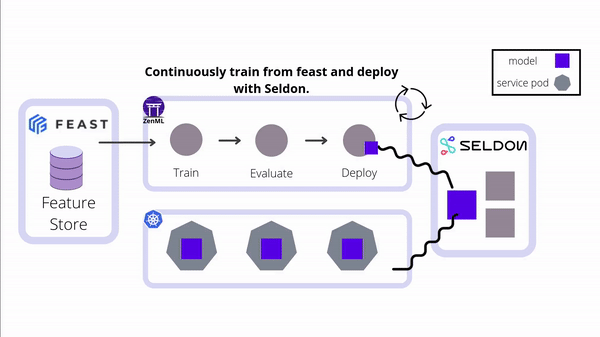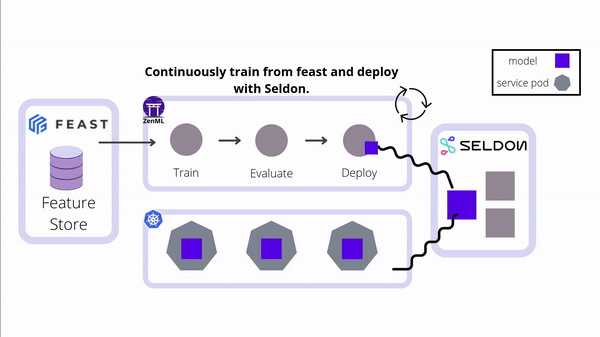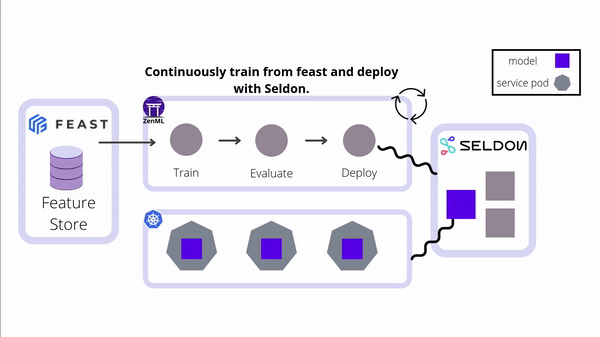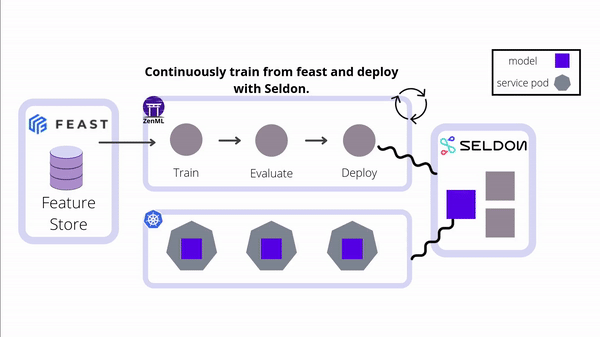
Integrate Seldon Core's powerful model serving capabilities into your ZenML pipelines for seamless deployment of ML models to Kubernetes. This integration enables advanced deployment strategies, model explainability, outlier detection, and efficient management of complex ML workflows in production environments.
from zenml.integrations.seldon.steps import seldon_model_deployer_step
from zenml.integrations.seldon.services import SeldonDeploymentConfig
from zenml import pipeline
@pipeline
def seldon_deployment_pipeline():
model = ...
seldon_model_deployer_step(
model=model,
service_config=SeldonDeploymentConfig(
model_name="my-model",
replicas=1,
implementation="SKLEARN_SERVER",
resources=SeldonResourceRequirements(
requests={"cpu": "100m", "memory": "100Mi"},
limits={"cpu": "1", "memory": "1Gi"}
)
),
)
Expand your ML pipelines with more than 50 ZenML Integrations
