

On this page
The meteoric rise of Large Language Models (LLMs) has captivated the AI world, enabling breakthroughs across industries. However, as these models grow in size and complexity, the challenge of deploying and managing them efficiently in production environments has come to the forefront. The tension between harnessing the power of LLMs and operating within resource constraints is a critical concern for technical professionals responsible for these deployments.
In a recent round table discussion on “Large Language Models in Production,” experts from various companies highlighted the delicate balancing act between model performance and operational costs. As Rebecca, a research engineer at Facebook AI Research, noted, “The current state of latency in production workflows can often reach several seconds, with multi-model chains extending to 15+ seconds.” This underscores the need for strategic optimization across the LLM lifecycle.
Drawing from the wealth of insights in the LLMOps database, we’ll explore three key areas where companies are innovating to maximize the value of their LLM deployments: Model Selection and Optimization, Inference Optimization Techniques, and Cost Optimization Strategies. By examining real-world examples and best practices, we aim to equip you with practical strategies to fine-tune your LLM infrastructure.
All our posts in this series will include NotebookLM podcast ‘summaries’ that capture the main themes of each focus. Today’s blog is about cost and performance optimization in production so this podcast focuses on some of the core case studies and how specific companies developed and deployed application(s) where this was a core focus.“
To learn more about the database and how it was constructed read this launch blog. Read this post if you’re interested in an overview of the key themes that come out of the database as a whole. To see all the other posts in the series, click here. What follows is a slice around how cost and performance optimization was found in the production applications of the database.
Model Selection and Optimization
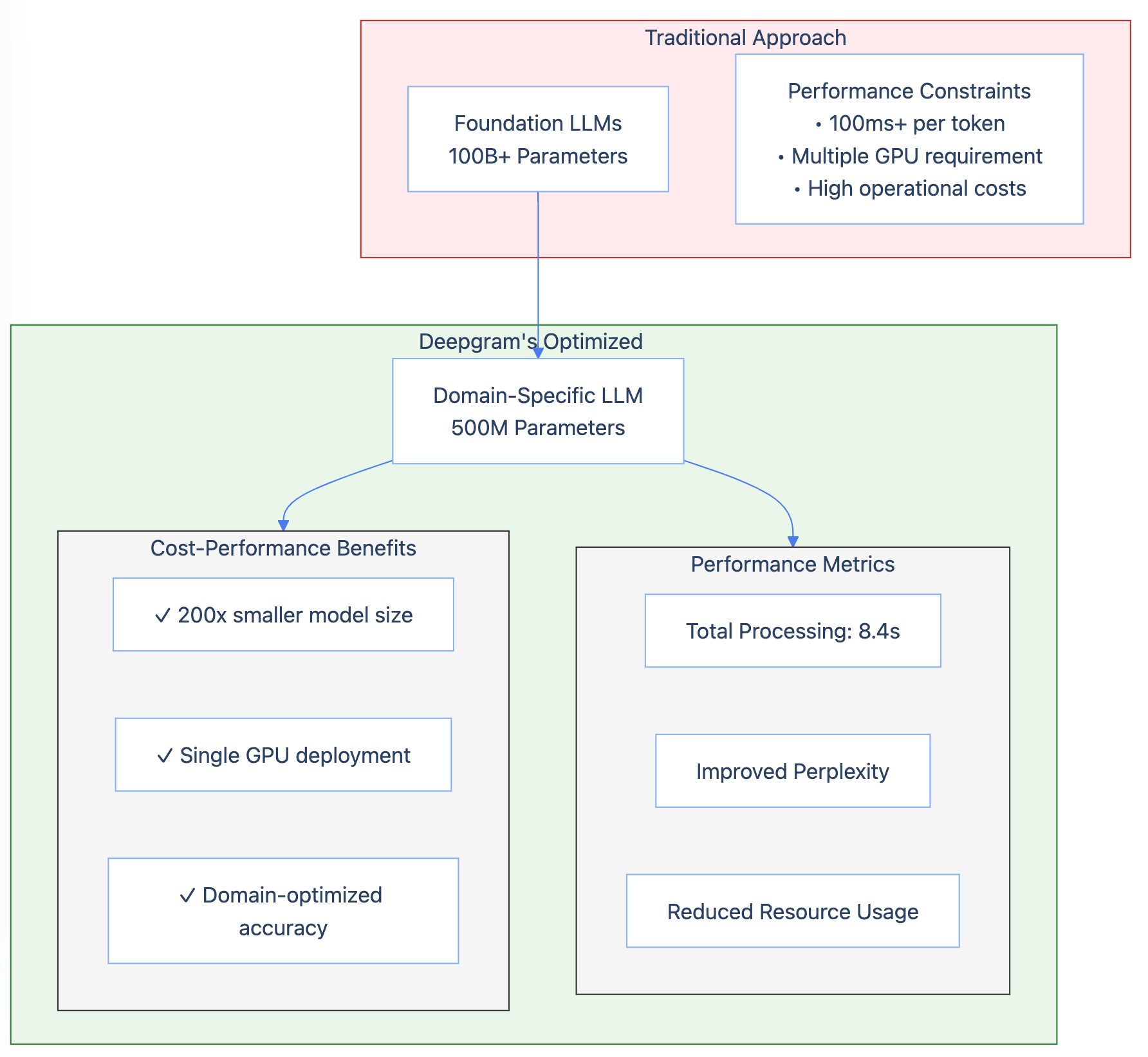
Deepgram demonstrated that a relatively small, 500M parameter model, fine-tuned on call center transcripts, could outperform much larger, general-purpose models on crucial tasks like conversation continuation and summarization. This resulted in significant cost savings and improved latency, highlighting that the largest model isn’t always the best choice. Careful consideration of the specific task and dataset can lead to significant efficiency gains.
