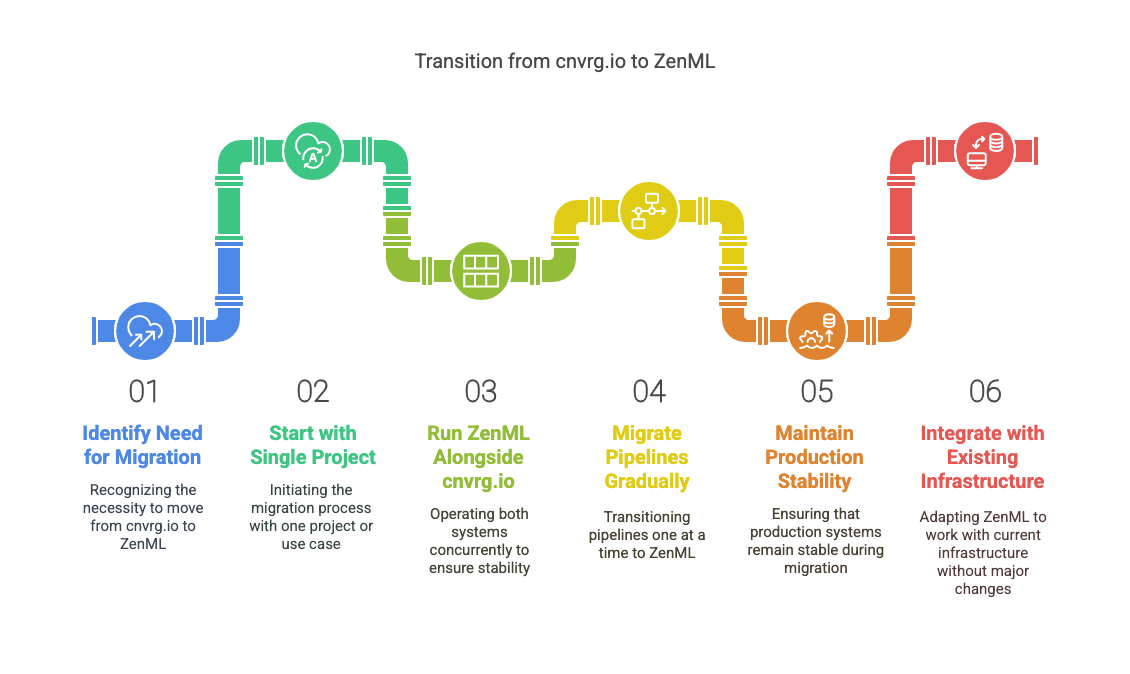
On this page
Let’s start with a reality check that might feel uncomfortably familiar. In 2024, where does 90% of your model iteration history actually live?
- Jupyter notebooks named "final_v3_REALLY_FINAL.ipynb"
- Random experiment runs with commit hashes that don't exist anymore
- That one CSV your colleague sent over Slack last month
- Your browser history because you forgot to save the tensorboard URL
Sound familiar? You’re not alone. While the MLOps ecosystem offers countless tools for experiment tracking, many teams still struggle with these basic challenges. Here’s why: We’ve been treating experiment tracking as a tooling problem when it’s fundamentally a workflow problem.
The Three Deadly Sins of ML Experiment Tracking
Before we dive into solutions, let’s acknowledge the workflow mistakes that plague even well-equipped teams:
- Running Experiments Before Defining What We're Measuring
- We jump into training without clear success criteria
- Metrics get added as afterthoughts
- Different team members track different metrics
- Not Versioning the Data
- Test sets evolve without documentation
- Benchmark datasets change between experiments
- No clear record of data preprocessing steps
- Assuming We'll "Remember the Important Details"
- Critical hyperparameters go unlogged
- Environment configurations are lost
- Model architecture decisions remain undocumented
A Workflow-First Approach to ML Experiment Tracking
Pre-Experiment Documentation
Before any code is written or models are trained, teams must complete an experiment definition document that includes:
- Primary and secondary metrics with specific thresholds
- Clear definition of what constitutes a "better" model
- Required comparison metrics for A/B testing
- Stakeholder sign-off on success criteria
The key is making this documentation a required gateway - no training runs begin without it. This can be as simple as a shared template that must be filled out, or as robust as a formal approval process.
Data Versioning Protocol
Establish a systematic approach to data management:
- Create a data registry that tracks every version of training and evaluation datasets
- Document all preprocessing steps in a versioned configuration file
- Maintain a changelog for data modifications
- Store fixed evaluation sets with unique identifiers
- Create automated checks that prevent training without data versioning information
The focus here is on making data versioning automatic and mandatory rather than optional.
