On this page
The LLM Fine-Tuning Challenge
Fine-tuning large language models (LLMs) for specific business domains has become essential for companies looking to leverage AI effectively. However, the process is fraught with challenges:
- Data preparation complexity: Converting raw datasets into formats required by fine-tuning platforms
- Reproducibility issues: Difficulty tracking experiments across multiple iterations
- Cost management: Without proper tracking, resources are wasted on duplicate runs
- Production deployment: Moving from successful experiments to reliable production systems
- Monitoring drift: Detecting when fine-tuned models need retraining
While foundation models like GPT-4 and Llama 3 offer impressive capabilities, they often lack domain-specific knowledge or tone alignment with company communications. Fine-tuning solves this problem, but implementing a reliable, production-grade fine-tuning workflow remains challenging for most teams.
The stakes are high: Gartner reports that 78% of organizations attempting to deploy LLMs struggle with inconsistent results and limited reproducibility, while McKinsey estimates potential value of $200-500 billion annually for companies that successfully implement domain-specific LLMs.
The ZenML + OpenPipe Solution
The ZenML-OpenPipe integration addresses these challenges by combining:
- ZenML's production-grade MLOps orchestration: Pipeline tracking, artifact lineage, and deployment automation
- OpenPipe's specialized LLM fine-tuning capabilities: Optimized training processes for various foundation models
This integration enables data scientists and ML engineers to:
- Build reproducible fine-tuning pipelines that can be shared across teams
- Track all datasets, experiments, and models with complete lineage
- Deploy fine-tuned models to production with confidence
- Schedule recurring fine-tuning jobs as data evolves
A key advantage of this integration is that OpenPipe automatically deploys your fine-tuned models as soon as training completes, making them immediately available via API. When you run the pipeline again with new data, your model is automatically retrained and redeployed, ensuring your production model always reflects your latest data.
Building a Fine-Tuning Pipeline
Let’s examine the core components of an LLM fine-tuning pipeline built with ZenML and OpenPipe.
