On this page
The field of machine learning and artificial intelligence has rapidly grown. However, transitioning a machine learning model from development to real-world deployment presents challenges. MLOps, combining ML and DevOps practices, automates ML models’ deployment, monitoring, and maintenance. By integrating data science with operational workflows, MLOps ensures efficient deployment and scalable maintenance, delivering significant value to organizations.
In this blog, we will explore the core concepts of MLOps and its increasing importance for modern AI-driven enterprises. The guide will cover technical and organizational strategies, including team setups, for a comprehensive approach.:
- The Fundamentals of MLOps: What it is and its key components.
- The Importance of MLOps: Why MLOps matters in today’s data-driven world.
- Implementation Strategies: Practical steps to implement MLOps in your workflows.
- Best Practices: Tips and best practices to ensure a successful MLOps implementation.
- Tools and Technologies: An overview of the popular tools and platforms used in MLOps.
By the end of this blog, you’ll have a solid understanding of MLOps and how it can future-proof your machine-learning projects, enabling you to deploy and manage models confidently and efficiently.
What is MLOps?
MLOps, or Machine Learning Operations, is an extension of DevOps specifically designed for machine learning and data science. It integrates these processes into the development and operations chain to enhance ML development’s reliability, efficiency, and productivity. MLOps encompasses practices, tools, and cultural philosophies that aim to automate and streamline the end-to-end machine learning lifecycle.
What is the goal of MLOps?
The primary goal of MLOps is to automate and optimize the development, training, and deployment of ML models. It aims to:
- Enhance collaboration: Bring together data scientists, ML engineers, developers, security, and infrastructure teams to work more effectively.
- Automate workflows: Streamline processes from data ingestion and model training to deployment and monitoring.
- Ensure reproducibility: Maintain consistent and reproducible ML experiments and results.
- Improve scalability: Enable the scaling of ML models and infrastructure to handle growing data and computational needs.
- Ensure governance: Implement robust monitoring, validation, and governance practices to comply with regulatory requirements and maintain model integrity.
What does MLOps give you?
MLOps proves invaluable in developing and enhancing machine learning and AI solutions. It offers several benefits, including:
- Productive collaboration: MLOps fosters productive collaboration between data scientists and ML engineers, ensuring smooth transitions from model development to deployment.
- Accelerated development: By adopting continuous integration and continuous deployment (CI/CD) practices, MLOps accelerate the development and deployment of ML models, reducing time to market.
- Enhanced model management: MLOps ensures that ML models are appropriately monitored, validated, and governed throughout their lifecycle.
- Scalability and efficiency: MLOps enables organizations to scale their ML operations efficiently, leveraging automated workflows and infrastructure management.
- Improved reliability: MLOps enhances the reliability and robustness of ML models in production environments through automated testing, monitoring, and validation.
By implementing MLOps, organizations can unlock the full potential of their machine learning initiatives, driving innovation and achieving better business outcomes.
Why MLOps?
MLOps is crucial for optimizing and automating machine learning processes in production. It involves deploying, monitoring, and governing ML operations to maximize benefits and mitigate risks. Automated model retraining and timely detection of model drift are becoming standard practices. Maintaining MLOps platforms and updating models as needed is essential for optimal performance. This transformation breaks down data silos and promotes teamwork, allowing data scientists to focus on model creation and deployment while MLOps engineers manage operational models.
Why Do We Need MLOps?
MLOps merges data science and IT operations, enabling seamless integration of machine learning models into business workflows. By automating model training, deployment, and monitoring, MLOps ensures efficient and reliable incorporation of ML models into production, driving competitive advantage.

Statistics
Investment in MLOps has grown significantly in recent years. According to a report by Forrester, the MLOps market is expected to grow at a compound annual growth rate (CAGR) of 39.7% from 2021 to 2026. Additionally, a survey by Algorithmia found that 83% of companies increased their AI/ML budgets in 2023, with a substantial portion of that investment directed towards MLOps tools and practices.
Real-World Examples of MLOps in Action
- Netflix uses MLOps to automate the deployment and monitoring of its recommendation algorithms. This ensures that their models are always up-to-date with the latest viewing data, providing accurate and personalized recommendations to users.
- Uber leverages MLOps to manage the lifecycle of models used in dynamic pricing and route optimization. By automating model deployment and monitoring, Uber can quickly adapt to changing conditions and provide reliable customer service.
- Spotify employs MLOps to update and deploy its music recommendation models continuously**.** This allows Spotify to deliver personalized playlists and improve user engagement based on real-time listening behavior.