Experiment Metadata System
Implement a structured logging system that requires:
- Mandatory recording of environment details before experiments start
- Standard templates for hyperparameter documentation
- Automated capture of all model architecture decisions
- Regular experiment summary reports
- Team review sessions to ensure important context is captured
The key innovation here is shifting from “remember to log” to “unable to proceed without logging.”
This workflow creates natural stopping points where teams must properly document and version before proceeding, making good practices the path of least resistance rather than an afterthought.
Building a Better Workflow: Using ZenML and Neptune
A practical implementation to the above can be seen with the powerful combination of ZenML and Neptune comes in. We’ll explore how integrating these two tools can streamline your ML workflows and provide increased visibility into your experiments.
ZenML is an extensible, open-source MLOps framework designed to create production-ready machine learning pipelines. It offers a simple, intuitive API that allows you to define your ML workflows as a series of steps, making it easy to manage complex pipelines.
Neptune is an experiment tracker built for large-scale model training. It allows AI researchers to monitor their model training in real-time, visualize and compare experiments, and collaborate on them with a team.
When combined, these tools offer a robust solution for managing your entire ML lifecycle, from experimentation to production.
A Real-World Example: Fine-Tuning a Language Model
Let’s dive into a practical example of how ZenML and Neptune can work together to enhance your ML workflows. We’ll create a pipeline for fine-tuning a language model, tracking the entire process with Neptune.
Setting the Stage: Environment Setup
First, let’s get our environment ready:
pip install "zenml[server]"
zenml integration install neptune huggingface -yNext, we’ll configure our Neptune credentials using ZenML secrets:
zenml secret create neptune_secret --api_token=<YOUR_NEPTUNE_API_TOKEN>Now, let’s register the Neptune experiment tracker in our ZenML stack:
zenml experiment-tracker register neptune_tracker \\
--flavor=neptune \\
--project=<YOUR_NEPTUNE_PROJECT> \\
--api_token={{neptune_secret.api_token}}
zenml stack register neptune_stack -e neptune_tracker ... --set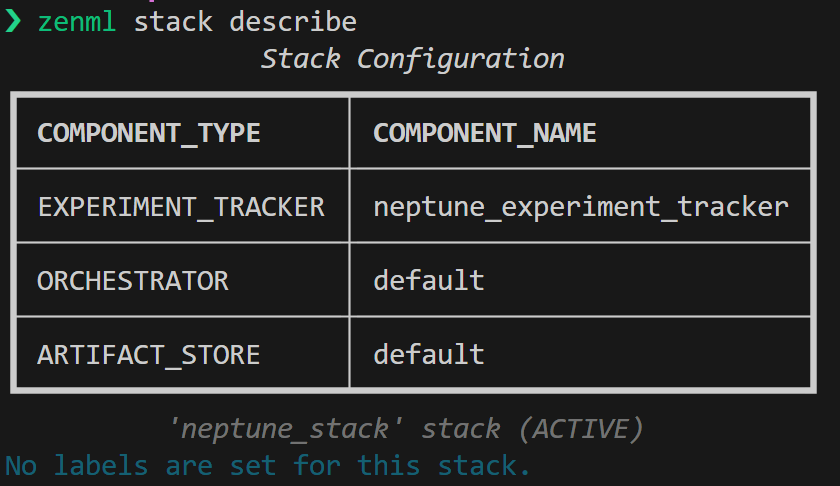
Architecting the Pipeline
Here’s our ZenML pipeline for fine-tuning a DistilBERT model:
from typing import Tuple
from zenml import pipeline, step
from zenml.integrations.neptune.experiment_trackers import NeptuneExperimentTracker
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
Trainer,
TrainingArguments,
DistilBertForSequenceClassification,
)
import os
from datasets import load_dataset, Dataset
import numpy as np
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
from zenml.client import Client
from zenml.integrations.neptune.experiment_trackers import NeptuneExperimentTracker
# Get the experiment tracker from the active stack
experiment_tracker: NeptuneExperimentTracker = Client().active_stack.experiment_tracker
# Set the environment variables for Neptune
os.environ["WANDB_DISABLED"] = "true"
@step
def prepare_data() -> Tuple[Dataset, Dataset]:
dataset = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
return (
tokenized_datasets["train"].shuffle(seed=42).select(range(1000)),
tokenized_datasets["test"].shuffle(seed=42).select(range(100)),
)
@step(experiment_tracker="neptune_experiment_tracker", enable_cache=False)
def train_model(
train_dataset: Dataset, eval_dataset: Dataset
) -> DistilBertForSequenceClassification:
model = AutoModelForSequenceClassification.from_pretrained(
"distilbert-base-uncased", num_labels=2
)
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
report_to=["neptune"],
)
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
precision, recall, f1, _ = precision_recall_fscore_support(
labels, predictions, average="binary"
)
acc = accuracy_score(labels, predictions)
return {"accuracy": acc, "f1": f1, "precision": precision, "recall": recall}
# Get the Neptune run and log it to the Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
return model
@pipeline
def fine_tuning_pipeline():
train_dataset, eval_dataset = prepare_data()
model = train_model(train_dataset, eval_dataset)
if __name__ == "__main__":
# Run the pipeline
fine_tuning_pipeline()This pipeline accomplishes the following:
- Prepares a subset of the IMDB dataset for sentiment analysis.
