

On this page
Prompt engineering is the art and science of crafting instructions that unlock the potential of large language models (LLMs). It’s a critical skill for anyone working with LLMs, whether you’re building cutting-edge applications or conducting fundamental research. But what does effective prompt engineering look like in practice, and how can we systematically improve our prompts over time?
To answer these questions, we’ve distilled key insights and techniques from a collection of LLMOps case studies spanning diverse industries and applications. From designing robust prompts to iterative refinement, optimization strategies to management infrastructure, these battle-tested lessons provide a roadmap for prompt engineering mastery.
All our posts in this series will include NotebookLM podcast ‘summaries’ that capture the main themes of each focus. Today’s blog is about prompt engineering and management in production so this podcast focuses on some of the core case studies and how specific companies developed and deployed application(s) where this was a core focus.“
To learn more about the database and how it was constructed read this launch blog. Read this post if you’re interested in an overview of the key themes that come out of the database as a whole. To see all the other posts in the series, click here. What follows is a slice around how prompt engineering was found in the production applications of the database.
Designing Prompts That Work: Structure, Specificity, and Representation 🏗️
Effective prompt design is all about clarity, specificity, and representativeness. Canva’s approach to automated post-incident review summarization illustrates these principles in action. Their structured prompts include explicit task instructions, desired output format, and carefully selected examples that guide the model towards generating comprehensive yet concise summaries. By providing this level of guidance upfront, Canva’s system produces more reliable and consistent results.
Iterative prompt engineering was a key technique in developing Fiddler’s documentation chatbot, enabling the creation of prompts that generalize well across diverse user queries. Instead of extensive fine-tuning, the team focused on designing domain-specific prompt templates and continuously refining them based on real-world interactions. This iterative approach allowed the chatbot to adapt flexibly to new questions while maintaining accuracy and relevance in its responses.
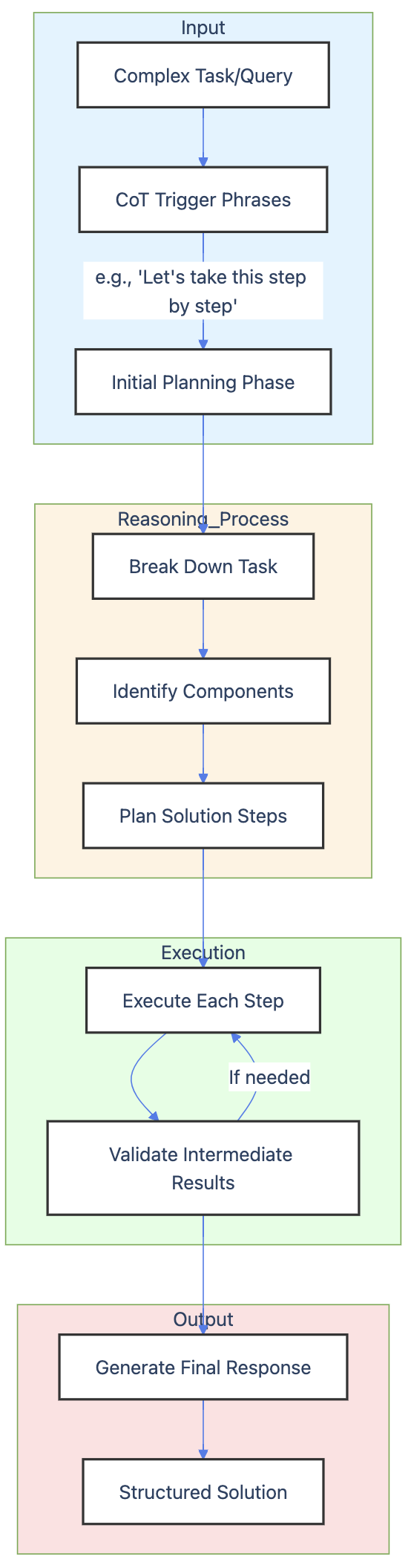
Chain-of-thought (CoT) prompting has proven to be a powerful tool for enhancing model reasoning in multi-step or complex tasks. Instacart’s case study demonstrates how CoT techniques, such as using phrases like “Let’s take this step by step” or “First, make a plan,” guide the model to generate coherent and reliable outputs. By explicitly breaking down reasoning processes, CoT not only improves the model’s ability to handle conditional and multi-step tasks but also allows for more structured and thoughtful responses. Practical examples from Instacart include generating pull request descriptions and brainstorming article titles, showcasing the real-world utility of this method.