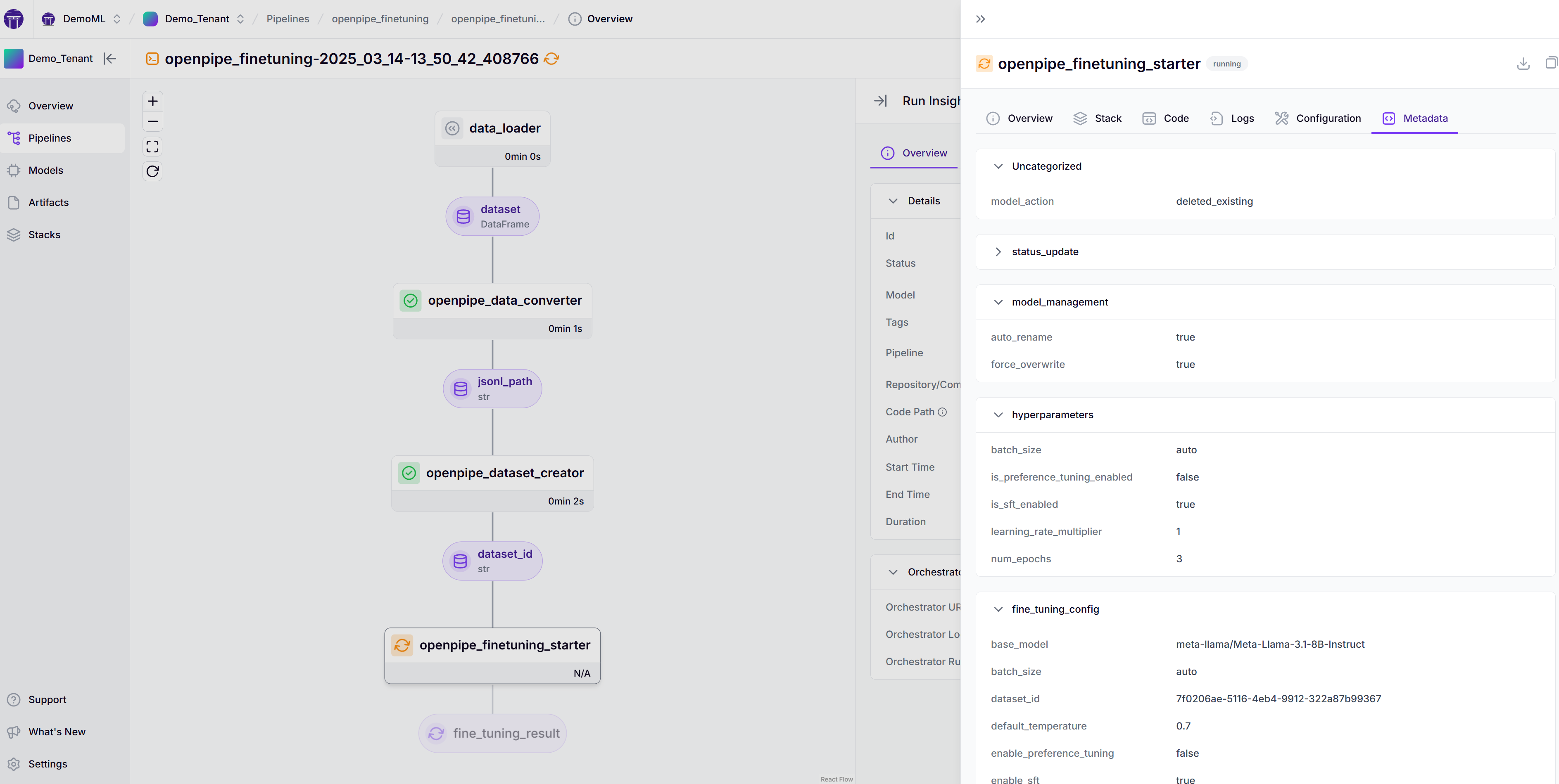
The Pipeline Architecture
The integration provides a modular pipeline architecture that handles the end-to-end fine-tuning process:
@pipeline
def openpipe_finetuning(
# Data parameters
data_source: str = "toy",
system_prompt: str = "You are a helpful assistant",
# OpenPipe parameters
model_name: str = "customer_support_assistant",
base_model: str = "meta-llama/Meta-Llama-3.1-8B-Instruct",
# Training parameters
enable_sft: bool = True,
num_epochs: int = 3,
learning_rate_multiplier: float = 1.0,
batch_size: str = "auto",
):
"""Fine-tune an LLM using OpenPipe with ZenML orchestration."""
# Load and prepare the data
data = data_loader(data_source=data_source, sample_size=30)
# Convert to OpenPipe format with system prompt
jsonl_path = openpipe_data_converter(
data=data,
system_prompt=system_prompt,
metadata_columns=["product"]
)
# Create OpenPipe dataset
dataset_id = openpipe_dataset_creator(
jsonl_path=jsonl_path,
dataset_name="customer_support_dataset",
)
# Start fine-tuning job
model_result = openpipe_finetuning_starter(
dataset_id=dataset_id,
model_name=model_name,
base_model=base_model,
enable_sft=enable_sft,
num_epochs=num_epochs,
learning_rate_multiplier=learning_rate_multiplier,
batch_size=batch_size,
)
return model_resultThis pipeline architecture provides several key advantages:
- Modular design: Each step handles a specific part of the workflow
- Parameter customization: Easily adjust training parameters based on your needs
- Comprehensive tracking: All artifacts and parameters are tracked automatically
- Reproducibility: Run the same pipeline with different parameters for comparison
For more details on building custom pipelines, check out the ZenML pipeline documentation.
Data Preparation Made Simple
One of the most challenging aspects of LLM fine-tuning is preparing the training data in the correct format. The openpipe_data_converter step handles this automatically:
@step
def openpipe_data_converter(
data: pd.DataFrame,
system_prompt: str = "You are a helpful assistant",
user_column: str = "question",
assistant_column: str = "answer",
split_ratio: float = 0.9,
metadata_columns: Optional[List[str]] = None,
) -> Annotated[str, "jsonl_path"]:
"""Convert data to OpenPipe JSONL format for fine-tuning."""