The steps in the MLOps lifecycle
Most sufficiently complex models will go through the following nine stages in their MLOps lifecycle:
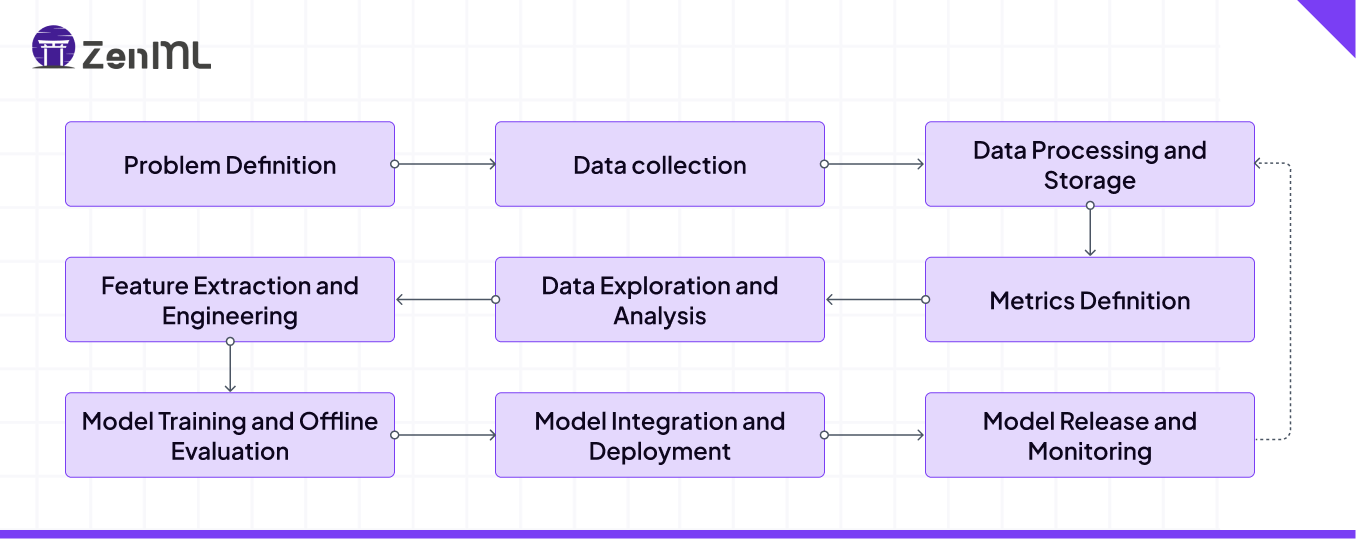
Problem definition:* All model development starts with identifying a concrete problem to *solve with AI.
Data collection: Data that will be used for model training is collected. This data might come from within the product (e.g., data on user behavior) or from an external data set.
Data processing or storage: Machine learning relies on large amounts of data, typically stored in a data warehouse or lake. The data is processed in batches or as a stream based on the company’s requirements and available tools to consolidate and clean it.
Metrics definition: It’s essential to agree on the metrics the team will use to measure the model’s quality and success in solving the problem identified at the beginning of the process.
Data exploration: Data scientists will analyze the data to develop hypotheses about the most beneficial modeling techniques.
Feature extraction and engineering: Features are the characteristics of your data used as inputs to the model. Data scientists decide which features to create, while engineers ensure they can be regularly updated with new data.
Model training and offline evaluation: Models are created, trained, and assessed to pick the best approach. Most of the data is used for training, with a smaller portion (usually around 20–30%) reserved for evaluation.
Model integration and deployment: ****After validating and preparing the models, they need to be integrated into the product, potentially requiring the creation of new services and hooks for fetching model predictions. Following this, the models are usually deployed within a cloud system like AWS or GCP.
Model release and monitoring: Once deployed, models need to be closely monitored to ensure there are no issues in production. Model monitoring also helps identify how the model can be improved with retraining on new data.
How Does MLOps Differ from DevOps?
Think of DevOps as the manager of a software development factory. They oversee the entire production process, from design and development to testing and deployment, ensuring the factory runs smoothly and efficiently and consistently delivers high-quality software products.
MLOps is a specialized department in this software factory focused on producing machine learning models. MLOps engineers manage the entire lifecycle of these models, from data preparation and model training to deployment and monitoring. They collaborate closely with data scientists and developers to ensure models are built, tested, and deployed in a reliable, scalable, and maintainable manner.
While DevOps ensures the overall software development process is streamlined and efficient, MLOps specifically addresses the unique challenges and requirements of developing and deploying machine learning models. Just as a factory has different departments for producing various products, MLOps is a specialized unit within the larger DevOps ecosystem, ensuring machine learning models are built and deployed with the same rigor and reliability as other software components.
MLOps tools are designed to address the unique challenges of managing machine learning models. They include model versioning, data versioning, model registry, and model serving.
