
On this page
You’ve spent weeks fine-tuning your RAG (Retrieval-Augmented Generation) system. You’ve integrated state-of-the-art retrieval patterns, optimized embeddings, and swapped in the latest LLMs. Yet, when users query your AI with something like, ”Postgres connection refused error” your RAG system might simply retrieve generic documentation about PostgreSQL connections, missing practical troubleshooting advice involving firewall and other rules.
What went wrong?
Your query rewriting works… in theory. But flaws in the rewrites silently affect your retrieval, degrade answers, and erode user trust. The culprit? Everyone builds RAG patterns—almost no one evaluates them properly.
We spend so much time implementing the latest RAG patterns, like query rewriting, that we often forget to ask the fundamental question: “Is this actually working in a measurable, reliable way?”. It is great to implement all of these things, but it is of the utmost importance to measure if they are working and if they improve user experience.
Quick Recap: What is Query Rewriting in RAG?
Before we dive into this problem, let’s briefly recap the basics. RAG is a technique that combines the power of large language models (LLMs) with external knowledge retrieval. Instead of relying solely on the LLM’s internal knowledge, RAG fetches relevant information from a database or document collection to provide more accurate and context-aware answers.
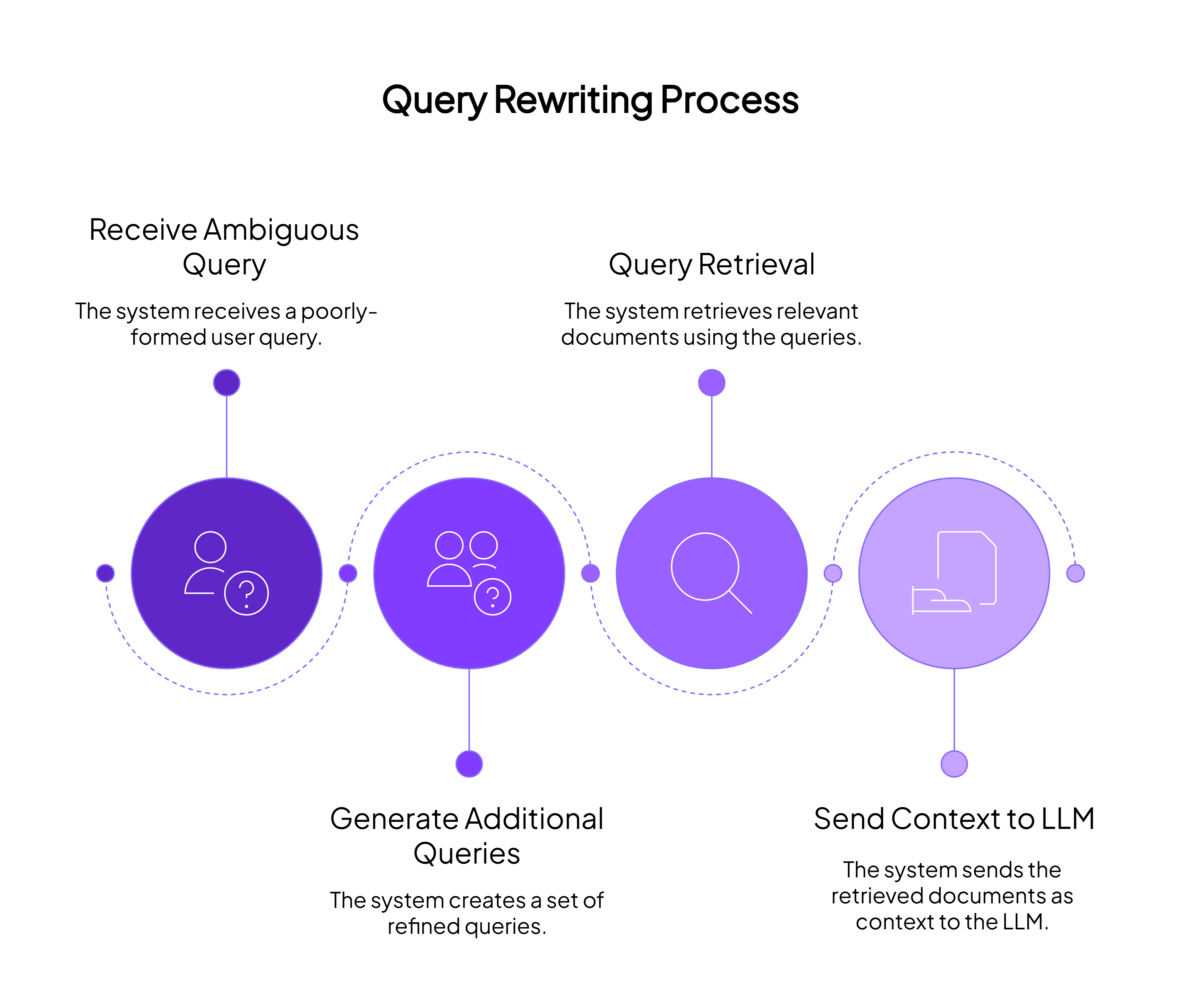
Query rewriting fits into this picture by taking ambiguous or poorly-formed user queries and transforming them into something the retrieval system can better understand.