# Log configuration for tracking
log_metadata(
metadata={
"configuration": {
"system_prompt": system_prompt,
"user_column": user_column,
"assistant_column": assistant_column,
"split_ratio": split_ratio,
},
"data_stats": {
"dataset_shape": f"{data.shape[0]} rows × {data.shape[1]} columns"
}
}
)
# Transform dataframe to JSONL format
jsonl_data = []
for i, row in data.iterrows():
# Create example with system prompt, user input, and assistant response
entry = {
"messages": [
{"role": "system", "content": system_prompt},
{"role": "user", "content": str(row[user_column])},
{"role": "assistant", "content": str(row[assistant_column])},
],
"split": "TRAIN" if i < len(data) * split_ratio else "TEST",
}
# Add metadata if specified
if metadata_columns:
metadata = {}
for col in metadata_columns:
if col in row:
metadata[col] = str(row[col])
if metadata:
entry["metadata"] = metadata
jsonl_data.append(entry)
# Write to file and return path
output_path = "openpipe_data.jsonl"
with open(output_path, "w") as f:
for entry in jsonl_data:
f.write(json.dumps(entry) + "\n")
return output_pathThis step transforms your raw data (CSV or DataFrame) into the specialized JSONL format required by OpenPipe, handling:
- Formatting training examples with proper role assignments
- Splitting data into training and testing sets
- Applying system prompts consistently
- Preserving important metadata for analysis
For more information on OpenPipe’s data format requirements, visit their dataset documentation.
Practical Implementation
Let’s walk through a real-world implementation of fine-tuning a customer support assistant model.
Case Study: RapidTech’s Customer Support Automation
RapidTech, a fictional SaaS company, needed to fine-tune an LLM to handle customer support queries about their products. Their requirements included:
- Training on 5,000+ historical customer support conversations
- Regular retraining as new product features were released
- Consistent performance with company voice and product knowledge
- Cost-effective inference for high-volume support queries
Implementation Approach
We prepare the CSV training data with three key columns:
question: Customer queriesanswer: Agent responsesproduct: The product category (for metadata)
Next, we set up the ZenML pipeline to handle the end-to-end process:
# Set up environment
export OPENPIPE_API_KEY=opk-your-api-key
# Run the fine-tuning pipeline
python run.py \
--data-source=support_conversations.csv \
--system-prompt="You are a helpful customer support assistant for RapidTech products." \
--model-name=rapidtech_support_assistant \
--base-model=meta-llama/Meta-Llama-3.1-8B-Instruct \
--num-epochs=5 \
--metadata-columns=productThe implementation follows OpenPipe’s fine-tuning best practices while leveraging ZenML’s orchestration capabilities.
