
Maintain data quality and detect drift with WhyLabs whylogs in ZenML pipelines
The WhyLabs whylogs integration with ZenML enables you to seamlessly integrate data and model profiling capabilities into your ML pipelines. By leveraging whylogs profiles, you can monitor data quality, detect data and model drift, and take automated corrective actions to ensure the reliability and performance of your models in production.
WhylogsProfilerStep, custom steps with the WhylogsDataValidator, or call the whylogs library directly.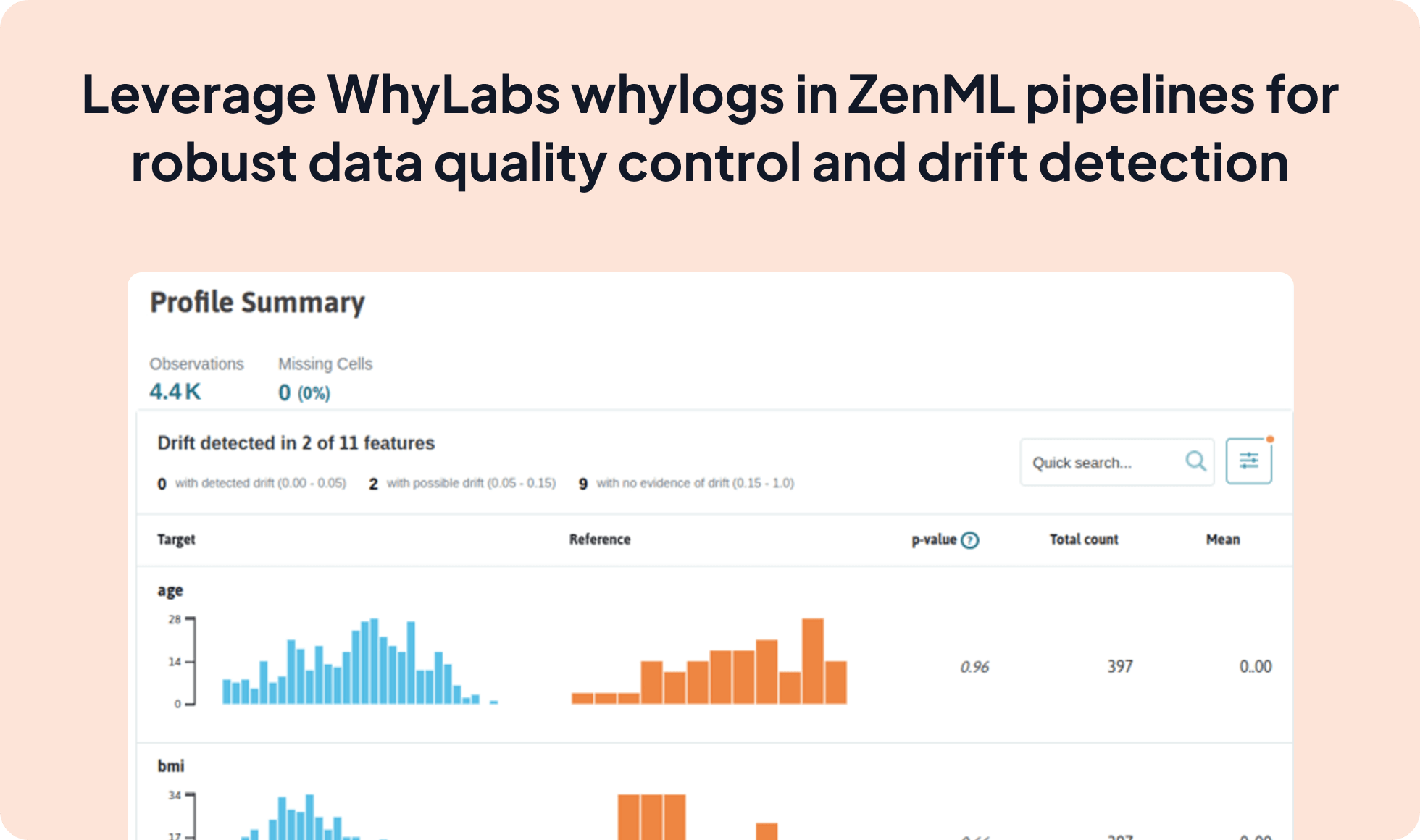
# zenml integration install whylogs -y
# zenml data-validator register whylogs_data_validator --flavor=whylogs
# zenml stack register custom_stack -dv whylogs_data_validator -o default -a default --set
from typing import Annotated,Tuple
import pandas as pd
import whylogs as why
from sklearn import datasets
from whylogs.core import DatasetProfileView
from zenml.integrations.whylogs.flavors.whylogs_data_validator_flavor import (
WhylogsDataValidatorSettings,
)
from zenml import step, pipeline
@step(
settings={
"data_validator.whylogs": WhylogsDataValidatorSettings(
enable_whylabs=True, dataset_id="model-1"
)
}
)
def data_loader() -> Tuple[
Annotated[pd.DataFrame, "data"],
Annotated[DatasetProfileView, "profile"]
]:
"""Load the diabetes dataset."""
X, y = datasets.load_diabetes(return_X_y=True, as_frame=True)
# merge X and y together
df = pd.merge(X, y, left_index=True, right_index=True)
profile = why.log(pandas=df).profile().view()
return df, profile
@pipeline(enable_cache=False)
def my_pipeline():
data, profile = data_loader()
#... do something with the data
if __name__ == "__main__":
my_pipeline()Expand your ML pipelines with more than 50 ZenML Integrations