BenchSci’s success in drug discovery showcases the power of combining domain expertise with a suitable LLM. By integrating their comprehensive biomedical knowledge base with Google’s Med-PaLM, they created a system that achieved a 40% increase in scientist productivity and reduced processing time from months to days. This highlights the potential of combining specialized LLMs with curated data for targeted performance gains in specific domains. This targeted approach also minimizes the risk of hallucinations, which can be particularly damaging in high-stakes fields like healthcare
Knowledge distillation is a potent technique for optimizing model size without sacrificing performance. LinkedIn’s skills extraction system, achieving an 80% model size reduction, exemplifies this. Faire, similarly, achieved a 28% improvement in search relevance prediction accuracy compared to their previous GPT model by using a distilled Llama model, demonstrating the technique’s effectiveness for scalable, cost-effective LLM applications.
Model quantization, reducing the precision of model weights, significantly reduces model size and inference latency. Mercari’s dynamic attribute extraction system, for example, achieved a 95% model size reduction and a 14x cost reduction compared to GPT-3.5-turbo through quantization. Replit also leveraged quantization for optimizing their code repair model serving, further demonstrating its practical benefits for resource-constrained deployments.
Inference Optimization Techniques
Caching strategies are essential. Dropbox’s multi-tiered caching system, storing embeddings, intermediate results, and final outputs, drastically reduced their reliance on real-time inference. Similarly, Bito’s multi-LLM orchestration system uses caching to manage API rate limits and reduce latency, demonstrating the versatility of caching for both cost and performance optimization. Whatnot’s e-commerce search and Honeycomb’s query assistant also demonstrate the value of strategic caching in LLM applications.
Batching improves throughput, especially for embeddings or large-scale inference (like Meta’s LLaMA training). However, batching can introduce latency. Separately, Replit optimized their model loading process by switching container images and leveraging local SSDs, significantly reducing server startup time and enabling the use of cost-effective preemptible GPU instances.