For example:
-
User Query: “How do I configure secrets in ZenML?”
-
Rewritten Query: “What are the steps for implementing secrets management in ZenML?”
This refined query makes it much more likely that the RAG system will retrieve the *right *information, and therefore, give the better answer (Azure AI Search’s Generative Query Rewriting improves search relevance by up to +4 points. On the other hand, it does take a bit longer for the answer to be returned because you now have multiple queries to run, but there are ways to optimize for speed (through parallelism and more).
RAG and its advanced patterns are frequently covered, so we won’t spend more time here. One of many blog posts that do a good job in explaining it is here. But now that we know why query rewriting is useful, let’s move to a topic that isn’t discussed as much; evaluation.
Why Evaluation is Non-Negotiable
Okay, so you’ve got query rewriting working, in code, and you feel that your RAG system might be performing better too. But here’s the catch: without rigorous evaluation, query rewriting is surprisingly brittle, and you are essentially flying blind. I’ll complement this claim with some examples that I saw personally, while running this pattern for a RAG bot that answers questions about ZenML based on its documentation.
Below is a table that shows some results from my experimentation, where I expanded one test query into 4 queries. All of these results were obtained from my ZenML evaluation pipeline which I’ll talk about later in this post. The queries in red are those that were clearly unsatisfactory and would not add any value to the answer, or worse, lead to inaccurate results.
| Test User Query | Generated Queries | Comments |
|---|---|---|
| What are the different types of stack components? | Can you list the types of components commonly found in a tech stack? | Vague. A tech stack can be anything and doesn’t relate to a ZenML stack necessarily. |
| What various stack components exist in the system? | Fairly okay | |
| What are the main kinds of stack components in computer science? | Wrong query. This specifically asks about stack components in computer science that will lead to a non ZenML answer. | |
| What are the different categories of stack components? | Okay query. | |
| How can I deploy my model using ZenML? | What are the steps to deploy a machine learning model with ZenML? | Good query |
| Guide to deploying models in a ZenML environment | There is no ZenML environment and you cannot deploy models in ZenML but through ZenML | |
| How do I use ZenML for model deployment in production? | Good query | |
| What resources are needed for deploying models inside a ZenML project? | Again, you cannot deploy models inside a ZenML project |
The trend to note here is that, even though the model thinks it is doing a good job, there might be small inconsistencies that can change the meaning of the question without you or the model realizing. Imagine a system like this goes to production: your users will start receiving answers for questions that they never asked!
To establish why evaluation is important, I’ll put these ideas down more concretely.
