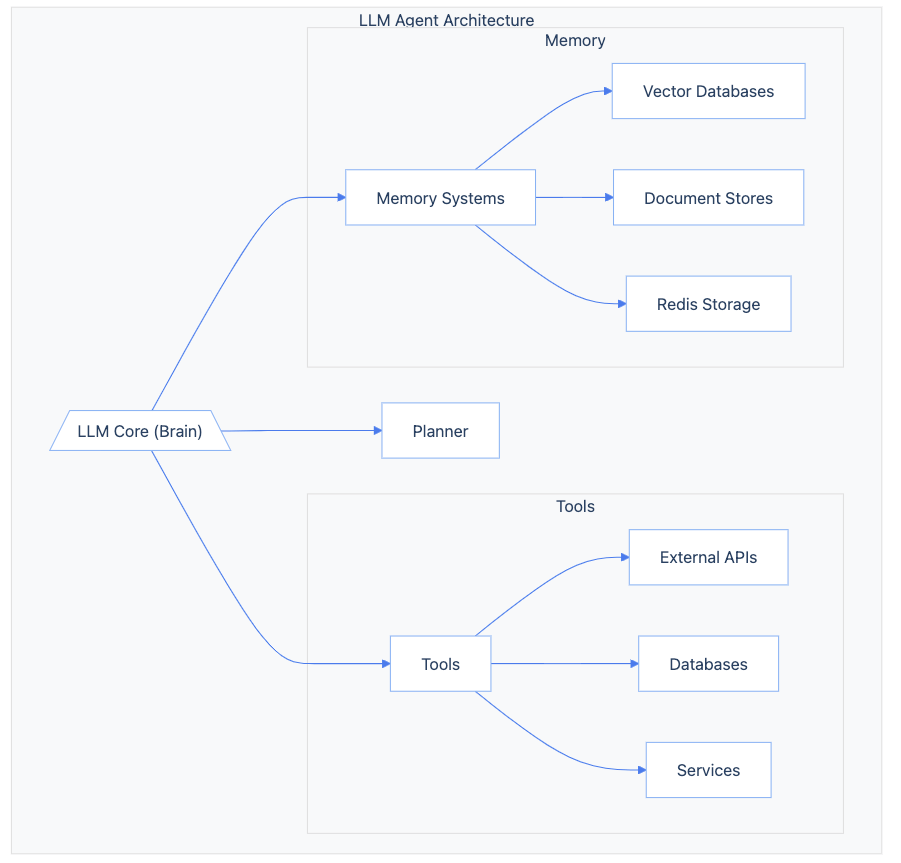
On top of these building blocks, several high-level design patterns have emerged. The ReAct paradigm, pioneered by Anthropic and employed by players like Replit, involves alternating rounds of reasoning and action in a tight feedback loop. In contrast, Dust.tt’s “Plan and Execute” approach has the agent chart an end-to-end course before stepping through each action.
It’s tempting to see these agent architectures as the key to unlocking transformative AI—and indeed, companies like Microsoft, Anthropic, and OpenAI are investing heavily in their development. But assembling the technical components is just the first step. As we’ll see, the path from a working prototype to a production-grade system is fraught with challenges.
II. Tools and Integrations: Extending the Agent’s Reach 🌐
For an LLM agent to meaningfully engage with the world, it needs an interface for tapping into external tools and services. These “pluggable” components allow the agent to retrieve data, execute code, update databases, and perform other concrete tasks. In a sense, they serve as the agent’s arms and legs, bridging the gap between natural language instructions and domain-specific actions.
The design of these tool abstractions is crucial. A well-crafted tool interface provides guardrails to keep the agent on track, while still giving it flexibility to combine primitive actions in novel ways. Building secure and scalable tool integrations is crucial. While not specifically an agent platform, Slack’s approach to securing their LLM infrastructure, with its emphasis on data privacy and access control, provides valuable lessons for building secure agent-tool integrations.