Key Takeaways:
- Structure prompts with clear instructions, format specifications, and examples
- Use representative examples for few-shot learning and generalization
- Break down complex tasks with chain-of-thought prompting
Iterative Prompt Refinement: Experimentation, Analysis, and Continuous Improvement 🔬
Crafting the perfect prompt is an itertive process, requiring systematic experimentation, analysis, and refinement. Weights & Biases’ approach to evaluating their Wandbot assistant demonstrates the value of rigorous prompt testing and performance tracking. By maintaining a versioned prompt repository and a comprehensive evaluation dataset, the team was able to methodically assess variations and identify areas for improvement. This systematic approach enables data-driven prompt optimization, ensuring that refinements are grounded in real performance metrics.
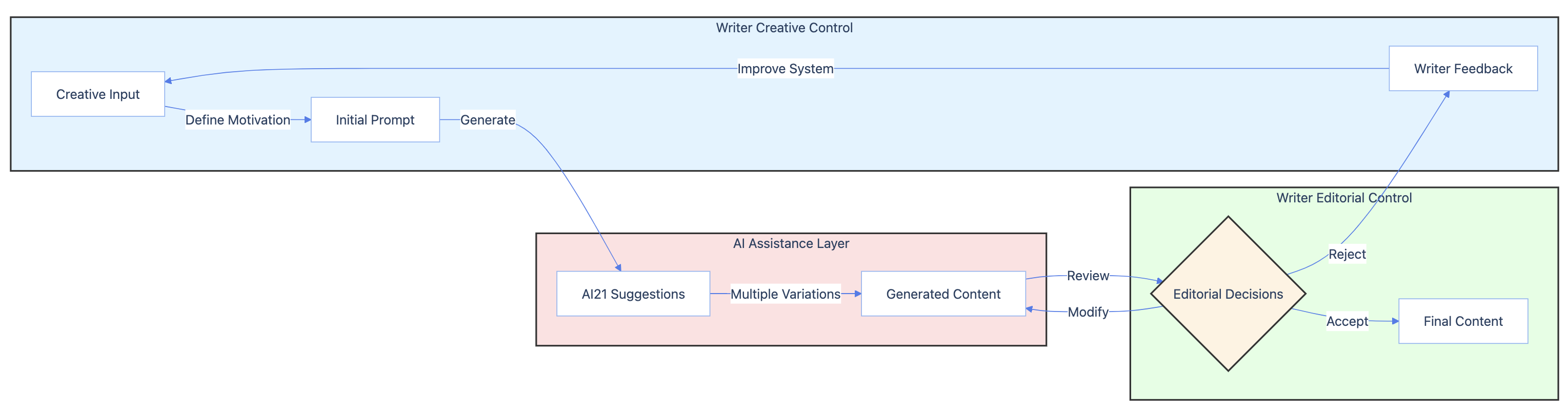
Human feedback is another essential ingredient in prompt refinement, particularly for specialized domains. Ubisoft’s writer-assisted review process for AI-generated game dialogue highlights the importance of expert input in fine-tuning prompts. By involving scriptwriters in the editing and approval flow, Ubisoft maintains a high quality bar while leveraging the efficiency of LLM-assisted writing. This human-in-the-loop approach ensures that prompts are not only technically sound but also aligned with creative goals and brand voice.
Error analysis is a powerful complement to human feedback, providing targeted insights for prompt improvement. Microsoft’s cloud incident management system demonstrates this principle in action. By systematically examining failure modes and edge cases, and updating prompts to address specific issues, the team continuously improves the model’s performance and reliability. This iterative refinement loop, driven by real-world error analysis, is key to building robust and adaptive LLM applications.