- Fine-tunes a DistilBERT model on this dataset.
- Evaluates the model and logs the metrics to Neptune.
Launching the Pipeline and Exploring Results
Now, let’s set our pipeline in motion:
fine_tuning_pipeline()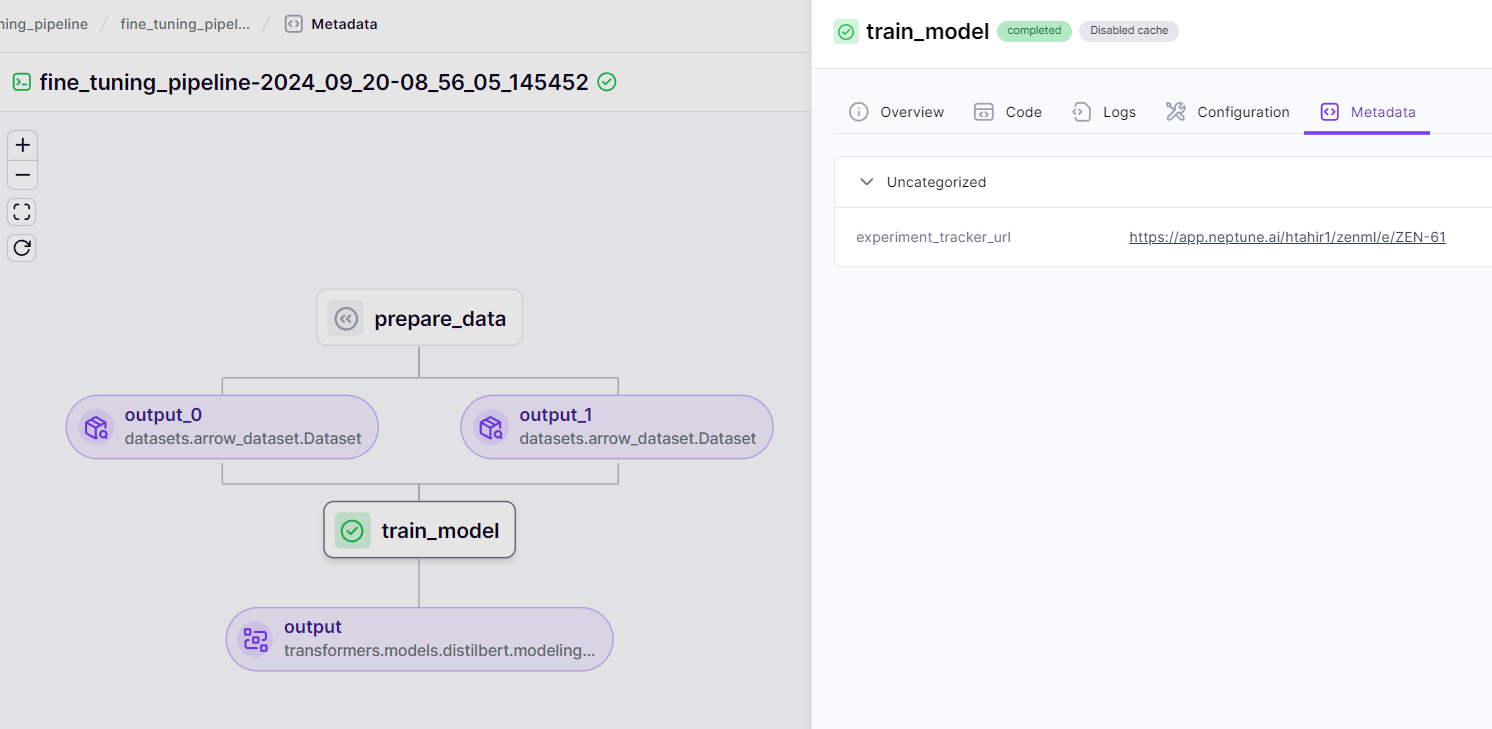
As the pipeline runs, ZenML automatically creates Neptune experiments for each step where tracking is enabled. You can view these experiments in the Neptune UI by visiting https://app.neptune.ai/YOUR_WORKSPACE/YOUR_PROJECT/experiments.