MLOps tools also provide specialized support for popular machine learning frameworks and libraries, such as TensorFlow, PyTorch, and scikit-learn. This can simplify the deployment of models in production for data scientists, as they won’t have to worry about the underlying infrastructure and deployment mechanisms. Additionally, these tools can streamline the entire process within a single platform, eliminating the need for multiple tools and systems for different parts of the workflow.
Therefore, although DevOps and MLOps share conceptual similarities, such as automation and collaboration, they differ in their scope and the tools and techniques they use.
MLOps best practices
Let’s dive into MLOp’s best practices that can help your data science team improve its operational processes.
Establishing a Clear Project Structure
A well-organized project structure simplifies navigating, maintaining, and scaling future projects. Key tips include:
- Organize Code and Data: Structure based on environment and function, maintain a consistent naming convention.
- Version Control: Use tools like Git (for code) or DVC (for data) to track changes.
- Consistent Documentation: Keep documentation style uniform.
- Communication: Ensure clear communication about changes within the team.
Know Your Tools Stack
Selecting the right tools is crucial for an effective MLOps pipeline. When choosing tools, consider your project and company requirements, and limit the number to avoid complexity. Use tools that align with your compliance needs and operational requirements.
Track Your Expenses
While minimizing technical debt is essential, keeping an eye on monetary expenses is equally important. Subscription-based MLOps tools can add up. Use cloud services with expense tracking features to monitor costs and avoid overspending.
Having a Standard for Everything
Standardization minimizes technical debt and ensures smooth operations. Establish standards for:
- Naming Conventions: Consistent naming for tools, variables, scripts, and data.
- Processes: Standardize data analysis, environment setup, pipeline structure, and deployment processes.
Assess Your MLOps Maturity Periodically
Regularly evaluate your MLOps readiness to ensure you’re getting the full benefits. Use models like Microsoft Azure’s MLOps maturity pyramid to assess and improve your MLOps practices over time.
By establishing a clear project structure, choosing the right tools, tracking expenses, standardizing processes, and periodically assessing maturity, you can ensure a robust and effective MLOps pipeline. These best practices will help your team streamline workflows, reduce technical debt, and achieve better outcomes from your machine learning projects.
How to implement MLOps
MLOps maturity models are frameworks that assist organizations in evaluating their current MLOps practices and developing a plan to enhance them over time. These models generally describe various levels or stages of maturity, each distinguished by specific capabilities, processes, and outcomes. (We find companies are often interested in this so have previously written about MLOps maturity models on the ZenML blog).
Google suggests three approaches for implementing MLOps:
- MLOps Level 0: Manual processes.
- MLOps Level 1: Automation of the ML pipeline.
- MLOps Level 2: Automation of the CI/CD pipeline.

MLOps level 0
This is typical for companies that are just starting with ML. If your models are rarely changed or trained, an entirely manual ML workflow and the data scientist-driven process might be enough.
Characteristics
- Manual, script-driven, and interactive process: every step is manual, including data analysis, data preparation, model training, and validation. It requires manual execution of each step and manual transition from one step to another.
- Disconnect between ML and operations: The process separates data scientists who create the model from engineers who serve the model as a prediction service. The data scientists hand over a trained model as an artifact for the engineering team to deploy on their API infrastructure.
- Infrequent release iterations: the assumption is that your data science team manages a few models that don’t change frequently—either changing model implementation or retraining the model with new data. A new model version is deployed only a couple of times per year.
- No Continuous Integration (CI): You ignore CI because few implementation changes are assumed. Usually, testing the code is part of the notebooks or script execution.
- No Continuous Deployment (CD): A CD isn't considered because there aren’t frequent model version deployments.
- Deployment refers to the prediction service (i.e., a microservice with REST API)
- Lack of active performance monitoring: the process doesn’t track or log model predictions and actions.
The engineering team may have a complex API configuration, testing, and deployment setup, including security, regression, and load + canary testing.
Challenges
In practice, models often break when deployed in the real world. Models fail to adapt to changes in the dynamics of the environment or changes in the data that describes the environment. Forbes has a great article on Why Machine Learning Models Crash and Burn in Production.
To address the challenges of this manual process, it’s good to use MLOps practices for CI/CD and CT. Deploying an ML training pipeline can enable CT, and you can set up a CI/CD system to rapidly test, build, and deploy new implementations of the ML pipeline.
MLOps level 1
The objective of MLOps level 1 is to enable continuous training (CT) of the model through the automation of the ML pipeline. This ensures the constant delivery of model prediction services. This approach benefits solutions operating in dynamic environments that require proactive adaptation to changes in customer behavior, pricing, and other relevant indicators.
Characteristics
- Rapid experiment: ML experiment steps are orchestrated and done automatically.
CT of the model in production: the model is automatically trained in production, using fresh data based on live pipeline triggers.