However, as an agent’s toolbox grows, so too does the complexity of managing its interactions. Companies like Anthropic have developed sophisticated authentication and authorization layers to govern which tools an agent can access under different circumstances. Others provide visual interfaces for mapping out tool dependencies and constraints.
Indeed, wrangling the expanding tangle of agent-tool relationships has spawned a cottage industry of startups aimed at simplifying the integration process. Arcade AI pitches an “Agentbox” solution with prebuilt adapters for popular APIs and a point-and-click interface for extending agents to new services. Meanwhile, OpenAI itself now offers a hosted agents platform with “one-click” access to models, memory, and a library of verified tools.
Consider how Dust.tt built their enterprise agent platform. They recognized that relying on generic integrations wouldn’t cut it for serious enterprise use. Instead, they invested heavily in building their own robust connectors for critical systems like Notion, Slack, and GitHub. This allowed them to maintain fine-grained control over data flow, handle different data types effectively, and address the unique nuances of each integration.
The vision of plug-and-play agent augmentation is alluring. But practical challenges remain in scaling these architectures to production. Agent-tool interactions are notoriously difficult to test and debug—a single “hallucinated” API call can derail an entire workflow. Gracefully handling failures, retries, and edge cases across a vast pluggable toolset introduces significant complexity. We’ve yet to see scalable solutions for end-to-end observability and control of agent behavior in the wild.
Effective tool abstraction is more than just wrapping an API. It involves designing an interface that guides the agent toward appropriate usage while preventing misuse. Think of it like designing a user interface, but for an AI. For example, instead of giving an agent direct access to a database, you might create tools for specific queries, like GET_CUSTOMER_INFO(customer_id) or UPDATE_ORDER_STATUS(order_id, status). This constrained approach, as employed by companies like Cleric AI in their SRE agent, minimizes the risk of unintended consequences while still allowing the agent to perform useful tasks.
As agents become more sophisticated, managing the interplay of tools and actions becomes increasingly complex. This is where orchestration frameworks like LangGraph (used by companies like Rexera and Parcha) become crucial. LangGraph allows developers to define workflows visually, specifying which tools an agent can access at each step, managing the flow of information, and handling error recovery. This structured approach is essential for building reliable agent-based systems.
III. Challenges and Best Practices: The Realities of the Real World 😅
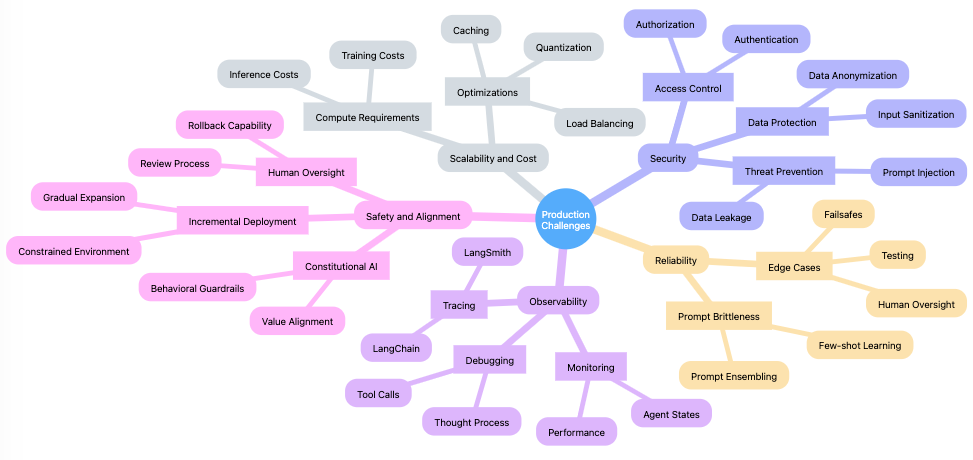
The gap between an LLM agent demo and a battle-tested production system is wide and treacherous. Getting an agent to spit out a reasonable response in a controlled environment is one thing—relying on it to consistently carry out business-critical tasks with real-world data is quite another. The LLMOps case studies lay bare the myriad challenges teams face in operationalizing these systems at scale:
- Reliability: LLM agents are notoriously unpredictable
Small perturbations in input can lead to wildly divergent outputs. Careful prompt engineering and “constitutional” guidelines (a la Anthropic) can help, but unexpected edge cases are all but guaranteed. Parcha’s experiences deploying an enterprise automation platform highlight the importance of extensive testing, human oversight, and failsafes to keep agents on the rails.
