LlamaIndex lets you build function agents that call multiple tools and often run asynchronously; integrating it with ZenML executes those agents inside reproducible pipelines with artifact lineage, observability, and a clean path from local development to production.
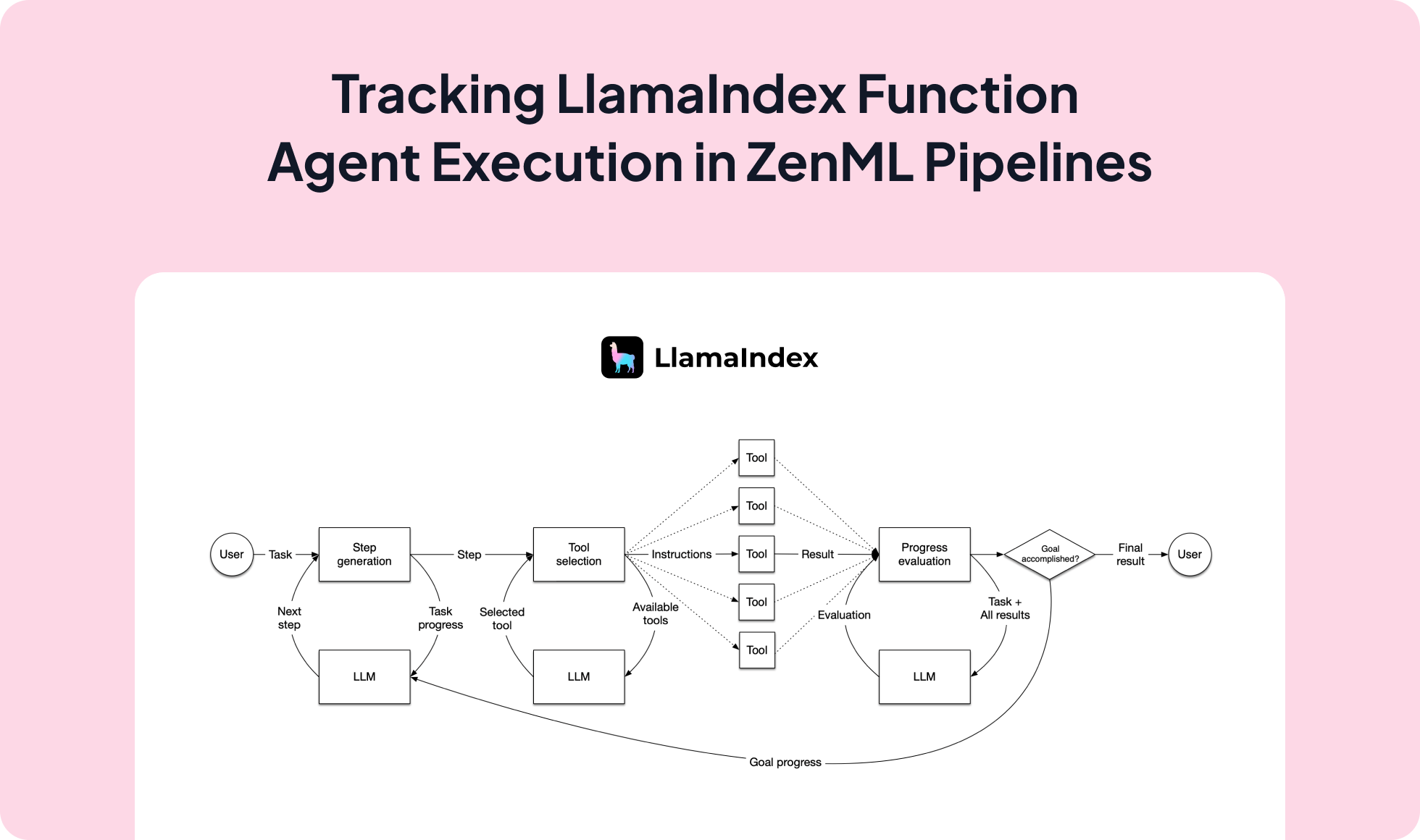
agent.run(...) for non-blocking workflows.from zenml import ExternalArtifact, pipeline, step
from agent import agent # LlamaIndex function agent with tools
@step
def run_llamaindex(query: str) -> str:
# LlamaIndex agent.run is async; await it inside the step
import asyncio
async def _run():
return await agent.run(query)
resp = asyncio.run(_run())
return str(getattr(resp, "response", resp))
@pipeline
def llamaindex_agent_pipeline() -> str:
q = ExternalArtifact(
value="What's the weather in New York and calculate a 15% tip for $50?"
)
return run_llamaindex(q.value)
if __name__ == "__main__":
print(llamaindex_agent_pipeline())Expand your ML pipelines with more than 50 ZenML Integrations