- Experimental-operational symmetry: The pipeline implementation used in the development or experiment environment is also used in the preproduction and production environments, an essential aspect of MLOps practice for unifying DevOps.
- Modularized code for components and pipelines: To construct ML pipelines, components must be reusable, composable, and potentially shareable across pipelines (i.e., using containers).
- Continuous delivery of models: the model deployment step, which serves the trained and validated model as a service for online predictions, is automated.
- Pipeline deployment: in level 0, you deploy a trained model as a prediction service to production. For level 1, you deploy a whole training pipeline, which automatically and recurrently runs to serve the trained model as the prediction service.
Additional components
Data and model validation: the pipeline expects new, live data to produce a new model version trained on the latest data. Therefore, automated data validation and model validation steps are required in the production pipeline.
Feature store: a feature store is a centralized repository where you standardize the definition, storage, and access of features for training and serving.
Metadata management: information about each execution of the ML pipeline is recorded to help with data and artifact lineage, reproducibility, and comparisons. It also enables you to debug errors and anomalies
ML pipeline triggers: you can automate ML production pipelines to retrain models with new data, depending on your use case:
- On-demand
- On a schedule
- On the availability of new training data
- On-model performance degradation
- On significant changes in the data distribution (evolving data profiles).
Challenges
This setup is suitable when you deploy new models based on new data rather than new ML ideas. However, you need to try new ML ideas and rapidly deploy new implementations of the ML components. If you manage many ML pipelines in production, you need a CI/CD setup to automate the build, test, and deployment of ML pipelines.
MLOps Level 2
Implementing a robust automated CI/CD system enables data scientists to efficiently experiment with new ideas for feature engineering, model architecture, and hyperparameters.
This level of MLOps adoption is ideal for technology-driven companies that require frequent model retraining, rapid updates, and simultaneous deployment across numerous servers. Survival with a comprehensive end-to-end MLOps framework would be easier for such organizations.
This MLOps setup comprises the following key components:
- Source control
- Testing and building services
- Deployment services
- Model registry
- Feature store
- ML metadata repository
- ML pipeline orchestrator
Characteristics
Development and Experimentation: Iterative process of testing new ML algorithms and models. Output: Source code for ML pipeline steps, uploaded to a source repository.
Pipeline Continuous Integration: Building and testing source code. Output: Pipeline components (packages, executables, artifacts) for deployment.
Pipeline Continuous Delivery: Deploying CI artifacts to the environment. Output: A deployed pipeline with the new model.
Automated Triggering: Automatic pipeline execution based on schedules or triggers. Output: A newly trained model is pushed to the model registry.
Model Continuous Delivery: Serving the trained model as a prediction service. Output: A deployed model prediction service.
Monitoring: Gathering real-time performance statistics for the model. Output: Triggers for pipeline execution or new experimentation cycles.
Data scientists manually perform data analysis and model evaluation before initiating new experimental iterations.
Challenges
MLOps Level 2 offers agility but brings challenges such as resource strain due to frequent retraining, coordination between development and production, and managing feature stores and metadata. It’s important to maintain the demanding pace while ensuring data integrity.
Addressing continuous experimentation and development challenges involves automating data analysis and model assessment for optimal use of MLOps Level 1. Ensuring dependable automated triggering and monitoring mechanisms is crucial for model stability. Most companies will primarily operate within Levels 0-1, so balancing innovation and resource management is vital for tech companies aiming to excel in dynamic environments.
Starting a local experiment with ML
This portion will guide you in setting up a quick machine-learning model on your local machine. We’ll start by installing Python and creating a virtual environment to avoid interference with other versions. This allows for easy testing of small models before scaling for production using the pre-trained model RoBERTa from Hugging Face.
Install Python
Download and install the correct Python version if you don’t have it.
- Ensure it's between versions 3.8 and 3.11 for compatibility.
Ensure you have Python installed.
python --versionSet up a Virtual Environment
- Creating a virtual environment for your project is good practice to avoid conflicts with other Python software packages.
Creating a Virtual Environment:
python -m venv myenv- To learn more about how to activate Python virtual environments.
Install necessary libraries:
pip install transformers torch scipy flask requestsCreate a model.py file:
This file will specify which model to use and how to use it. It will also specify different variables and the output format.
