Integrate Pigeon, a lightweight and intuitive data annotation tool, with ZenML to effortlessly label your datasets directly within Jupyter notebooks. This integration simplifies the annotation process for text classification, image classification, and text captioning tasks, making it ideal for quick labeling during the exploratory phase of your ML projects.
annotator dataset commands to easily list, delete, and retrieve statistics for your annotated datasets.
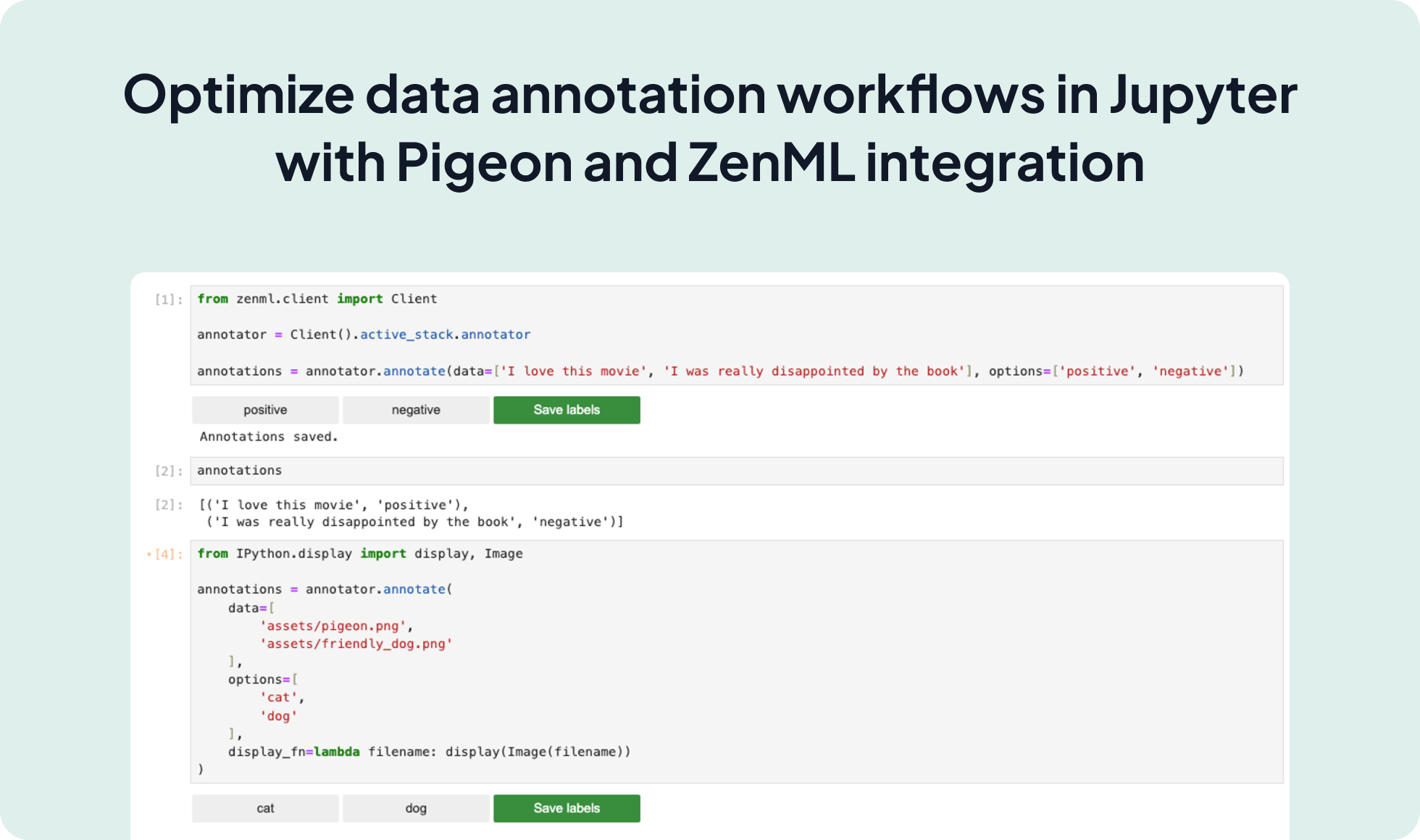
from zenml.client import Client
annotator = Client().active_stack.annotator
annotations = annotator.launch(
data=[
'This movie was fantastic!',
'I was disappointed by the ending of the book.'
],
options=[
'positive',
'negative'
]
)
Expand your ML pipelines with more than 50 ZenML Integrations