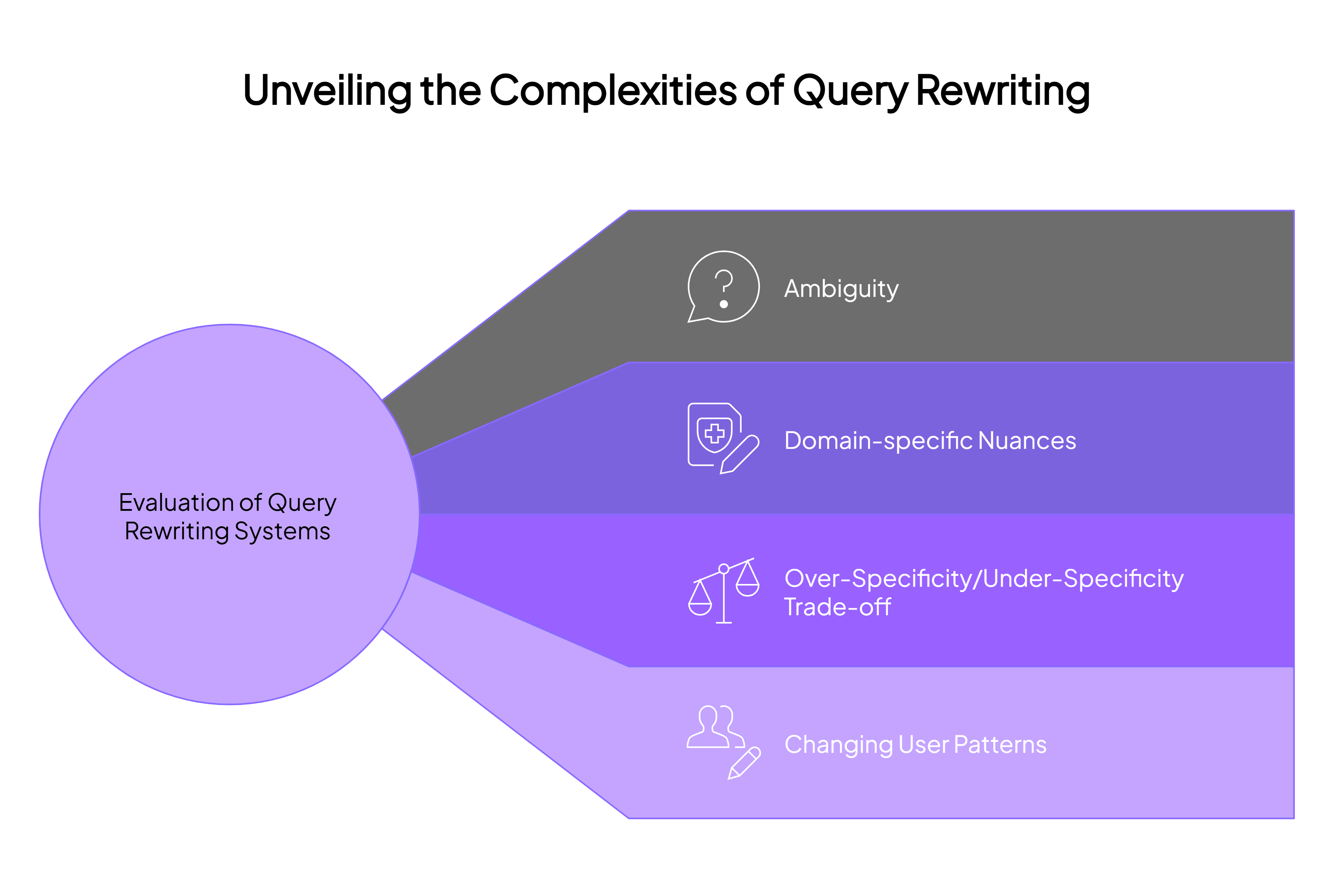
Ambiguity eats into accuracy
A rewritten query might look perfect to an LLM but miss the user’s intent entirely. For example:
-
User Query: “How do I monitor my pipeline?”
-
Rewritten Query: “How do I visualize my data in MLflow?”
(…but the user meant ZenML’s pipeline monitoring, not MLflow.)
Without evaluating whether rewrites preserve intent, you risk confidently retrieving irrelevant context.
Domain-specific nuances are hard to get right
Generic query rewriting models might not handle the specialized vocabulary, jargon, or implicit assumptions of a particular domain (e.g., medicine, law, finance).
For example, a user query with “motion” in it will have different results in the context of law, where it means a request to a court, than it will in a general context
Over-Specificity/Under-Specificity Trade-off
Query rewriting involves a delicate balance. Overly specific rewrites can exclude relevant results (false negatives), while overly general rewrites can lead to irrelevant results (false positives).
For example, rewriting a query about “step operators in ZenML” to “the Modal step operator in ZenML” will miss out on the other important operators that the user might be interested in.
The world is constantly changing (drift)
User language and search patterns are constantly evolving. What worked perfectly last month might degrade over time as new terminology emerges, trends shift, or your user base changes.
For example, rewriting “top orchestrators in ZenML” to “Airflow orchestrator in ZenML” might not be relevant always, as ZenML adds new and improved ones.
Your rewrites need to adapt, and without continuous evaluation, you won’t know when they’ve become outdated.
All of these points become clear to you when you have an automated evaluation pipeline running, and in the next section, we’ll see how ZenML can help you with it.
Building a Robust Evaluation Pipeline with ZenML
The challenges outlined above make it clear: ad-hoc, manual checks of your RAG system’s performance aren’t enough. You need a systematic, automated, and reproducible way to evaluate query rewriting. This is where ZenML comes in, transforming RAG evaluation from an afterthought into a well-defined, data-driven process.