# model.py
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from scipy.special import softmax
# Load pre-trained model and tokenizer
roberta = "cardiffnlp/twitter-roberta-base-sentiment"
model = AutoModelForSequenceClassification.from_pretrained(roberta)
tokenizer = AutoTokenizer.from_pretrained(roberta)
labels = ['Negative', 'Neutral', 'Positive']
# Preprocess the tweet text
def preprocess_sentiment(tweet):
tweet_words = []
for word in tweet.split(' '):
if word.startswith('@') and len(word) > 1:
word = '@user'
elif word.startswith('http'):
word = "http"
tweet_words.append(word)
return " ".join(tweet_words)
# Function to predict sentiment score
def sentiment_score(tweet):
tweet_proc = preprocess_sentiment(tweet)
encoded_tweet = tokenizer(tweet_proc, return_tensors='pt')
output = model(**encoded_tweet)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
return {labels[i]: float(scores[i]) for i in range(len(scores))}Create an app.py file:
# app.py
from flask import Flask, request, jsonify, render_template
from model import sentiment_score
app = Flask(__name__)
@app.route('/')
def home():
return render_template('index.html')
@app.route('/predict', methods=['POST'])
def predict():
tweet = request.form['tweet']
scores = sentiment_score(tweet)
return render_template('index.html', tweet=tweet, scores=scores)
if __name__ == '__main__':
app.run(debug=True)This file will have the routing of the model locally and how it is rendered.
Create an index.html file in a templates folder:
<!-- templates/index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
</head>
<body>
<h1>Sentiment Analysis</h1>
<form action="/predict" method="post">
<label for="tweet">Enter a tweet or review:</label><br>
<textarea id="tweet" name="tweet" rows="4" cols="50"></textarea><br><br>
<input type="submit" value="Analyze">
</form>
{% if scores %}
<h2>Sentiment Scores</h2>
<p><strong>Tweet:</strong> {{ tweet }}</p>
<ul>
{% for label, score in scores.items() %}
<li><strong>{{ label }}:</strong> {{ score }}</li>
{% endfor %}
</ul>
{% endif %}
</body>
</html>This contains how the data will be shown locally in the browser.
Run the app:
python app.pyOutput on localhost:
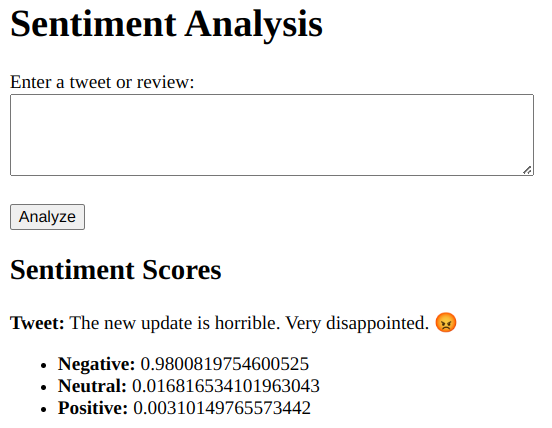
We can input the reviews into the textbox for analysis. The output will be categorized as positive, negative, or neutral, with values closer to 1 indicating higher effectiveness.
Run your First ML Pipelines with ZenML
In this section, you’ll quickly set up and use ZenML to run machine learning pipelines locally. We’ll cover installing Python to launching your first pipeline, allowing you to optimize machine learning operations. We’ll also show a simple case of inference using the previous model from within a ZenML pipeline (think batch processing use cases!) showing how you can improve development speed and refine models for larger-scale deployments. Let’s get started by setting up your local ML pipeline using ZenML:
Connect to ZenML
pip install zenmlStart the ZenML server locally
zenml up- If you use a Windows device, you must run
zenml up --blockingto start the server in blocking mode, which ensures robust retry mechanisms. - To connect to your ZenML local server, use
defaultas a username and an empty password.
Initialize ZenML in the current directory
zenml initInstall requirements for this project
pip install transformers torchCreate a roberta_pipeline.py file in which we will define our pipeline:
import torch
from transformers import RobertaTokenizer, RobertaForSequenceClassification
from zenml import pipeline, step, Model
# Define the ZenML Model
zenml_model = Model(
name="roberta_sentiment_model",
version=None,
license="Apache 2.0",
description="A sentiment analysis model using RoBERTa from Hugging Face transformers.",
)
# Define a ZenML step that uses the RoBERTa model for sentiment analysis
@step(model=zenml_model)
def sentiment_analysis_step(text: str) -> str:
# Load the Hugging Face RoBERTa model and tokenizer
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaForSequenceClassification.from_pretrained('roberta-base')
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=-1)
labels = {0: 'negative', 1: 'positive'} # Assuming binary classification for simplicity
return labels[predictions.item()]
# Define the ZenML pipeline
@pipeline(model=zenml_model)
def sentiment_analysis_pipeline(text: str):
sentiment_analysis_step(text=text)
if __name__ == "__main__":
text_to_analyze = "ZenML is an amazing tool for MLOps!"