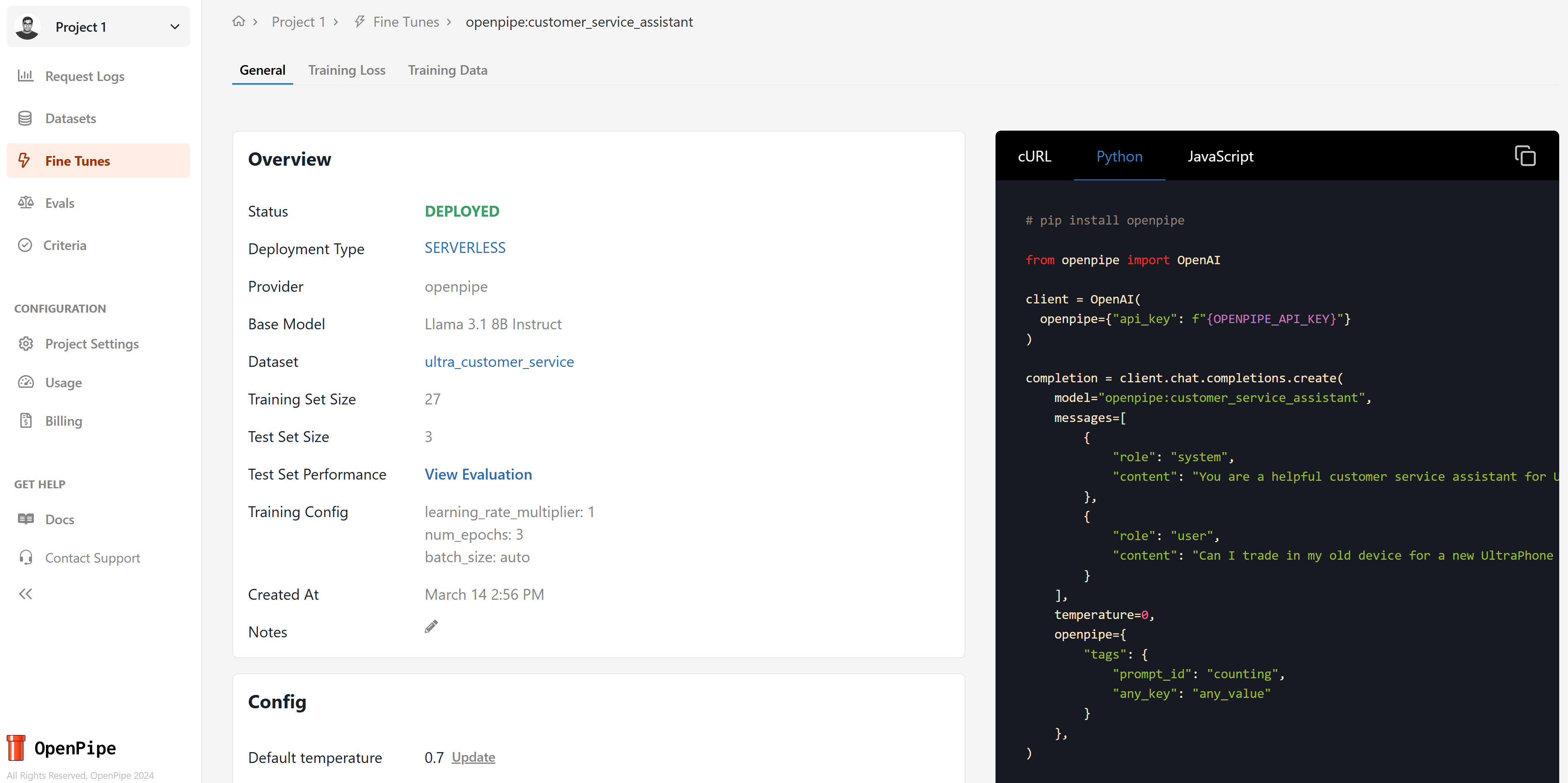
Using Your Deployed Model
Once the fine-tuning process completes, OpenPipe automatically deploys your model and makes it available through their API. You can immediately start using your fine-tuned model with a simple curl request:
curl https://api.openpipe.ai/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer opk-your-api-key" \
-d '{
"model": "rapidtech_support_assistant",
"messages": [
{"role": "system", "content": "You are a helpful customer support assistant for RapidTech products."},
{"role": "user", "content": "I need to reset my password for AccountManager"}
],
"temperature": 0.7
}'For Python applications, you can use the OpenPipe Python SDK, which follows the OpenAI SDK pattern for seamless integration:
# pip install openpipe
from openpipe import OpenAI
client = OpenAI(
openpipe={"api_key": "opk-your-api-key"}
)
completion = client.chat.completions.create(
model="openpipe:rapidtech_support_assistant",
messages=[
{
"role": "system",
"content": "You are a helpful customer service assistant for RapidTech products."
},
{
"role": "user",
"content": "Can I trade in my old device for a new RapidTech Pro?"
}
],
temperature=0,
openpipe={
"tags": {
"prompt_id": "customer_query",
"application": "support_portal"
}
},
)
print(completion.choices[0].message)This SDK approach is particularly useful for integrating with existing applications or services, and it supports tagging your requests for analytics and monitoring.
This immediate deployment capability eliminates the need for manual model deployment, allowing you to test and integrate your custom model right away.
Automated Redeployment with New Data
When product information changes or you collect new training data, simply run the pipeline again:
python run.py \
--data-source=updated_support_conversations.csv \
--model-name=rapidtech_support_assistant \
--force-overwrite=TrueOpenPipe will automatically retrain and redeploy your model with the updated data, ensuring your production model always reflects the latest information and examples. This seamless redeployment process makes it easy to keep your models up to date without manual intervention.
Performance Metrics and Cost Analysis
The fine-tuned model demonstrates:
- Better domain knowledge: Correctly answering questions about RapidTech products
- More relevant responses: Directly addressing customer concerns
- Faster responses: No need for external knowledge lookups
- Lower cost: Smaller, fine-tuned model vs. larger foundation model
These results align with the broader industry findings documented in ZenML’s LLMOps Database.
Data Management for Fine-Tuning
Effective data management is critical for successful LLM fine-tuning. The ZenML-OpenPipe integration makes this process painless through automated tracking.