Here’s a comparison:
-
Standard RAG Evaluation: Manual spot-checking of accuracy and retrieval, often relying on small static datasets. Difficult to reproduce and scale.
-
ZenML Pipeline-Based Evaluation: Automated, reproducible, and artifact-tracked evaluation pipelines. Integrates seamlessly with your existing RAG system, allowing you to continuously monitor and improve its performance.
Architecture
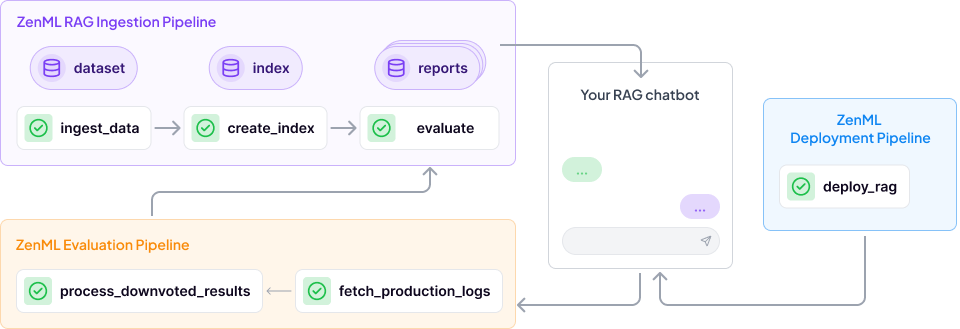
Let’s break down how a ZenML evaluation pipeline works within the context of a RAG system with query rewriting:
- Ingestion Pipeline: This remains the same as in any standard RAG system. It handles document ingestion, chunking, embedding, and indexing. ZenML makes it easy to version control your data and track the entire ingestion process. This pipeline can have a small evaluation step at the end that compares your prepared indices against a set of examples, to help you quickly decide how well your changes are affecting the system.
from zenml import pipeline
@pipeline
def rag_ingestion_pipeline() -> None:
"""Executes the pipeline to ingest docs for a RAG app.
This function performs the following steps:
1. Scrapes URLs using the url_scraper function.
2. Loads documents from the scraped URLs using the web_url_loader function.
3. Preprocesses the loaded documents using the preprocess_documents function.
4. Generates embeddings for the preprocessed documents using the generate_embeddings function.
5. Generates an index for the embeddings and documents using the index_generator function.
"""
urls = url_scraper()
docs = web_url_loader(urls=urls)
processed_docs, _, _ = preprocess_documents(documents=docs)
embedded_docs = generate_embeddings(split_documents=processed_docs)
index_generator(documents=embedded_docs)
- Deployment Pipeline: This pipeline takes your RAG app logic and combines that with the production version of your ingested docs from the ingestion pipeline and deploys it to an endpoint of your choice.
@pipeline(model=Model(name=RAG_NAME, version=ModelStages.PRODUCTION)
def rag_deployment():
"""Executes the pipeline that deploys the RAG app to HF Spaces"""
rag_app_deployment()- **Evaluation Pipeline: **This is where ZenML shines. It automatically assesses the performance of your query rewriting and the overall RAG system. Here’s a step-by-step breakdown:
1. Tracking: ZenML automatically tracks the original user query, the rewritten query generated by the LLM, the retrieved contexts from your knowledge base, and the final answer produced by the LLM. All of these are stored as versioned artifacts within ZenML’s artifact store.
2. Custom Scoring: ZenML pipelines can execute automated scoring functions, that will give a grade to the rewritten query. These metrics can include Faithfulness, Relevance, Rewrite Accuracy, Context Use and more.
3. Performance Comparison: ZenML allows you to compare performance across different versions of your query rewriting model. This makes A/B testing different rewriting strategies straightforward.
4. Visualization and Alerting: ZenML can visualize evaluation metrics in interactive dashboards. You can set up alerts to notify you of performance regressions (e.g., a sudden drop in relevance scores).
@pipeline(enable_cache=False)
def llm_eval(after: Optional[str] = None) -> None:
"""Executes the pipeline to evaluate a RAG pipeline."""