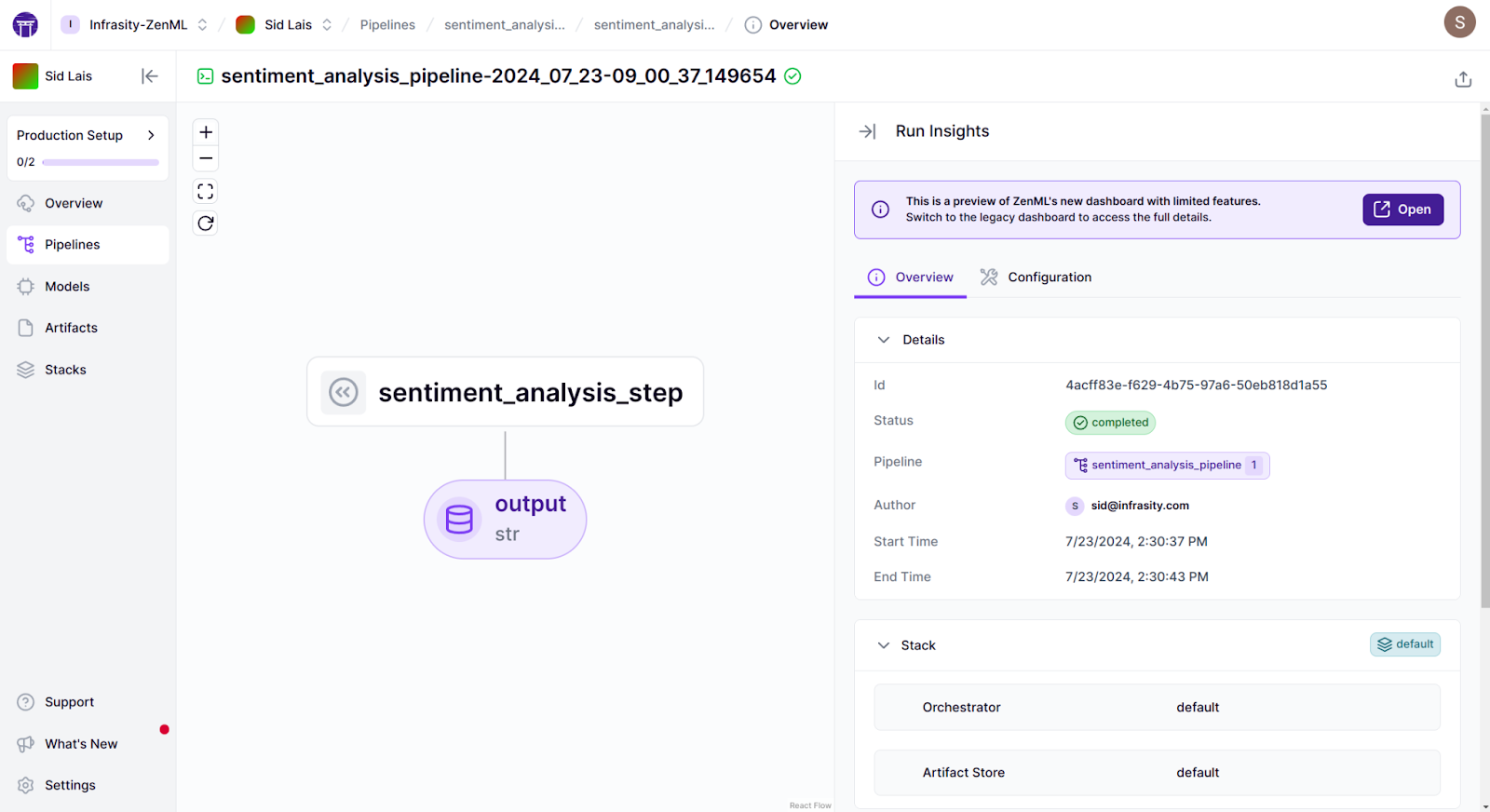
sentiment_analysis_pipeline(text=text_to_analyze)Run the pipeline we made:
python roberta_pipeline.pyOnce it runs, your dashboard will show all the details of the associated run, models, and artifacts.
Tools and Platforms for MLOps
Implementing MLOps effectively requires a combination of tools and platforms that support various stages of the machine learning lifecycle. Here’s an overview of some of the most popular MLOps tools and platforms:

Data Versioning and Management
- DVC (Data Version Control): An open-source tool that extends Git capabilities to handle large files like datasets and models, offering data dependency management and tracking.
- LakeFS: Provides a Git-like version control interface for object storage, enabling scalable data management.
Model Training Frameworks
- TensorFlow: An open-source ML framework by Google for constructing and training models, supporting deep learning and distributed computing.
- PyTorch: An open-source deep learning framework with dynamic computational graphs and a user-friendly Pythonic interface, popular for research and model development.
- JAX: A numerical computing library that offers high-performance machine learning research with automatic differentiation and accelerated linear algebra.