Key Takeaways:
- Establish systematic prompt testing and performance tracking infrastructure
- Incorporate human feedback, especially from domain experts, into prompt refinement
- Use error analysis to identify targeted areas for prompt improvement
Prompt Optimization at Scale: Efficiency, Modularity, and Value Alignment 📈
As LLM applications scale, prompt optimization becomes essential for managing costs and improving efficiency. Assembled’s case study highlights the strategic use of prompt design in automating test generation, emphasizing techniques like reducing low-information context, using concise instructions, and modularizing prompts for specific tasks. By minimizing token usage while maintaining semantic clarity, their team improved productivity, reduced test-writing overhead, and ensured scalability of LLM-driven workflows.

Retrieval-augmented prompting, employed by Fiddler for example, offers another powerful optimization strategy. Instead of encoding all relevant information in the prompt itself, these systems dynamically inject context from external knowledge bases. This approach allows for more focused and efficient prompts, while enabling the generation of highly specific and factual responses. As retrieval systems improve, this technique could significantly extend the capabilities of LLMs without compromising efficiency.
Ubisoft’s output-based token pricing model with AI21 Labs demonstrates an innovative approach to aligning prompting costs with value creation. By structuring pricing around the quality and utility of generated content, rather than raw input/output volume, this model incentivizes more targeted and efficient prompt design. This alignment of economic incentives with application objectives is a valuable consideration for any organization seeking to operationalize LLMs at scale.
Key Takeaways:
- Optimize prompts for efficiency through condensation and retrieval augmentation techniques
- Consider output-based pricing models to align prompting costs with value creation
- Balance prompt specificity with modularity and reusability across use cases
Prompt Management Infrastructure: Tools, Frameworks, and Collaboration 🏗️
Effective prompt management at scale requires robust infrastructure for versioning, testing, and collaboration. Weights & Biases’ prompt versioning system and experiment tracking setup demonstrate the value of systematic version control and structured metadata. By treating prompts as versioned artifacts, with clear lineage and performance metrics, teams can more effectively manage the prompt development lifecycle and conduct meta-analyses across experiments.
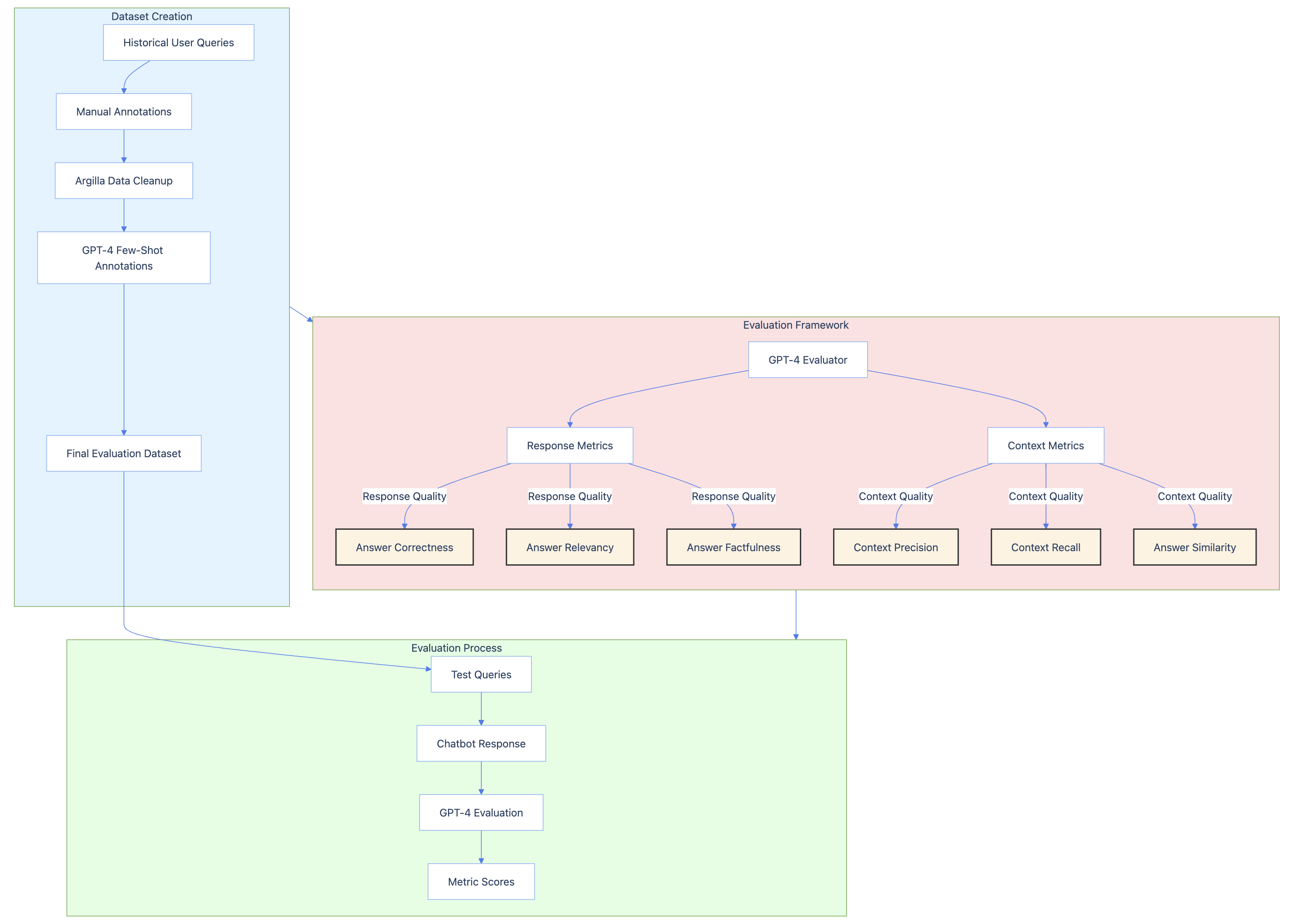
Automated evaluation frameworks, such as those developed by Canva and Weights & Biases, are another essential component of prompt management infrastructure. By codifying evaluation criteria into automated scoring systems, and using expert-annotated datasets for benchmarking, these frameworks enable teams to efficiently assess and compare prompt variations at scale. This systematic evaluation infrastructure is particularly valuable for use cases where prompt performance has significant business or operational impact.