# Query rewriting evals
query_retention_score, query_retention_results = evaluate_query_information_retention(after=after)
query_length_score, query_length_results = evaluate_query_length_quality(after=after)
# Query expansion retrieval evals
failure_rate_retrieval_expansion = (
retrieval_evaluation_small_with_expansion(after=after)
)
full_retrieval_answers_expansion = (
retrieval_evaluation_full_with_expansion(after=after)
)
# E2E evals with query expansion
(
failure_rate_bad_answers_expansion,
failure_rate_bad_immediate_responses_expansion,
failure_rate_good_responses_expansion,
) = e2e_evaluation_with_expansion()
(
average_toxicity_score_expansion,
average_faithfulness_score_expansion,
average_helpfulness_score_expansion,
average_relevance_score_expansion,
) = e2e_evaluation_llm_judged_with_expansion()
visualize_evaluation_results(
query_retention_score,
query_length_score,
failure_rate_retrieval_expansion,
full_retrieval_answers_expansion,
failure_rate_bad_answers_expansion,
failure_rate_bad_immediate_responses_expansion,
failure_rate_good_responses_expansion,
)
Try it yourself
We built a project featuring the RAG query rewriting technique and it is available on our GitHub in the rag-recipes repo. We plan to add more RAG patterns going forward, so keep an eye out.
The instructions to try it out are in the README. With ZenML, all of the pipelines are tracked in the dashboard. The screenshot below shows the ingestion pipeline.
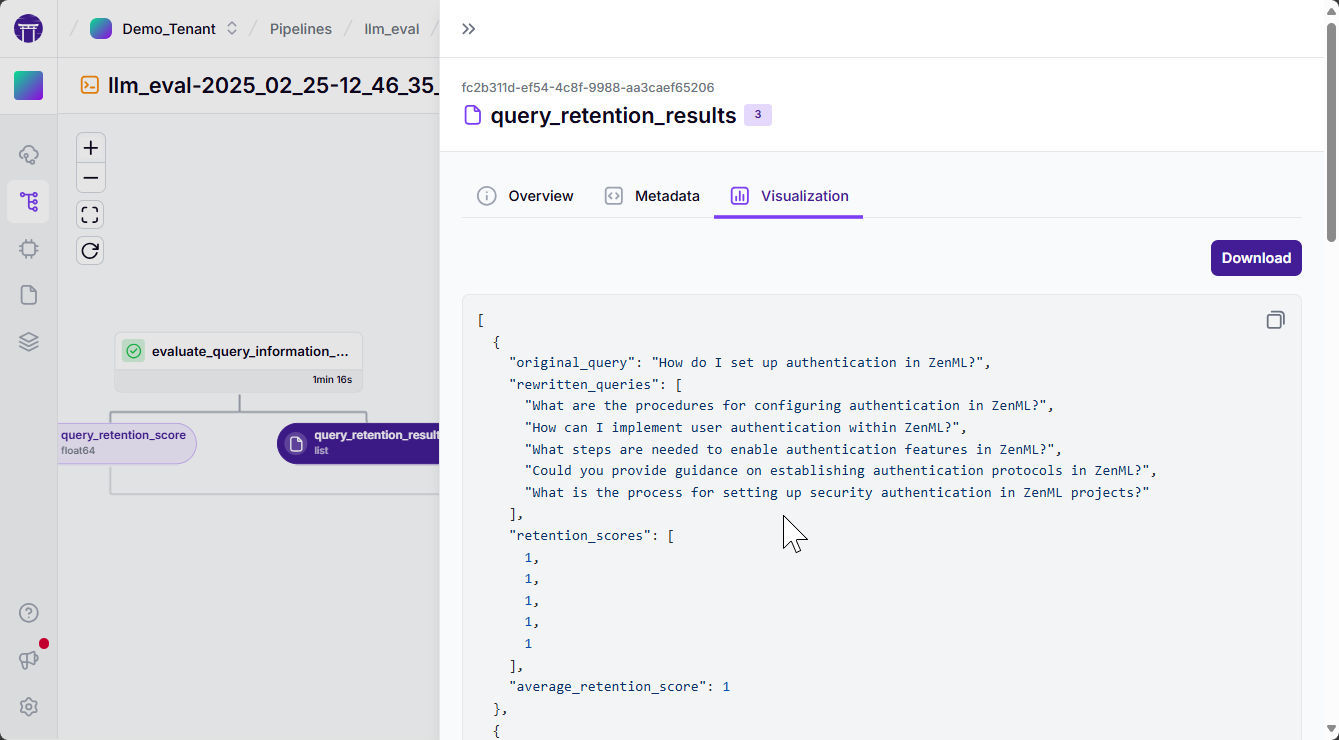
You can also look at all the output artifacts that your pipeline has produced directly by clicking on them in the DAG. The screenshot below shows the results of the query relevance retention test that checks if the generated queries preserve the intent of the original query. Any artifacts that support visualization (like HTML reports, or images) can also be viewed directly.
