
On this page
The rapid adoption of large language models (LLMs) has ushered in a new era of AI possibilities—and a new set of security challenges. As organizations navigate this uncharted territory, valuable lessons are emerging from the front lines of LLM deployment. In this deep dive, we’ll explore the key insights and strategies gleaned from real-world case studies, providing a practical roadmap for securing your own LLM applications.
All our posts in this series include NotebookLM podcast ‘summaries’ that capture the main themes of each focus. Today’s blog is about security (specifically that around GenAI systems) in production so this podcast focuses on some of the core case studies and how specific companies developed and deployed application(s) where this was a core focus.
To learn more about the database and how it was constructed read this launch blog. Read this post if you’re interested in an overview of the key themes that come out of the database as a whole. To see all the other posts in the series, click here. What follows is a slice around how security was found in the production applications of the database.
The Evolving Threat Landscape 🌍🎯
LLMs introduce a unique attack surface that demands a rethinking of traditional security approaches. The case studies in the LLMOps database paint a vivid picture of the risks:
- Prompt Injection Attacks
Dropbox’s research reveals how malicious actors can manipulate prompts to bypass instructions and leak sensitive information. By weaponizing control characters like backspace and carriage return, attackers were able to manipulate GPT-3.5 and GPT-4 models to ignore instructions and reveal internal model data. Beyond direct attacks, indirect prompt injection poses a significant threat. This occurs when an LLM retrieves information from an external source that contains a malicious prompt. Imagine a RAG system retrieving information from a compromised website or a malicious document within a company’s knowledge base. This poisoned data can then influence the LLM’s behavior in unintended ways.
For example, NVIDIA’s research on RAG system vulnerabilities showed how attackers could exploit vulnerabilities in retrieval mechanisms to inject malicious code into the LLM’s context, resulting in a 9.3x speedup in attack execution. This emphasizes the importance of carefully vetting external data sources and implementing robust sanitization procedures for retrieved content.
- Data Leakage through RAG
Retrieval-augmented generation (RAG) systems introduce new challenges for data privacy and security. As demonstrated in QuantumBlack’s real-world experience with an insurance company, RAG systems need careful consideration not just for data privacy, but also for data freshness and accuracy. In their example, what seemed like a straightforward implementation of a claims processing system revealed complex challenges around document versioning and potential risks of exposing outdated policy information. Their engineers emphasized the importance of proper data management practices, including ensuring data recency, implementing access controls, and carefully considering what sensitive data actually needs to be included in the RAG system. This aligns with their broader observation that over 70% of companies believe AI introduces new data risks that need to be carefully managed.
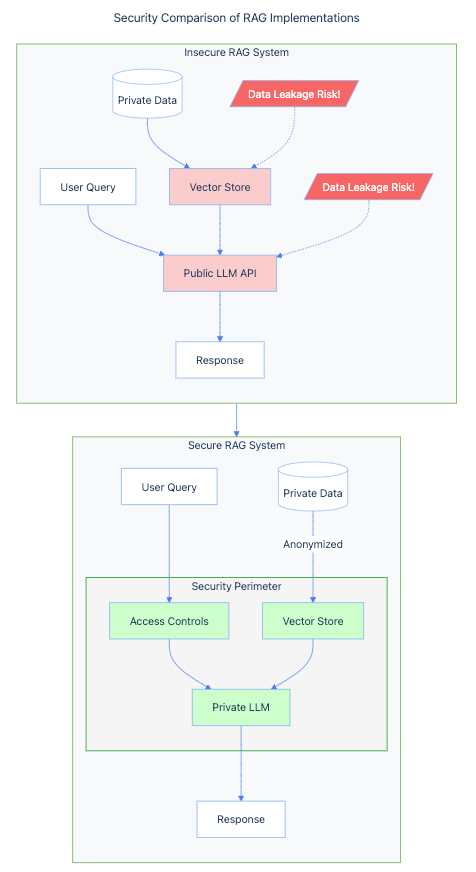
For example, in healthcare settings, organizations must be particularly careful with how they implement RAG systems. John Snow Labs demonstrates this through their approach of deploying their entire system, including LLMs, within the client’s infrastructure to prevent any PHI from leaving the security perimeter. They emphasize the importance of having proper controls around data access, terminology mapping, and careful consideration of how patient data is processed and presented. This highlights the broader need for data privacy awareness throughout the entire LLMOps lifecycle, especially when dealing with sensitive information.
- Plugin Vulnerabilities
The integration of external tools and plugins, as discussed in NVIDIA’s Security Learnings presentation, expands the attack surface. Insecure plugin architectures can provide entry points for malicious actors to compromise the system.
