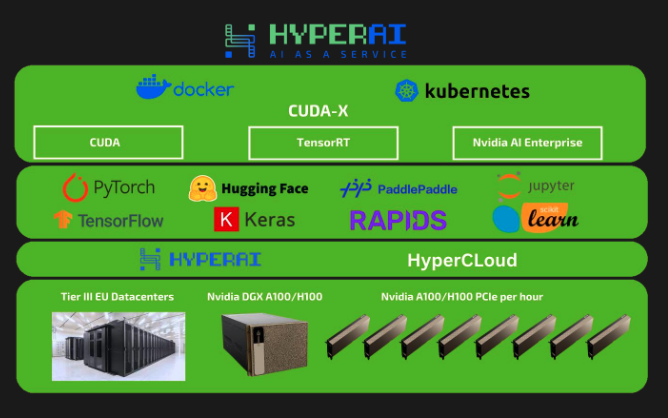
Effortlessly orchestrate your ZenML pipelines on HyperAI's cloud compute platform
Streamline your machine learning operations by deploying ZenML pipelines on HyperAI instances. This integration enables you to leverage HyperAI's cutting-edge cloud infrastructure for seamless and efficient pipeline execution, making AI accessible to everyone.
# Register the HyperAI service connector
# zenml service-connector register hyperai_connector --type=hyperai --auth-method=rsa-key --base64_ssh_key= --hostnames=,.., --username=
# Register the HyperAI orchestrator
# zenml orchestrator register hyperai_orch --flavor=hyperai
# Register and activate a stack with the HyperAI orchestrator
# zenml stack register hyperai_stack -o hyperai_orch ... --set
from datasets import Dataset
import torch
from zenml import pipeline, step
from zenml.integrations.hyperai.flavors.hyperai_orchestrator_flavor import HyperAIOrchestratorSettings
hyperai_orchestrator_settings = HyperAIOrchestratorSettings(
mounts_from_to={
"/home/user/data": "/data",
"/mnt/shared_storage": "/shared",
"/tmp/logs": "/app/logs"
}
)
@step
def load_data() -> Dataset:
# load some data
@step(settings={"orchestrator.hyperai": hyperai_orchestrator_settings})
def train(data: Dataset) -> torch.nn.Module:
print("Running on HyperAI instance!")
@pipeline(enable_cache=False)
def ml_training():
data = load_data()
train(data)
# ... do more things
# Run the pipeline on HyperAI
ml_training()
Expand your ML pipelines with more than 50 ZenML Integrations