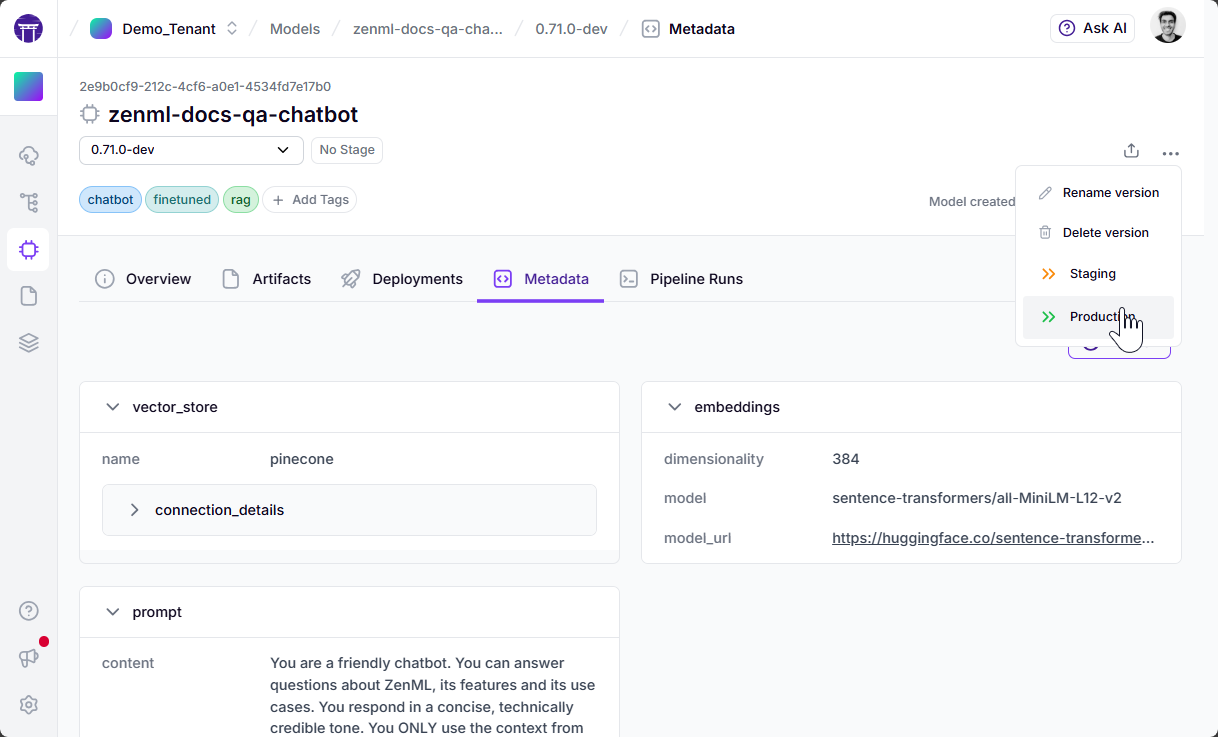
ZenML also allows you to track all the different pipelines for a project in a central control plane, from where you can also promote your model versions based on the metadata and evaluation results. The screen below shows the metadata that is tracked for our RAG project for a given version. You will also find that you can promote/demote stages of a version after looking at all the data associated with it.
Continuous Evaluation: The Foundation of Trustworthy RAG Systems
Implementing advanced RAG patterns like query rewriting undeniably boosts your system’s ability to retrieve relevant, context-enriched information and deliver a more impressive user experience. However, without rigorous, automated evaluation pipelines, the benefits remain theoretical—and risk becoming superficial at best and misleading at worst.
Not assessing your query rewriting strategies leaves critical blind spots: ambiguity in user-intent interpretation, domain-specific complexities, and subtle shifts in the language and the subject matter over time. By integrating robust, continuous, and reproducible evaluation pipelines, you turn theory into practice. You measurably improve accuracy, consistently deliver to user intent, and confidently adapt to changing domains and user needs.
ZenML offers a powerful yet intuitive way to systematically evaluate and validate your RAG implementations, transforming evaluation from a peripheral task into a first-class citizen of your AI workflows. Don’t just rewrite your queries—evaluate them systematically, rigorously, and continuously. This is the cornerstone for reliable retrieval, trustworthy responses, and superior user experiences.