Arcade AI’s tool calling platform demonstrates a security-focused approach to agent-tool integration. Their system includes an authentication and authorization layer that controls which tools an agent can access, preventing unauthorized actions. They also provide a sandboxed execution environment for tools, further limiting the potential impact of malicious code or unexpected behavior. This focus on secure integration is crucial for building reliable and trustworthy agent-based systems.
Beyond securing the infrastructure and data pipelines around LLMs, hardening the models themselves is crucial. This involves techniques like robust fine-tuning and adversarial training. Fine-tuning on carefully curated datasets, as demonstrated by Tinder in their Trust and Safety system, can make models more resilient to malicious prompts and less likely to generate harmful content. Adversarial training, while still an active research area, involves exposing the model to a wide range of adversarial inputs during training, teaching it to recognize and resist malicious attempts to manipulate its behavior. This can be particularly effective against prompt injection attacks, as seen in research by Patronus AI in developing their Lynx hallucination detection model. Investing in these model-level defenses can significantly enhance the overall security posture of LLM applications.
Layered Defenses: A Holistic Approach 🛡️🧱
Mitigating the risks associated with LLMs requires a multi-faceted, layered approach to security. The case studies offer valuable insights into effective strategies:
Input Sanitization and Validation 🧹✅
Honeycomb’s Query Assistant and Dropbox’s recommendations underscore the importance of thoroughly cleaning and validating user inputs. By implementing robust sanitization techniques, organizations can prevent malicious prompts from exploiting vulnerabilities. This layer of defense acts as a critical gatekeeper, ensuring that only valid inputs reach the LLM.
Output Validation and Filtering 🔍🚫
Detecting and filtering potentially harmful LLM outputs is another crucial layer of protection. By implementing advanced techniques like anomaly detection and content classification, organizations can identify and block malicious responses before they cause damage. The Microsoft Enterprise LLM Deployment presentation highlights the value of incorporating output validation into the overall security strategy.
A practical example of output filtering comes from Grammarly’s DeTexD system. While not strictly a security feature, DeTexD demonstrates how LLMs can be trained to identify and flag “delicate” text—content that is emotionally charged or potentially triggering—achieving a 79.3% F1 score on their benchmark dataset. This approach can be adapted for security contexts by training models to recognize and filter outputs that violate specific security policies, such as revealing sensitive information or providing instructions for malicious activities. This proactive approach to output filtering can significantly reduce the risk of harmful or inappropriate LLM-generated content reaching end-users.
Another example is from the JOBifAI case study, where they implemented a retry mechanism specifically to handle safety filter triggers, achieving a 99% success rate after three retries. While their solution addressed the immediate problem, it also highlighted the need for more transparent and granular error reporting from safety filters to enable more sophisticated error handling and improve user experience.
Prompt Engineering Best Practices 📝🏗️
Careful prompt design can significantly reduce the risk of injection attacks. By crafting prompts that are resistant to manipulation and incorporating techniques like input validation and schema enforcement, organizations can create more secure LLM interactions. The various prompt engineering examples in the LLMOps database provide a wealth of ideas for designing robust prompts.
Prompt engineering can be a source of vulnerability, but it can also be a powerful defense against prompt injection. Microsoft’s best practices for LLM deployment emphasize the importance of clear and concise prompt instructions, explicitly defining the expected behavior and constraints. Techniques like specifying output formats, using delimiters to separate instructions from data, and incorporating few-shot examples can make prompts more resistant to manipulation.
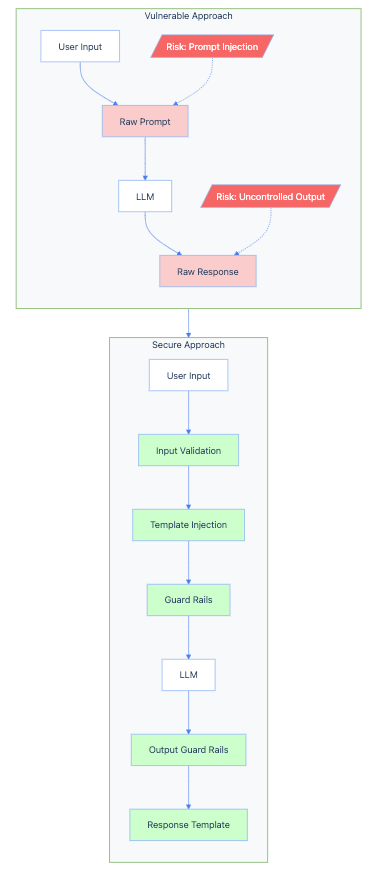
Beyond general prompt engineering best practices, security-specific prompt engineering is crucial. This involves crafting prompts that explicitly instruct the LLM to avoid generating security-sensitive information, such as API keys, passwords, or internal system details. Prompts should also be designed to resist manipulation by malicious actors attempting to inject harmful instructions. Techniques like parameterizing user inputs, using delimiters to clearly separate instructions from data, and incorporating few-shot examples of secure responses can significantly enhance the security of LLM interactions.