Handling Different Data Sources
The pipeline supports multiple data sources:
# Built-in toy dataset
python run.py
# Custom CSV file
python run.py --data-source=path/to/data.csv
# Custom column names
python run.py --data-source=path/to/data.csv --user-column=prompt --assistant-column=completionBehind the scenes, the pipeline converts your data to the required JSONL format:
{
"messages": [
{"role": "system", "content": "You are a helpful customer service assistant for RapidTech products."},
{"role": "user", "content": "How do I reset my account password?"},
{"role": "assistant", "content": "To reset your password, go to the login page and click 'Forgot Password'. Follow the instructions sent to your email."}
],
"split": "TRAIN",
"metadata": {"product": "AccountManager"}
}For more details on OpenPipe’s JSONL format requirements, refer to their data preparation documentation.
Data Quality Monitoring
The pipeline logs detailed metadata about your training data:
log_metadata(
metadata={
"output_stats": {
"examples_count": len(jsonl_data),
"train_examples": train_count,
"test_examples": test_count,
"train_test_ratio": f"{train_count}:{test_count}"
}
}
)This information is accessible in the ZenML dashboard, allowing you to:
- Track data distribution across different pipeline runs
- Compare model performance against data quality metrics
- Detect potential data drift requiring model retraining
Learn more about ZenML’s metadata tracking in their documentation.
Monitoring and Reproducibility
One of the most powerful aspects of this integration is the comprehensive monitoring capabilities.
Tracking Fine-Tuning Progress
The openpipe_finetuning_starter step logs detailed information throughout the training process:
# Track status changes
if not status_history or status_history[-1] != status:
status_history.append(status)
log_metadata(
metadata={
"status_update": {
"status": status,
"time": datetime.datetime.now().isoformat()
}
}
)
# Log hyperparameters when available
hyperparams = model_info.openpipe.hyperparameters
if hyperparams and not result.get("logged_hyperparams"):
log_metadata(metadata={"hyperparameters": hyperparams})This provides a real-time view of:
- Training status and progress
- Model hyperparameters
- Error messages or warnings
- Time spent in each training phase
Continuous Model Improvement
A key advantage of the ZenML-OpenPipe integration is the ability to implement a continuous improvement cycle for your fine-tuned models:
- Initial training: Fine-tune a model on your current dataset
- Production deployment: Automatically handled by OpenPipe
- Feedback collection: Gather new examples and user interactions
- Dataset augmentation: Add new examples to your training data
- Retraining and redeployment: Run the pipeline again to update the model
With each iteration, both the dataset and model quality improve, creating a virtuous cycle of continuous enhancement. Since OpenPipe automatically redeploys your model with each training run, new capabilities are immediately available in production without additional deployment steps.
Check out OpenPipe’s model monitoring documentation for more information about monitoring your fine-tuned models in production.
Deployment on ZenML Stacks
The integration can be deployed on any infrastructure stack supported by ZenML:
This enables powerful MLOps workflows:
- Automated retraining: Schedule regular fine-tuning runs
- Distributed execution: Run on Kubernetes, Vertex AI, or your preferred platform
- Scaling resources: Allocate appropriate compute for larger datasets
- Environment standardization: Ensure consistent execution environments
Key Takeaways
From implementing this integration with multiple customers, several key insights emerged:
- Fine-tuning beats prompting for domain specificity – Even the best prompts can't match a well-fine-tuned model's domain knowledge and consistency.
- Reproducibility is crucial – Tracking every parameter, dataset, and training run enables systematic improvement over time.
- Data quality matters more than quantity – Smaller, high-quality datasets often outperform larger but noisy datasets.
- Automation reduces operational overhead – Scheduled pipelines eliminate manual steps and ensure timely model updates.
- Metadata tracking enables governance – Complete lineage from data to model deployment satisfies compliance requirements.
- Automatic deployment accelerates time-to-value – With OpenPipe's instant deployment, fine-tuned models are immediately usable via API without additional DevOps work.
Next Steps
For teams looking to implement LLM fine-tuning in production, we recommend:
- Start with a clear use case where domain knowledge provides clear value
- Collect high-quality examples that represent your desired outputs
- Set up the ZenML-OpenPipe integration to manage your fine-tuning workflow
- Iterate based on metrics to improve model performance over time
- Implement continuous monitoring to detect when retraining is needed
With LLMs becoming a critical part of business applications, having a reliable, reproducible fine-tuning workflow isn’t just convenient—it’s essential for maintaining competitive advantage and ensuring consistent performance.
The combination of ZenML’s robust MLOps capabilities and OpenPipe’s fine-tuning expertise provides exactly that: a production-grade solution for teams serious about deploying custom LLMs at scale.
Ready to get started? Check out the ZenML-OpenPipe repository or join the ZenML Slack community for personalized guidance.