
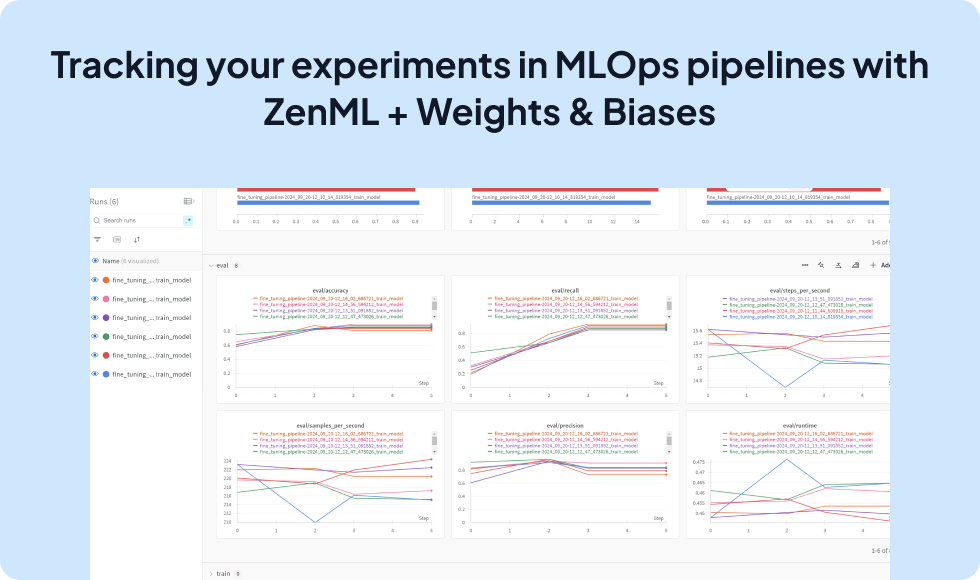
Supercharge your ZenML pipelines with seamless Weights & Biases experiment tracking and visualization
Integrate Weights & Biases with ZenML to track, log, and visualize your pipeline experiments effortlessly. This powerful combination enables you to leverage Weights & Biases' interactive UI and collaborative features while managing your end-to-end ML workflows with ZenML's pipelines.
from typing import Tuple
from zenml import pipeline, step
from zenml.client import Client
from zenml.integrations.wandb.flavors.wandb_experiment_tracker_flavor import (
WandbExperimentTrackerSettings,
)
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
DistilBertForSequenceClassification,
)
from datasets import load_dataset, Dataset
import numpy as np
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
import wandb
# Get the experiment tracker from the active stack
experiment_tracker = Client().active_stack.experiment_tracker
@step
def prepare_data() -> Tuple[Dataset, Dataset]:
dataset = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
return (
tokenized_datasets["train"].shuffle(seed=42).select(range(1000)),
tokenized_datasets["test"].shuffle(seed=42).select(range(100)),
)
@step(experiment_tracker=experiment_tracker.name)
def train_model(
train_dataset: Dataset, eval_dataset: Dataset
) -> DistilBertForSequenceClassification:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
report_to=["wandb"],
)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
precision, recall, f1, _ = precision_recall_fscore_support(
labels, predictions, average="binary"
)
acc = accuracy_score(labels, predictions)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
# Evaluate the model
eval_results = trainer.evaluate()
print(f"Evaluation results: {eval_results}")
# Log final evaluation results
wandb.log({"final_evaluation": eval_results})
return model
@pipeline
def fine_tuning_pipeline():
train_dataset, eval_dataset = prepare_data()
model = train_model(train_dataset, eval_dataset)
if __name__ == "__main__":
# Run the pipeline
wandb_settings = WandbExperimentTrackerSettings(
tags=["distilbert", "imdb", "sentiment-analysis"],
)
fine_tuning_pipeline.with_options(settings={"experiment_tracker": wandb_settings})()
Expand your ML pipelines with more than 50 ZenML Integrations