Hardware acceleration is crucial. ElevenLabs leverages NVIDIA GPUs with multi-instance and time-sharing to achieve remarkable scalability in multilingual speech synthesis. Fuzzy Labs, working with self-hosted LLMs, achieved a 10x throughput improvement using vLLM’s optimized paged attention on GPUs. Meta’s 24K GPU clusters demonstrate the scale needed for massive LLM training, while Databricks optimized their custom documentation generation model for A10 GPUs, achieving a 10x cost reduction. These examples highlight the importance of selecting and optimizing for specific hardware.
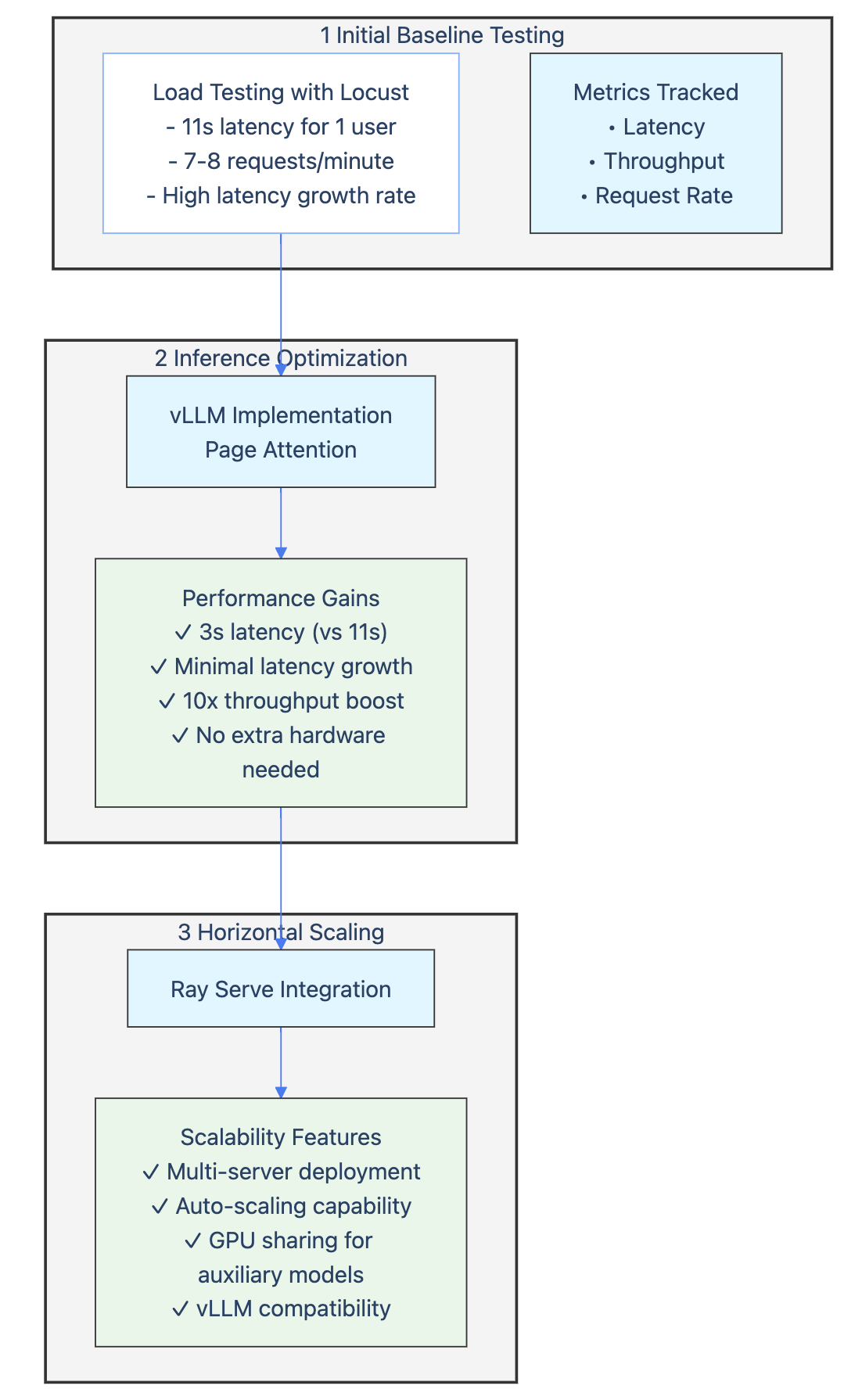
Optimization libraries like vLLM and Flash Attention have proven instrumental in pushing the boundaries of LLM performance. Fuzzy Labs achieved a 10x throughput improvement by implementing vLLM with paged attention, while Replit and Dropbox have also leveraged these libraries to great effect.