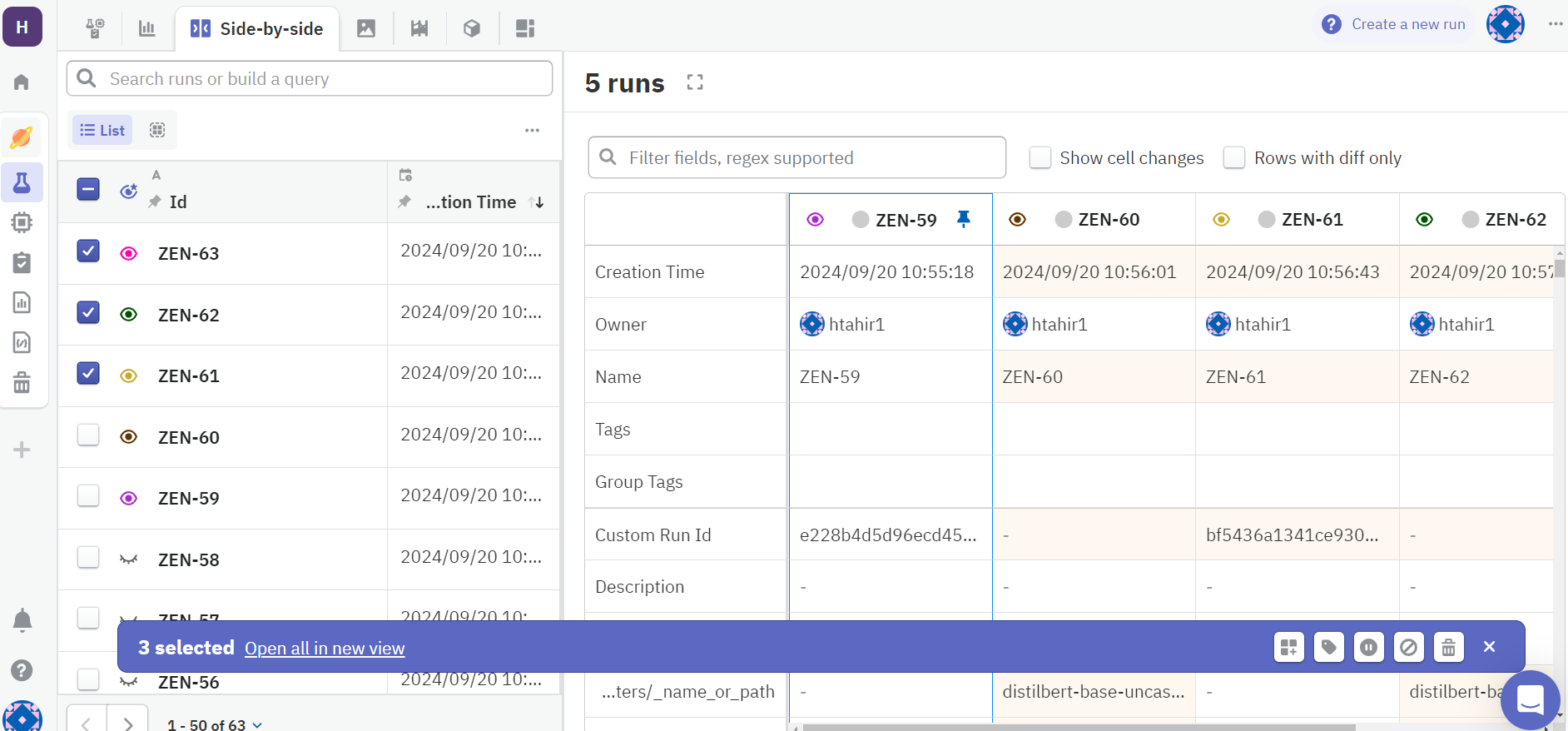
In the Neptune UI, you’ll have access to a wealth of information:
- Detailed metrics for your fine-tuning run, including accuracy, F1 score, precision, and recall.
- Comparisons between different runs of your pipeline to identify improvements or regressions.
- Training curves to visualize how your model's performance evolved during training.
- Collaboration tools to share results with team members for joint analysis and decision-making.
Beyond Tools: Building a Culture of Experiment Tracking
Remember:
- Tools enable good practices; they don't create them
- Start with workflow design, then choose supporting tools
- Create processes that make good practices the path of least resistance
Conclusion: Fix Your Workflow First
While tools like ZenML and Neptune are powerful allies in ML development, they’re most effective when supporting well-designed workflows. Before diving into tool selection:
- Define clear tracking requirements
- Establish data versioning protocols
- Create explicit documentation requirements
- Build processes that enforce good practices
The best experiment tracking setup is the one your team will actually use consistently. Start with workflow, and let the tools serve your process - not the other way around.
Ready to improve your ML experiment tracking? Start by examining your workflow, then let tools like ZenML and Neptune help you implement and enforce good practices.