LLM agents can be frustratingly fickle. Small changes in wording, even the addition of a seemingly innocuous phrase, can derail an entire interaction. This ‘prompt brittleness,’ as highlighted by Ellipsis in their work on building production LLM agents, requires rigorous testing and careful prompt engineering. Techniques like prompt ensembling (generating multiple prompts for the same query and aggregating the results) and few-shot learning (providing the agent with specific examples of successful interactions) can improve robustness, but eliminating unpredictable behavior entirely remains a challenge.
- Scalability & Cost: Today's state-of-the-art LLMs are ravenously resource-hungry
Meta’s LLaMA reveals the astronomical compute requirements for training and serving these models at scale. Inference costs can quickly balloon as concurrent requests grow. Caching, quantization, and other optimizations become table stakes for any production deployment.
The computational demands of LLMs, especially larger models like GPT-4, can quickly become prohibitive in production. Companies like Bito, faced with API rate limits and escalating costs, had to develop sophisticated load-balancing systems across multiple LLM providers and accounts. Others, like MosaicML in their development of the MPT models, have focused on optimizing model architectures and training processes to reduce the resource footprint. Quantization techniques, which reduce the precision of model weights, are another promising avenue for optimizing inference costs, as demonstrated by Mercari in their dynamic attribute extraction system.
- Security & Access Control: LLM agents' open-ended nature and potential for misuse raise security questions
Robust authentication and authorization controls are a must—as Anthropic and OpenAI have learned the hard way. But even with strict access policies in place, agents can be coaxed into divulging sensitive information or executing dangerous actions if improperly constrained.
Security is paramount in LLM deployments, especially in regulated industries. Prompt injection, where malicious actors manipulate prompts to bypass safety measures or extract sensitive information, is a major concern. Dropbox’s security team uncovered several novel prompt injection vulnerabilities, highlighting the need for robust input sanitization and validation. Secure data management is equally important. QuantumBlack, in their discussion of data engineering challenges for LLMs, emphasizes the need for strict access controls and data anonymization techniques to prevent data leakage, especially in Retrieval Augmented Generation (RAG) systems. Slack’s secure LLM infrastructure, utilizing AWS SageMaker and VPCs, provides a strong example of a privacy-first approach.
- Observability & Debuggability: Understanding why an LLM agent made a particular decision is notoriously difficult
Libraries like LangChain and LangSmith provide tracing capabilities to record agent “thoughts” and intermediate steps, but truly inspectible, auditable operation remains an unsolved challenge. Platforms like Replit now integrate agent monitoring out of the box, but rich, real-time visibility into agent state is still somewhat a dream.
Understanding why an LLM agent made a specific decision is often a frustrating exercise in reverse engineering. Traditional debugging tools are largely ineffective. This ‘black box’ nature of LLM agents requires new approaches to observability. LangSmith, integrated with platforms like Replit and Podium’s AI Employee agent, offers valuable tracing capabilities, allowing developers to inspect the agent’s thought process, track tool calls, and identify potential errors. However, real-time, fine-grained visibility into agent state remains an open challenge.”
- Safety & Alignment: Existential risks?
Perhaps most concerning are the existential risks posed by increasingly capable AI agents pursuing goals misaligned with human values. Anthropic has been at the vanguard of research into “constitutional AI” techniques for baking in behavioral guardrails. But the jury is still out on whether these approaches can scale to reliably constrain superintelligent systems. Microsoft’s emphasis on human-in-the-loop oversight for enterprise agents suggests we have a long way to go before fully autonomous operation.
Throughout the case studies, a common refrain emerges: Start simple, and expand gradually as confidence grows. Microsoft Research recommends beginning with highly constrained agent environments and keeping humans closely involved at every step. Replit’s agents platform defaults to single-step interactions before enabling chained operations. Anthropic bakes extensive testing and roll-back capabilities into their constitutional AI framework.