The Numbers Station case study, where they built a SQL data analyst agent, provides a good example of how careful prompt engineering can be used to implement deterministic workflows and prevent behavioral issues that could lead to security vulnerabilities.
Multi-layered Defenses 🧱🔒
As emphasized in Accenture’s Knowledge Assist case study, a comprehensive security approach combines multiple layers of protection. By integrating input sanitization, output filtering, and prompt engineering, organizations can create a formidable defense against LLM attacks. The redundancy and overlapping controls provided by a multi-layered architecture help ensure that if one layer fails, others can still prevent a breach.
Data Privacy: Safeguarding Sensitive Information 🔐📊
Protecting sensitive data is a paramount concern in LLM deployments, particularly in RAG systems where data leakage risks are heightened. The case studies highlight several key strategies for maintaining data privacy:
Secure Data Storage and Access Control 🗄️🔐
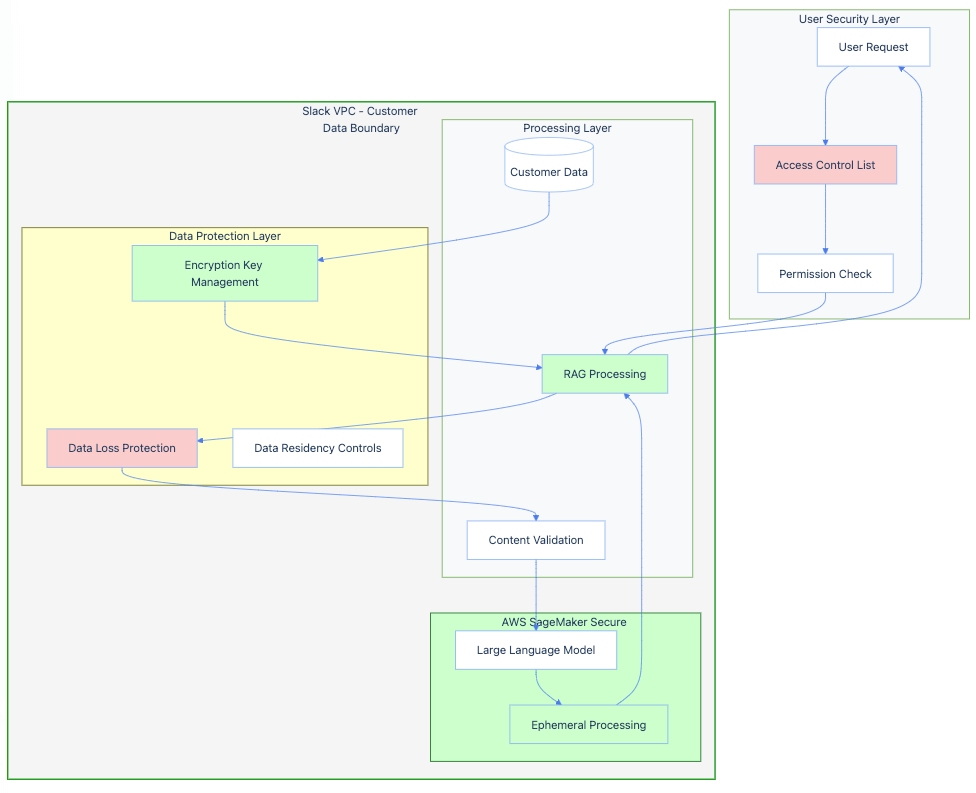
Slack’s secure architecture and BNY Mellon’s Virtual Assistant demonstrate the importance of implementing robust data storage and access control measures. By encrypting data at rest and in transit, enforcing strict access policies, and leveraging secure computing environments, organizations can significantly reduce the risk of unauthorized access to sensitive information.
Data Anonymization and Pseudonymization 🎭🔍
Techniques like data anonymization and pseudonymization, as employed in the Amazon Pharmacy Chatbot and Grab Gemini implementations, can help protect personally identifiable information (PII) when training and using LLMs. By removing or masking sensitive data elements, organizations can mitigate the risk of data leakage while still benefiting from the power of LLMs.