Deployment and Orchestration Platforms
- Kubeflow: Simplifies machine learning model deployment on Kubernetes, making it portable and scalable.
- BentoML: Provides a unified platform for packaging, shipping, and deploying machine learning models at scale.
- Hugging Face Inference Endpoints: A cloud-based service for deploying machine learning models for inference with minimal setup.
Monitoring and Logging Solutions
- Evidently: An open-source Python library for monitoring ML models during development, validation, and production.
- Great Expectations: An open-source data validation, testing, and documentation framework for ensuring data quality and integrity in ML pipelines.
Automated Testing and CI/CD Pipelines
- TruEra: Focuses on model testing, explainability, and root cause analysis to drive model quality and performance.
- Deepchecks: An open-source solution that caters to all ML validation needs, ensuring data and models are thoroughly tested from research to production.
- CML (Continuous Machine Learning): An open-source tool for CI/CD in machine learning, enabling automation and tracking of model training, evaluation, and deployment using GitHub Actions and GitLab CI.
Experiment Tracking and Metadata Management
- Weights & Biases: A platform for experiment tracking, model optimization, and dataset versioning.
- Neptune.ai: A lightweight experiment-tracking tool that helps teams keep track of their machine-learning experiments.
- Comet: An MLOps platform for tracking, monitoring, and managing machine learning models, experiments, and data.
Feature Stores
- Feast: An open-source feature store that helps machine learning teams manage and serve features for training and production.
- Featureform: A virtual feature store enabling data scientists to define, manage, and serve their ML model's features.
End-to-End MLOps Platforms
- AWS SageMaker: A comprehensive platform for developing, training, and deploying machine learning models.
- DagsHub: A platform that integrates data versioning, experiment tracking, and ML pipeline management, similar to GitHub but for machine learning.
- Iguazio: An end-to-end MLOps platform that automates the entire ML pipeline from data collection to deployment and monitoring.
These tools enable streamlined data management, model training, deployment, monitoring, and CI/CD pipelines, which are crucial for the MLOps lifecycle.
How to Select the Right MLOps Tools
Now that you’ve seen various MLOps tools that streamline work from data collection to model deployment, it’s time to understand how to choose the best tools for your ML pipelines. Here are some tips for selecting the right MLOps tool for you.
Scalability and Performance
- Using open-source tools to train and deploy a model is possible. However, achieving scalability can be complex, depending on multiple working tools. Scalability and performance can be evaluated based on handling large datasets, supporting distributed computing, and performance optimization features.
Integration Capabilities
- When choosing an MLOps tool, assess its integration with your existing tech stack to minimize efforts and ensure compatibility.
Ease of Use and Learning Curve
- Organizations prefer easy-to-learn tools over complex ones to avoid lengthy training and costs. When choosing MLOps tools, prioritize intuitive interfaces, comprehensive documentation, and active developer communities to minimize training time.
Support and Documentation