This ethos of caution and incremental deployment may seem at odds with the breakneck pace of LLM progress. But it reflects a hard-earned recognition that, for all their promise, LLM agents remain highly unpredictable—and potentially dangerous—works-in-progress. Responsible innovation in this space demands a commitment to safety and security at every stage.
IV. Advanced Topics and Future Directions: Beyond the Hype 🔮
Even as teams grapple with the day-to-day challenges of LLM agent deployment, researchers are pushing the boundaries of what’s possible with this technology. The LLMOps database offers a glimpse into some of the most tantalizing developments on the horizon:
- Multi-Agent Ecosystems
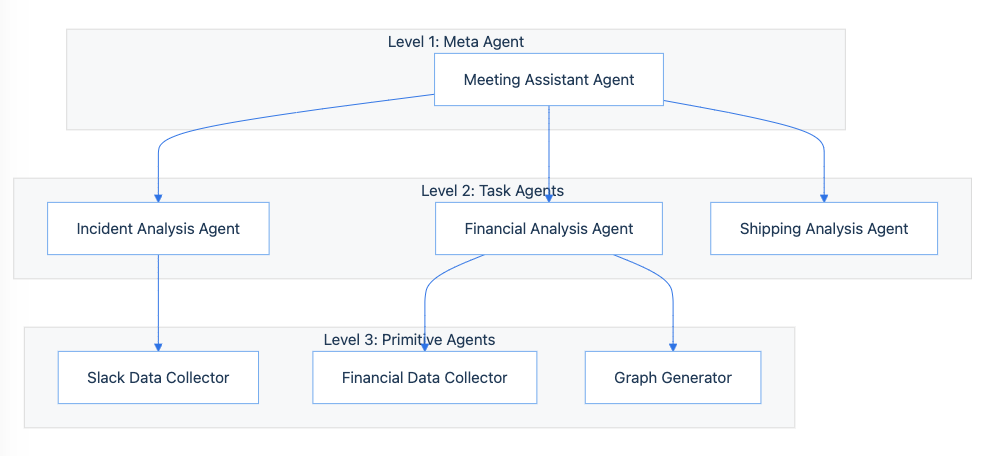
Many of the most compelling applications of LLM agents involve multiple AI entities working in concert to solve complex problems. Rexera’s quality control system, for example, uses a hierarchy of agents, each responsible for a specific aspect of the transaction process. This modular approach, enabled by frameworks like LangGraph, allows for greater control, flexibility, and scalability compared to monolithic agent designs. However, coordinating and managing these multi-agent ecosystems introduce new challenges in communication, resource allocation, and overall system design.
- Embodied Agents
Imagine an LLM agent that can interact with the physical world—a robot that can understand natural language instructions and translate them into actions. Kentauros AI is pushing the boundaries of agent capabilities by tackling the complexities of GUI navigation. Their work explores how LLMs can be used to control software applications, potentially paving the way for more sophisticated interactions with digital environments. This research points to a future where LLMs could control robots, drones, or even smart homes, but significant hurdles remain in bridging the gap between language understanding and physical action, particularly in areas like real-time control, safety, and continuous learning in dynamic environments.
