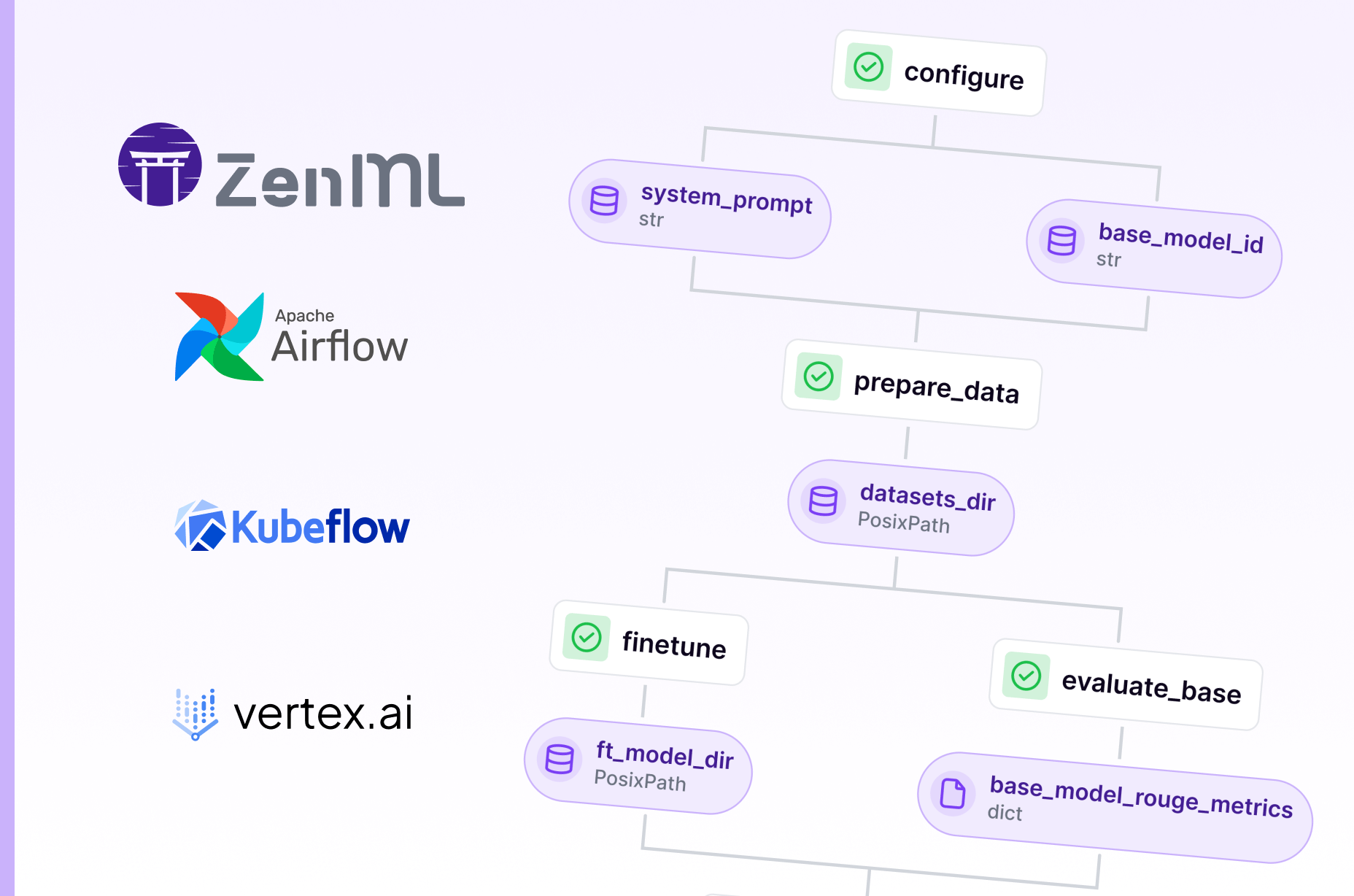
How to Build a Multi-Agent Financial Analysis Pipeline with ZenML and SmolAgents
How to build a production-ready financial report analysis pipeline using multiple specialized AI agents with ZenML for orchestration, SmolAgents for lightweight agent implementation, and LangFuse for observability and debugging.

Sep 19, 202515 mins