- When learning a new technology, choose tools with strong documentation and community support for easier learning and issue-solving. Look for active developer communities, reliable technical support, and comprehensive documentation.
MLOps platforms overview
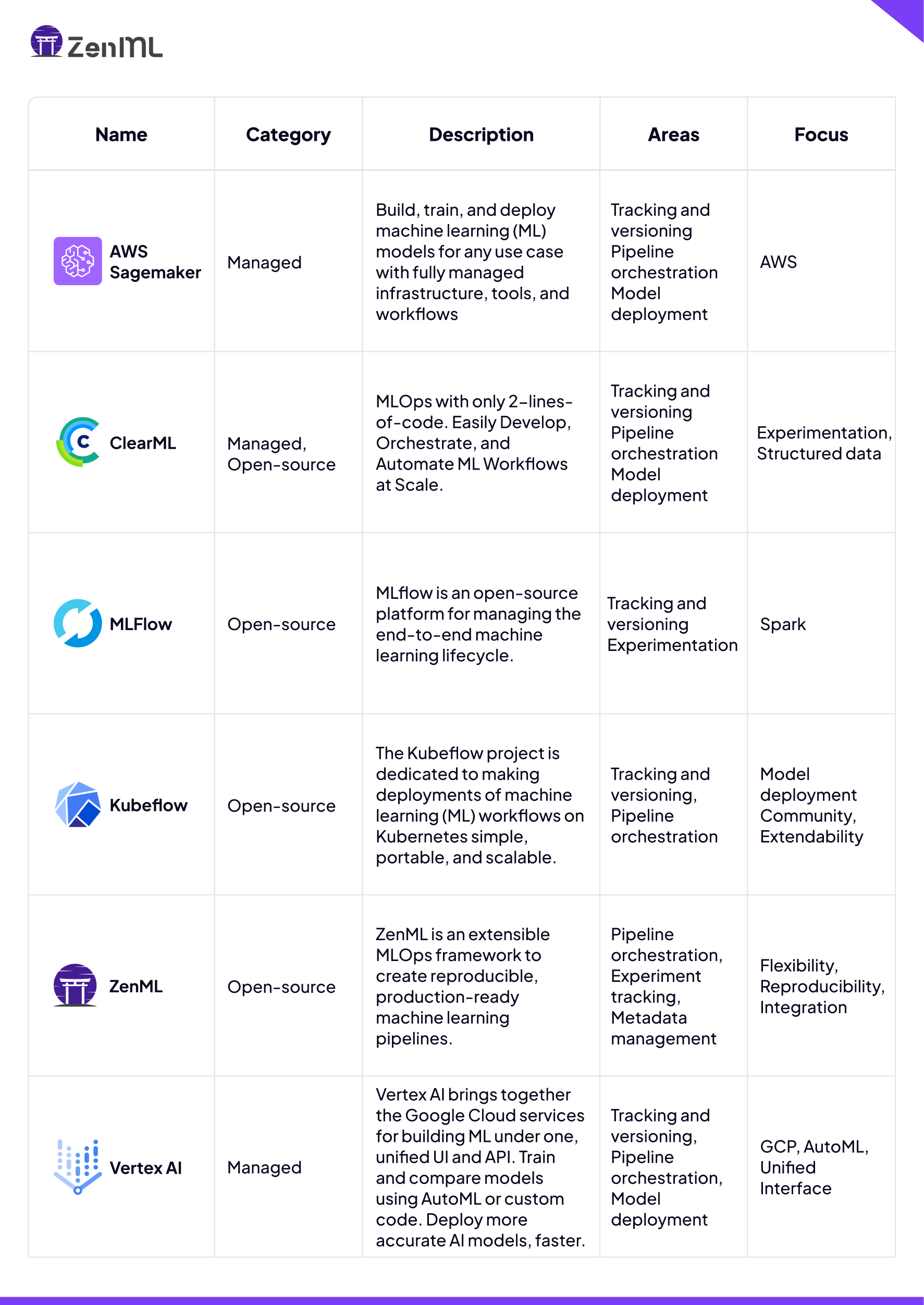
The Future of MLOps
The market for MLOps solutions is expected to reach $4 billion by 2025. Even though it’s still in relatively early days, the strategy and best practices around adopt MLOps for smaller companies will take shape over the next few years. A well-structured MLOps practice makes it easier to align ML models with business needs, people, and regulatory requirements. When deploying ML solutions, you will uncover new sources of revenue, save time, and reduce operational costs. The workflow efficiency within your MLOps function will allow you to leverage data analytics for decision-making and build better customer experiences.
Depending on your organization’s stage in its Machine Learning journey, developing a successful MLOps practice will require an initial investment in people, technology, and operations. Here are our tips for building a strong MLOps practice:
- Bring together Data Science, Data Engineering, DevOps, and business teams to create a framework and architecture that uniquely supports the success of machine learning within the organization.
- With a well-established framework, streamline model development and deployment using MLOps to achieve faster time to market and reduced operational expenses.
- Build metrics to measure the success of Machine Learning deployments built on MLOps infrastructure. Consider the productivity of model development, the number of models that reach production, and the tools in place to analyze the results of analysis and redeployment.
- Leverage open-source tools and products on the public cloud to create the appropriate MLOps workflow for your machine learning requirements.
Ultimately, a strong MLOps strategy will help you use machine learning in your organization, enhance your products, and allow you to better serve your customers.
In the rapidly evolving field of artificial intelligence and machine learning, transitioning from developing machine learning models to deploying them in real-world scenarios is challenging. MLOps, which stands for Machine Learning Operations, provides a structured approach to addressing these challenges by combining the principles of Machine Learning and DevOps. By integrating these principles, MLOps simplifies ML models’ deployment, monitoring, and maintenance, ensuring they can be effectively managed and scaled in production environments.
Implementing MLOps practices can significantly improve the efficiency, scalability, and reliability of machine learning projects. By automating tasks and promoting collaboration between data science and operations teams, MLOps bridges the gap between model development and operational workflows. This enhances model performance and compliance and speeds up the time to market for AI solutions.
The growing investment in MLOps tools and success stories from industry leaders such as Netflix, Uber, and Spotify highlight the crucial role of MLOps in driving business value. Organizations can overcome common deployment obstacles by adopting best practices, selecting the right tools, maintaining robust models, and ensuring continual improvement.
To sum up, MLOps is vital for any organization leveraging machine learning effectively. By establishing a comprehensive MLOps framework, businesses can achieve more significant innovation, efficiency, and a competitive edge in the AI-driven world.