Privacy-Preserving Training Techniques 🔐🧠
Emerging techniques like differential privacy and federated learning offer promising approaches for training LLMs while preserving data privacy. While the case studies don’t dive deep into these techniques, they represent an important area of ongoing research and development in the LLM security landscape.
Fine-tuning models on sensitive data introduces additional privacy risks. Even if the data is anonymized, there’s a possibility that the model could memorize and potentially leak sensitive information. Companies like Digits, in their work on financial document processing, chose to self-host and fine-tune their models on carefully curated internal data to mitigate this risk. They also implemented strict access controls and monitoring systems to further enhance data security.
Choosing the Right Deployment Option ☁️🏢
The choice between using third-party APIs, self-hosting, or hybrid approaches can have significant implications for data privacy and security. The Zillow Fair Housing Guardrails and HealthInsuranceLLM Appeals System case studies showcase how different deployment strategies can impact the security posture of LLM applications. Organizations must carefully evaluate the trade-offs and select the deployment option that best aligns with their security requirements and risk tolerance.
Monitoring and Observability: The Ever-Watchful Eye 👁️📈
Effective monitoring and observability practices are essential for detecting and responding to security incidents in LLM deployments. The case studies highlight several key techniques:
Logging and Auditing LLM Interactions 📝🔍
Honeycomb’s Query Assistant and Replit’s LangSmith integration demonstrate the value of comprehensive logging and auditing of LLM interactions. By capturing user prompts, model outputs, and other relevant information, organizations can gain valuable insights for security analysis and incident response.
While basic logging is important, LLMOps requires more sophisticated observability tools. LangSmith, for example, provides deep tracing capabilities for LLM agents, allowing developers to inspect the entire chain of agent actions, tool calls, and model responses. This level of visibility is crucial for identifying and debugging security vulnerabilities, as well as understanding the root cause of unexpected agent behavior. Replit and Podium are just two examples of companies leveraging LangSmith for enhanced agent observability.
Anomaly Detection 🚨📊
Implementing anomaly detection techniques can help identify unusual or suspicious LLM behavior. By establishing baselines for normal activity and monitoring for deviations, organizations can quickly detect potential security threats and take appropriate action.
Real-time Threat Monitoring 🕵️♂️📡
As highlighted in the case studies, real-time monitoring for prompt injection attempts and other threats is crucial for maintaining the security of LLM applications. By continuously analyzing LLM interactions and system logs, organizations can identify and respond to security incidents in a timely manner.
Traditional intrusion detection systems (IDS) are often inadequate for LLM-powered applications. The probabilistic nature of LLMs and the potential for novel attack vectors necessitate new approaches to threat detection. Researchers are exploring techniques like anomaly detection, which can identify unusual patterns in prompt inputs or model outputs, as well as adversarial training, where models are specifically trained to recognize and resist malicious prompts. While still in early stages, these techniques represent a promising direction for enhancing LLM security.
Human Oversight and Explainability
While automated defenses are essential, human oversight remains a critical component of LLM security. The probabilistic nature of LLMs and the potential for unforeseen vulnerabilities make it crucial to maintain human-in-the-loop processes for reviewing and validating LLM outputs, especially in high-stakes applications. Furthermore, explainability is vital for building trust and accountability in LLM systems.
Techniques like chain-of-thought prompting and source attribution, as demonstrated in several case studies, can help make LLM decision-making more transparent and understandable. This transparency is not only beneficial for security analysis but also for building user trust and ensuring responsible AI deployment. For example, the Austrian Post Group’s use of LLM agents for user story enhancement included human evaluation by agile team members to validate the effectiveness and quality of the AI-generated suggestions.
Security Implementation Summary
The case studies demonstrate that effective LLM security requires combining traditional security principles with LLM-specific controls. A defense-in-depth approach emerges as the foundation, integrating input sanitization, output validation, and prompt engineering rather than relying on any single protective measure.
Data privacy implementation demands both technical and procedural controls: encryption at rest and in transit, strict access control and authentication, and careful consideration of anonymization techniques where appropriate. The choice between self-hosting versus API services remains a key architectural decision driven by security requirements.
Comprehensive monitoring forms the third pillar of LLM security, encompassing interaction logging, LLM-specific anomaly detection, and real-time monitoring for prompt injection attempts. The probabilistic nature of LLMs necessitates specialized security testing approaches and monitoring tools that go beyond traditional security measures.
Organizations should prioritize these security measures based on their specific threat models and compliance requirements, recognizing that while LLM technology introduces complexity, methodical application of security principles can create robust systems.