- Multimodal Interfaces
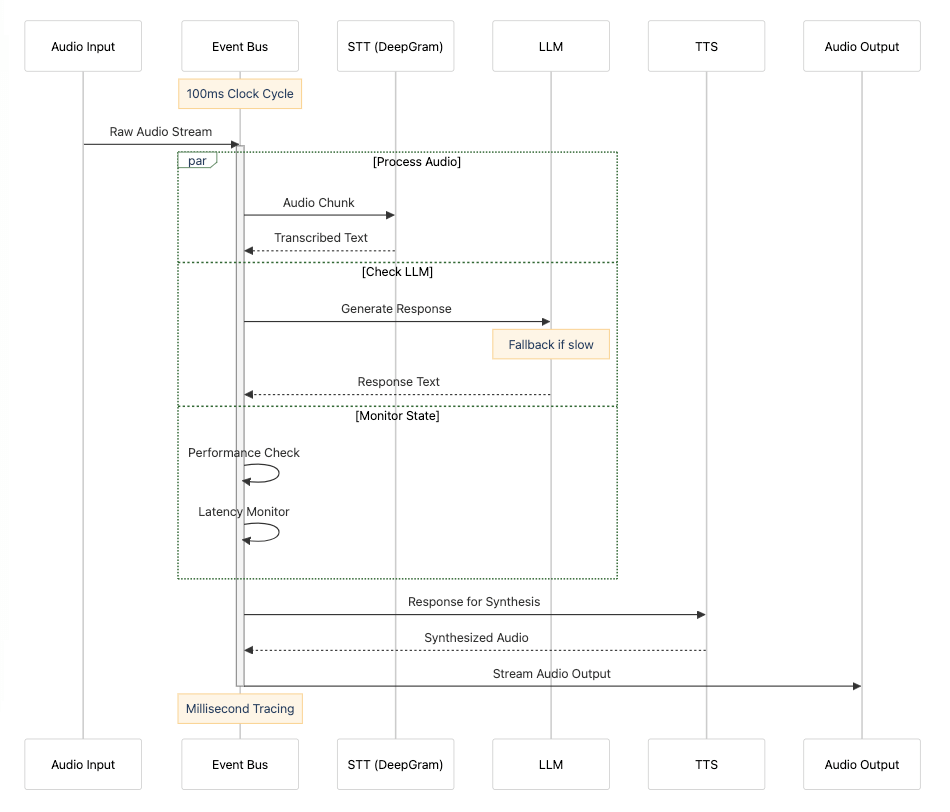
The future of agent interaction is likely to be multimodal, seamlessly blending text, images, video, and audio. RealChar’s phone call assistant provides a compelling example of multimodal AI processing, combining speech-to-text, LLM reasoning, and text-to-speech through a deterministic event-driven architecture. Their approach, inspired by self-driving car systems, demonstrates how complex customer support interactions can be handled without relying on agent architectures. This multi-modal system enables natural communication while maintaining strict control over latency and reliability through parallel processing and robust fallback mechanisms. But the hope is that these deterministic systems and process might extend out to multimodal interfaces going forward.
Conclusion: Grounds for Skepticism 😒
Taken together, the LLMOps case studies paint a picture of a technology that is at once (potentially) immensely powerful and deeply unready for primetime. On one hand, it’s impossible not to be impressed by the raw potential of LLM agents to automate complex cognitive tasks. When they work, they really work—writing code, analyzing data, even engaging in open-ended dialogue with a fluidity that can feel downright spooky.
But for every successful demo, there are many dozen cautionary tales of agents going off the rails in unexpected and often alarming ways. The fundamental unpredictability of these systems—their tendency to “hallucinate” knowledge, to misinterpret prompts, to blithely accede to dangerous requests—makes them a harrowing proposition for anything approaching mission-critical deployment.
To be sure, there are glimmers of hope amidst the hype. Anthropic’s work on constitutional AI, Parcha’s sophisticated reliablity engineering, Microsoft’s insistence on human safeguards—all point to a growing recognition of the need for responsible development practices in this space. But the road from research to robust product is long and winding. Anyone who claims to have cracked the code on safe, scalable LLM agents is almost certainly selling snake oil.
In the end, healthy skepticism remains the watchword of the day. The potential of this technology is immense—but so are the perils. For every wide-eyed evangelist touting LLM agents as the key to unlocking AGI, there’s a sober skeptic urging caution and constraint. The reality, as always, lies somewhere in between.
LLM agents are indeed transformative tools. But they are tools nonetheless—wondrous yet fallible creations whose edges remain very much rough. Deployed judiciously, with clear boundaries and close human supervision, they may yet yield extraordinary benefits. But we must resist the temptation to anthropomorphize them into oracles, or to abdicate our agency as toolmakers and tool-wielders.