Workflow integration is a key consideration for prompt management at scale. Instacart’s case study highlights the importance of embedding prompt engineering techniques into the broader development ecosystem. By creating tools like their internal assistant Ava and leveraging techniques such as Puppetry and Monte Carlo, Instacart demonstrates how teams can streamline prompt development while ensuring consistency and adaptability across projects.
Key Takeaways:
- Implement systematic prompt versioning and experiment tracking infrastructure
- Develop automated evaluation frameworks with expert-annotated benchmark datasets
- Integrate prompt engineering tools and workflows with the broader development ecosystem
The Road Ahead: Emerging Challenges and Technical Frontiers ⛰️
The field of prompt engineering continues to evolve alongside advances in language models, retrieval architectures, and development tooling. Several critical challenges and technical frontiers warrant attention as organizations scale their LLM operations.
First, the complexity of managing prompts across larger engineering teams and diverse use cases demands more sophisticated infrastructure. Current versioning systems and evaluation frameworks, while functional, need to evolve to handle problems like prompt drift, regression testing, and systematic performance tracking across model versions.
Second, emerging techniques like retrieval-augmented generation and chain-of-thought prompting are expanding the capabilities of LLM systems, but also introducing new operational challenges. Organizations must carefully balance the benefits of these advanced approaches against increased system complexity and computational overhead.
Third, as LLM applications expand into more critical domains, robust evaluation of prompt safety, reliability, and fairness becomes paramount. This includes developing better frameworks for testing prompt injection vulnerabilities, measuring factual accuracy, and ensuring consistent performance across different user populations and contexts.
Looking ahead, the maturation of prompt engineering as a discipline will likely parallel the evolution we’ve seen in traditional software engineering - with increasing emphasis on systematic testing, clear development patterns, and robust tooling. Organizations that invest in building solid prompt engineering foundations today will be better positioned to leverage future advances in language model capabilities and architectures.
The diverse case studies examined here demonstrate both the complexity and the potential of production prompt engineering. By learning from these experiences and continuing to share practical insights across the LLMOps community, we can work toward more reliable, efficient, and responsible deployment of language models in production systems.


