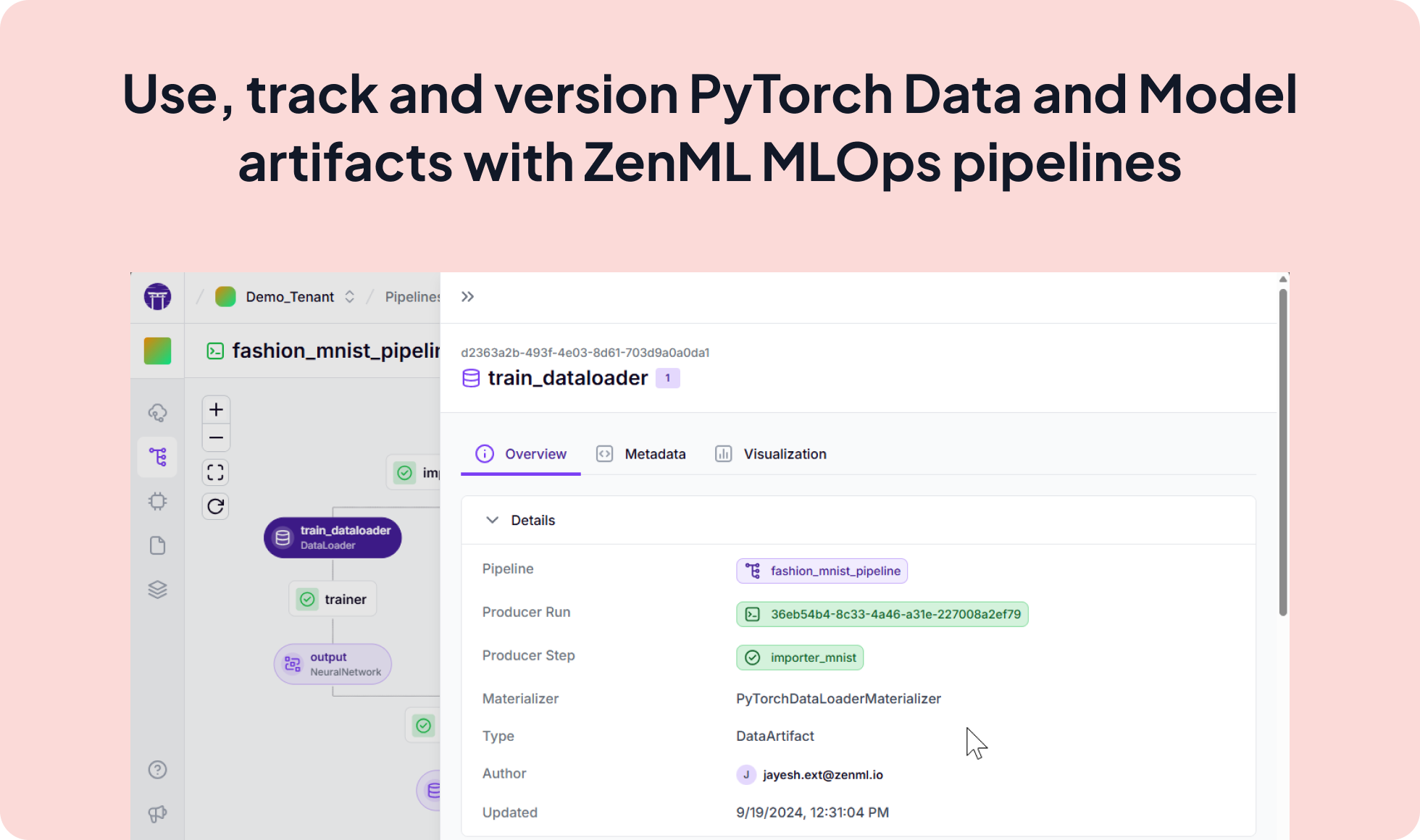
Seamlessly integrate PyTorch, a powerful deep learning framework, with ZenML to streamline your model development and experimentation process. By leveraging ZenML's model-agnostic pipelines and PyTorch's flexibility, you can rapidly iterate on models, track experiments, and deploy production-ready solutions with ease.
from zenml import pipeline
from zenml.integrations.constants import PYTORCH
from torch import nn
from torch.utils.data import DataLoader
@step(enable_cache=False)
def trainer(train_dataloader: DataLoader) -> nn.Module:
"""Trains on the train dataloader."""
model = NeuralNetwork().to(DEVICE) # NeuralNetwork extends nn.Module
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
size = len(train_dataloader.dataset)
model.train()
for batch, (X, y) in enumerate(train_dataloader):
X, y = X.to(DEVICE), y.to(DEVICE)
# Compute prediction error
pred = model(X)
loss = loss_fn(pred, y)
# Backpropagation
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 100 == 0:
loss, current = loss.item(), batch * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
return model
@pipeline()
def fashion_mnist_pipeline():
"""Link all the steps and artifacts together."""
train_dataloader, test_dataloader = importer_mnist()
model = trainer(train_dataloader)
evaluator(test_dataloader=test_dataloader, model=model)Expand your ML pipelines with more than 50 ZenML Integrations