Strategies for optimizing models for specific hardware platforms are another area of innovation. AWS Trainium, a purpose-built machine learning chip, has been successfully utilized for efficient LLM training and inference. Databricks’ custom documentation generation system also showcases the value of hardware-specific optimization, achieving a 10x reduction in inference costs on A10 GPUs.
Cost Optimization Strategies
Prompt engineering is a powerful cost optimization lever. Bito’s system demonstrates this by carefully crafting prompts and selecting the most cost-effective model per task. Numbers Station, facing scaling challenges for SQL generation, also found efficient prompt engineering crucial for minimizing token usage. Ubisoft, in their game content generation pipeline, optimized prompts for token efficiency, leading to substantial cost savings. Beyond simple length reduction, effective prompt engineering involves careful wording, strategic use of few-shot examples, and clear instructions to guide the LLM towards desired outputs with minimal wasted tokens.
The API vs. self-hosting decision hinges on factors like scale, data privacy, and control. APIs offer convenience but can be costly at high volumes. Digits opted for self-hosting their financial document processing system for cost control and data privacy. Dropbox’s ‘Silicon Brain’ project similarly uses self-hosting for their universal search platform, prioritizing cost-effectiveness and data security at massive scale. This suggests a tipping point where self-hosting becomes more attractive as query volume and privacy concerns grow.
Token optimization maximizes information conveyed within the token budget. Grammarly’s CoEdit achieves remarkable performance with a small model size due to meticulous token optimization. Similarly, Prosus’s ‘token economy’ approach, where they actively monitor and optimize token usage across different tasks and languages, demonstrates that small improvements in token efficiency can yield substantial cost savings at enterprise scale.
Monitoring and Analysis
Continuous monitoring is essential. Weights & Biases’ WandBot, Honeycomb’s LLM observability platform, and Paradigm’s agent operations dashboard exemplify comprehensive monitoring solutions. These tools track key metrics like token usage, latency, and cost, providing actionable insights for data-driven optimization. Beyond these specialized platforms, integrating with standard monitoring tools like Prometheus and Grafana can also provide valuable insights into LLM performance and resource utilization.
Conclusion
The LLMOps database reveals a clear evolution in how organizations are optimizing their LLM deployments, challenging the assumption that bigger models and more compute power are always better. The most successful implementations share a common thread: they combine targeted model optimization, strategic infrastructure choices, and systematic monitoring to achieve optimal performance within their constraints.
The evidence from companies like Deepgram, LinkedIn, and Dropbox shows that sophisticated caching strategies, hardware-specific optimization, and careful model selection often outperform brute force approaches. Organizations achieving the best results typically start with prompt optimization and caching, which offer immediate returns, before moving to more complex optimizations like model distillation or hardware-specific tuning.
The self-hosting versus API decision emerges as a key inflection point, with companies like Digits and Dropbox demonstrating that self-hosting becomes advantageous at higher query volumes, particularly when privacy requirements come into play. However, this transition requires careful consideration of monitoring and infrastructure management capabilities.
These patterns provide a practical framework for optimization, grounded in real-world implementations rather than theoretical possibilities. The key lies not in pursuing every possible optimization, but in selecting and sequencing improvements based on specific organizational constraints and requirements, supported by systematic measurement and iterative refinement.


